理论八:如何用迪米特法则(LOD)实现“高内聚、松耦合”?
- 什么是“高内聚、低耦合”?
- 如何利用迪米特法则实现“高内聚、松耦合”
- 有哪些代码设计明显违背迪米特法则的?对此又该如何重构?
何为“高内聚,松耦合”?
- “高内聚、松耦合”是一个非常重要的设计思想,能够有效地提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。很多之前的设计原则都是以实现这个原则为目的,比如SRP,基于接口而非实现编程。
- 它的适用范围也很广泛:系统、模块、类甚至是函数,也可应用到不同的开发场景中:微服务、框架、组件、类库等。
- 以类举例,高内聚指导类本身的设计,低耦合用来指导类之间的依赖关系的设计。
什么是高内聚?
所谓高内聚,就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一个类。相近的功能往往会被同时修改,放在同一个类,修改比较集中,代码容易维护。-> SRP:我感觉你在说我。
什么是松耦合?
松耦合,在代码中类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个的改动不会或者很少导致依赖类的代码的改动。例如之前的依赖注入、接口隔离、基于接口而非实现编程,都是为了实现松耦合。
内聚和耦合的关系
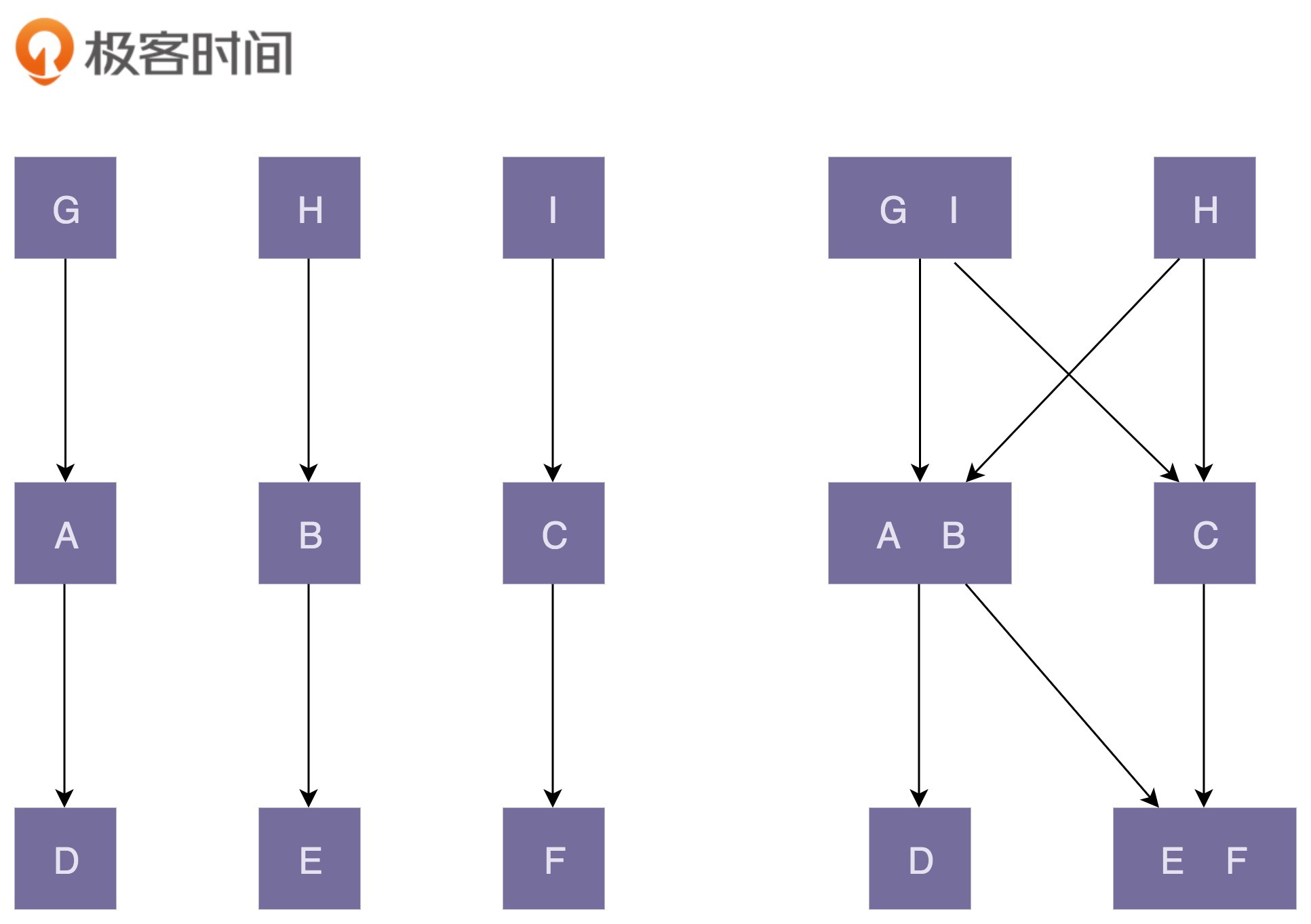
- 左边的部分就是高内聚低耦合。类的粒度比较小,职责比较单一。相近的功能放在一个类中,不想进的功能被分割到多个类中。类更加独立,代码内聚性好。因为职责单一,所以每个类被依赖的类就比较少,耦合低。右边的图则相反。
迪米特法则(LOD)理论描述
-
Law of Demeter, LOD, The least Knowledge Principle
-
Each unit should have only limited knowledge about other units: only units "closely" related the current unit.
-
Or: Each unit should only talk to its friends; Don't talk to strangers.
- 每个模块只应该了解那些与他关系密切的模块的有限制是。或者说,每个模块只和自己的朋友“说话”,不和陌生人“说话”。
- 不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口(也即原则中提到的“有限知识”)。
-
理论解读与代码实战1
- “不该有直接依赖关系的类之间,不要有依赖”。 举个例子:这个例子实现了简化版的搜索引擎爬取网页的功能。代码中包含三个主要的类。其中,NetworkTransporter 类负责底层网络通信,根据请求获取数据;HtmlDownloader 类用来通过 URL 获取网页;Document 表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象:
public class NetworkTransporter { // 省略属性和其他方法... public Byte[] send(HtmlRequest htmlRequest) { //... } } public class HtmlDownloader { private NetworkTransporter transporter;//通过构造函数或IOC注入 public Html downloadHtml(String url) { Byte[] rawHtml = transporter.send(new HtmlRequest(url)); return new Html(rawHtml); } } public class Document { private Html html; private String url; public Document(String url) { this.url = url; HtmlDownloader downloader = new HtmlDownloader(); this.html = downloader.downloadHtml(url); } //... }
- 首先是NetworkTransporter类。作为底层通信类,应该尽可能通用,而不是只服务于下载HTML。所以不应该直接以来太具体的发送对象HtmlRequest。从这一点上讲,NetworkTransporter 类的设计违背迪米特法则,依赖了不该有直接依赖关系的 HtmlRequest 类。
- 对这个类进行重构可以参照一个思路:假如你现在要去商店买东西,你肯定不会直接把钱包给收银员,让收银员自己从里面拿钱,而是你从钱包里把钱拿出来交给收银员。这里的 HtmlRequest 对象就相当于钱包,HtmlRequest 里的 address 和 content 对象就相当于钱。我们应该把 address 和 content 交给 NetworkTransporter,而非是直接把 HtmlRequest 交给 NetworkTransporter。
public class NetworkTransporter { // 省略属性和其他方法... public Byte[] send(String address, Byte[] data) { //... } }
- HtmlDownloader类。设计没问题,send函数要相应修改下:
public class HtmlDownloader { private NetworkTransporter transporter;//通过构造函数或IOC注入 // HtmlDownloader这里也要有相应的修改 public Html downloadHtml(String url) { HtmlRequest htmlRequest = new HtmlRequest(url); Byte[] rawHtml = transporter.send( htmlRequest.getAddress(), htmlRequest.getContent().getBytes()); return new Html(rawHtml); } }
- Document类。
- 构造函数中
downloader.downloadhtml()逻辑复杂,耗时长,不应该放在构造函数,影响代码的可测试性; HtmlDownloader对象在构造函数中new创建来的,违反了基于接口而非实现编程的设计思想,也会影响可测试性- 从业务上来讲,Document网页文档没必要依赖
HtmlDownloader类,违反了LOD。
- 构造函数中
- 重构这个Document类,通过一个工厂方法:
public class Document { private Html html; private String url; public Document(String url, Html html) { this.html = html; this.url = url; } //... } // 通过一个工厂方法来创建Document public class DocumentFactory { private HtmlDownloader downloader; public DocumentFactory(HtmlDownloader downloader) { this.downloader = downloader; } public Document createDocument(String url) { Html html = downloader.downloadHtml(url); return new Document(url, html); } }
从业务上来讲Document、HtmlDownloader都是独立的,但是在实现上Document需要用到HtmlDownloader提供的能力,这时候就增加一个工厂类,让工厂类来调用HtmlDownloader并且new Document,将两者完美解耦
理论解读与代码实战2
再看这个原则后半部分:有依赖关系的类之间,尽量只依赖必要的接口。还是结合一个例子:Serialization 类负责对象的序列化和反序列化。(这个例子在学习SRP也讲过)
public class Serialization { public String serialize(Object object) { String serializedResult = ...; //... return serializedResult; } public Object deserialize(String str) { Object deserializedResult = ...; //... return deserializedResult; } }
单独看这个Serialization类没什么问题,放进一定场景,那就有继续优化的空间。
假设在项目中,有的类只用到序列化,另一些只用到反序列化。那基于这个LOD的后半部分,只用到序列化的那部分类不应该也不需要依赖反序列化接口。
public class Serializer { public String serialize(Object object) { String serializedResult = ...; ... return serializedResult; } } public class Deserializer { public Object deserialize(String str) { Object deserializedResult = ...; ... return deserializedResult; } }
尽管拆分之后满足了LOD,但是违背了高内聚的设计思想。高内聚要求功能相近的功能放在一个类中,方便以后维护。
如果既要满足LOD,又要符合高内聚,该怎么设计?参考接口隔离原则的例子,可以设计成接口把序列化和反序列化,让Serielization类实现他们。既满足他们在同一个类中,又减少了使用类对于不同接口不必要的依赖。
public interface Serializable { String serialize(Object object); } public interface Deserializable { Object deserialize(String text); } public class Serialization implements Serializable, Deserializable { @Override public String serialize(Object object) { String serializedResult = ...; ... return serializedResult; } @Override public Object deserialize(String str) { Object deserializedResult = ...; ... return deserializedResult; } } public class DemoClass_1 { private Serializable serializer; public Demo(Serializable serializer) { this.serializer = serializer; } //... } public class DemoClass_2 { private Deserializable deserializer; public Demo(Deserializable deserializer) { this.deserializer = deserializer; } //... }
基于最小接口而非最大实现编程。
辩证思考与灵活运用
对于实战2,如果这是这么简单的使用,确实不必要过度设计和拆分。但是如果以后要添加更多功能对于序列化反序列化,比如:
public class Serializer { // 参看JSON的接口定义 public String serialize(Object object) { //... } public String serializeMap(Map map) { //... } public String serializeList(List list) { //... } public Object deserialize(String objectString) { //... } public Map deserializeMap(String mapString) { //... } public List deserializeList(String listString) { //... } }