背景
起因是某个刷题网站上有一份前四百题的分类顺序表,结果发现Chrome和Safari的插件都不能生成PDF文档完美的提取并显示这个列表。查看源代码发现好像符合一些规律,所以就想着用python自己写个小工具整理一下。
具体实现
基本分三步,1. 获取源码, 2. 文本处理, 3. 获取结果。 一步步说一下。
Step1 获取源码 可以选择用小爬虫爬取这个网页的源码,在爬取的时候就可以做一些过滤操作,获取相应的标签。因为我这个就很少量,本着省时省力的原则,我只接选择去原网页查看源代码。
Step2 文本处理 主要是对获取到的文本进一步处理,找到自己需要的信息并且观察。
<tr> <td>380</td> <td><a href="https://leetcode.com/problems/insert-delete-getrandom-o1/" target="_blank" class="text-link">Insert Delete GetRandom O(1)</a></td> <td><a href="/login" class="text-link">视频讲解</a></td> <td></td> </tr>
观察过后发现其实都是这个模式,所以上手!beautiful soup了解一下。
使用了beautiful soup的节点操作工具。这里涉及到DOM的知识(其实不懂也没事,只需要知道一个HTML页面是一个类似树形结构的文本组织)。
找到<tr>标签然后使用get_text()函数获取到他内部的文本。
Step3 获取结果 我只需要得到最后的列表即可,因为我要放在Markdown文件里给他加上一个Todo List标签,所以做了小小的处理。
最后记录一下源代码,因为篇幅有限,网页源代码将近一万行了,所以只截取几行代表直观感受一下。
from bs4 import BeautifulSoup html_doc = """ <tr> <td>78</td> <td><a href="https://leetcode.com/problems/subsets/description/" target="_blank" class="text-link">Subsets</a></td> <td><a href="/login" class="text-link">视频讲解</a></td> <td></td> </tr> <tr> <td>79</td> <td><a href="https://leetcode.com/problems/word-search/description/" target="_blank" class="text-link">Word Search</a></td> <td><a href="/login" class="text-link">视频讲解</a></td> <td></td> </tr> <tr> <td>80</td> <td><a href="https://leetcode.com/problems/remove-duplicates-from-sorted-array-ii/description/" target="_blank" class="text-link">Remove Duplicates from Sorted Array II</a></td> <td><a href="/login" class="text-link">视频讲解</a></td> <td></td> </tr> """ soup = BeautifulSoup(html_doc, 'html.parser') // parse source code of web page for tr in soup.find_all('tr'): // find_all the tr label text = tr.get_text() l = text.split('\n') // split by new line new_s = "- [ ] " + l[1] + " " + l[2] + " " + l[4] // get what I want, if (l[1][0] > '0' and l[1][0] < '9'): // filtering some invalid result print(new_s)
我得到的结果:
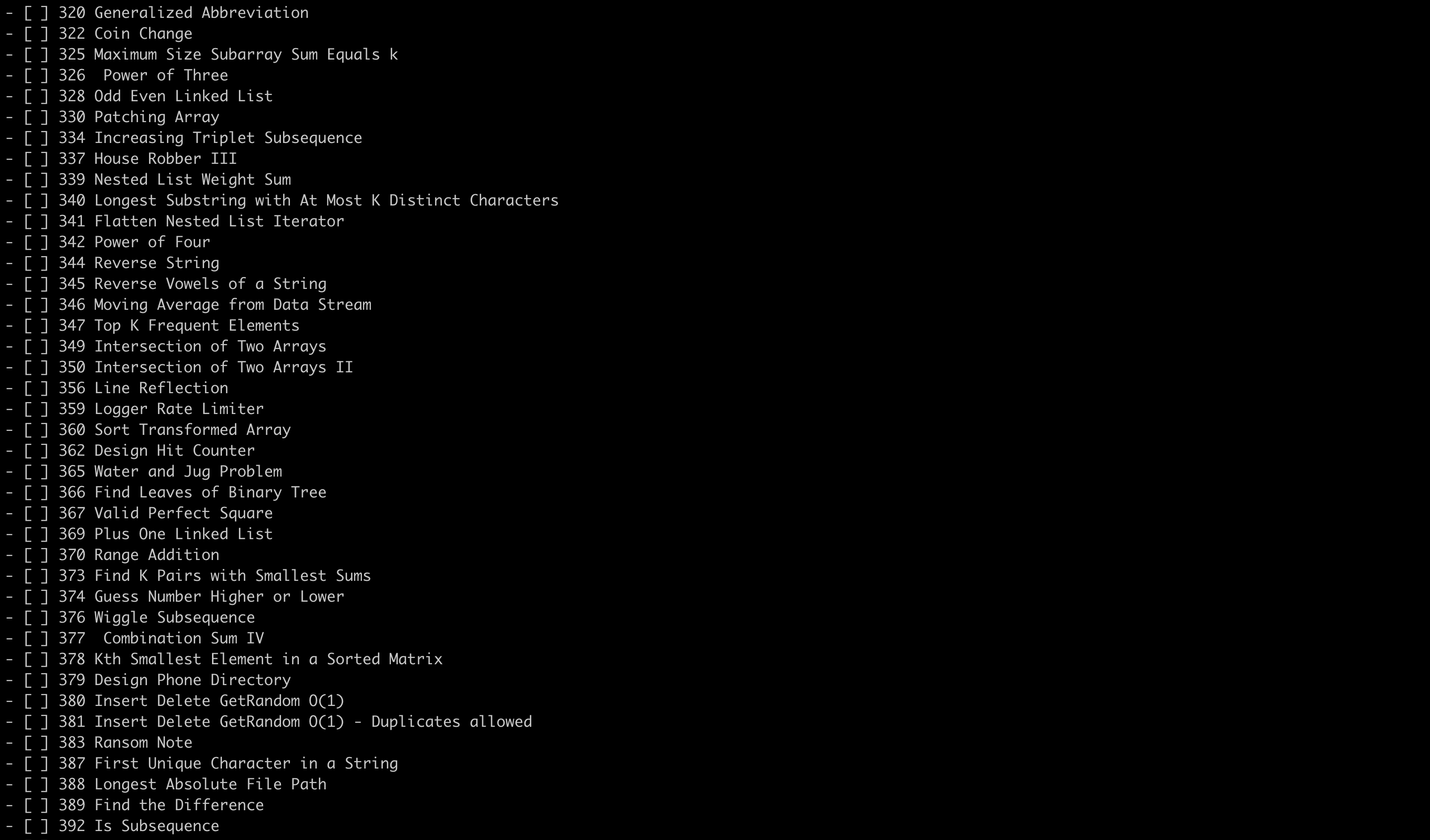
复制进去markdown编辑器:

后记
多动手来增加自己思考的机会和写代码的能力把。