Chapter1 - Reliable, Scalable and Maintainable application
This chapter introduces the terminology and approach we used in the book; and gives examples in a high level of these terminology(what and how to achieve)
- Data-intensive application is build from standard building blocks :
- Databases -> store data that can be used(read) again
- Caches -> speed up reads (remember the result of expensive operation )
- Search index -> allow users to filter or search by keyword
- Stream processing -> handle data asynchronously
- Batch processing -> periodically crunch a large amount of accumulated data
- These blocks are highly attracted and application engines don't need to implement a storage engine, they just use them.
- But databases have different characters, and we need to choose them based on the requirements. -> find the proper one.
- Things in common, what are the difference and how they achieve the characters.
Thinking about data systems
-
Many tools for data storage and processing have emerged in recent years.
- Kafka as a message queue with database-like durability guarantees
- Redis as a datastore can be used as message queues.
-
Many systems has increasing demands on a single tool with many functions
- Switching between tools by applications cold is less efficiently than one tools handle multiple tasks together.
-
In this book, three common concerns will be discussed :
- Reliability : system continue work correctly(performing the correct function at the desired level of performance) even in the face of adversity( hardware or software faults, and even human errors)
- Scalability: system grows(in data volume, traffic volume or complexity), there should be reasonably ways of dealing with that growth.
- Maintainability: New people can maintain and adopt the system productively.
Reliability
- Expected behaviors:
- Perform the function as user expected (functional reliability)
- Tolerate user making mistakes or use softwares in an unexpected way(bad behavior prevention reliability )
- Performance are good under an expected data load(performance reliability)
- Prevents unauthorized access and abuse (security reliability )
- What can effect reliability
- Fault -> system can cope with fault called fault tolerant or resilient
- 100% fault tolerate is impossible in reality
- Fault vs failure
- Fault is components diverting from its spec
- Failure: system stops providing required service
- Trigger faults deliberately -> can increase fault tolerance
- Netflix Chaos Monkey : randomly kill individual process without warning -> to test the system
- Better prevent than cure
- Security : if system are hacked, system are controlled or data are lost, this can be undone and cure can not be done.
- But in this book most are faults that can be cured.
Hardware Faults
- Examples in a datacenter
- Disk crash
- RAM faulty
- Power grid has a blockout
- Someone unplugs the wrong network cable
- Option1: redundancy -> good but cannot prevent totally
- Disk set up a RAID configuration(no fear of loss data in some degree)
- Server have dual power supplies and hot swappable CPUs
- Batteries and diesel generators for backup power
- Option2: fault tolerance techniques (as substitution or in addition to redundancy) -> operational advantage -> e.g. rolling upgrades
System Errors
- System errors are more like to be related compared with hardware errors.
- Examples
- A software bug that cause every instance of an application server to crash when given a bad input.
- A runaway process that uses up some shared resources.(A runaway process is a process that enters an infinite loop and spawns new processes.)
- A service that the system depends on that slows down/ or unresponsive or starts return corrupted responses.
- Cascading failures
- Reasons: The softwares are making some assumptions are true and these assumptions becomes false.
- Solution
- Thinking carefully when designing
- Testing
- Process isolation,
- Allow process crashing and restart
- Measuring and monitoring
Human Errors
- Approaches :
- Design carefully. e.g. abstractions, APIs and interfaces...
- Decouple the places that people making most mistake. e.g. sandbox env
- Test thoroughly at all levels; e.g. automation tests
- Allow quick and easy recovery: quick rollback and rollout new code gradually; provide tools that recompute data
- Detailed and clear monitoring. e.g. performance metrics and error rates -> telemetry
- Management practices and training
How important of Reliability?
- Cost, reputation and trust
- There are situations that we want to cut cost by sacrifice reliability
Scalability
- Attribute of how system coping with increasing load.
Describing load
-
Load has different meaning in terms of architecture
- Request per second to a web service
- Ratio of reads to write in a database
- The number of simultaneously active users in a chat room
- Hit rate on a cache
- ...
Something that's bottleneck
-
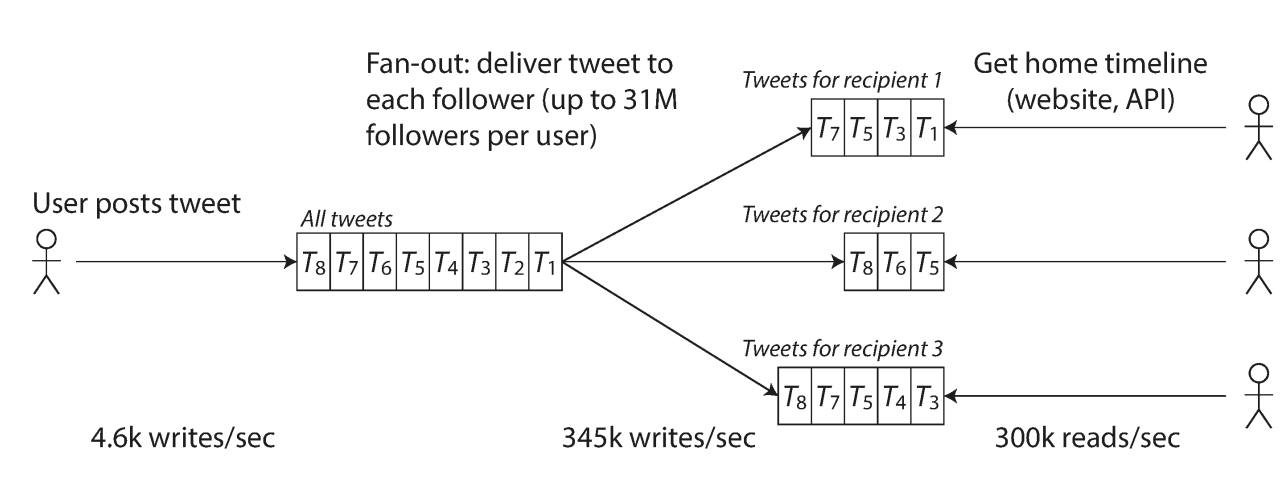
An example : twitter
- post tweet : a user can publish a new message to their followers (4.6k request/sec on average, over 12k request/sec at peak)
- Home timeline: a user can view tweets posted by the people they follow (300k request / sec)
-
Fan-out: one user follows many people and also is followed by many people.
-
Two ways of implementing the operations of twitter:
-
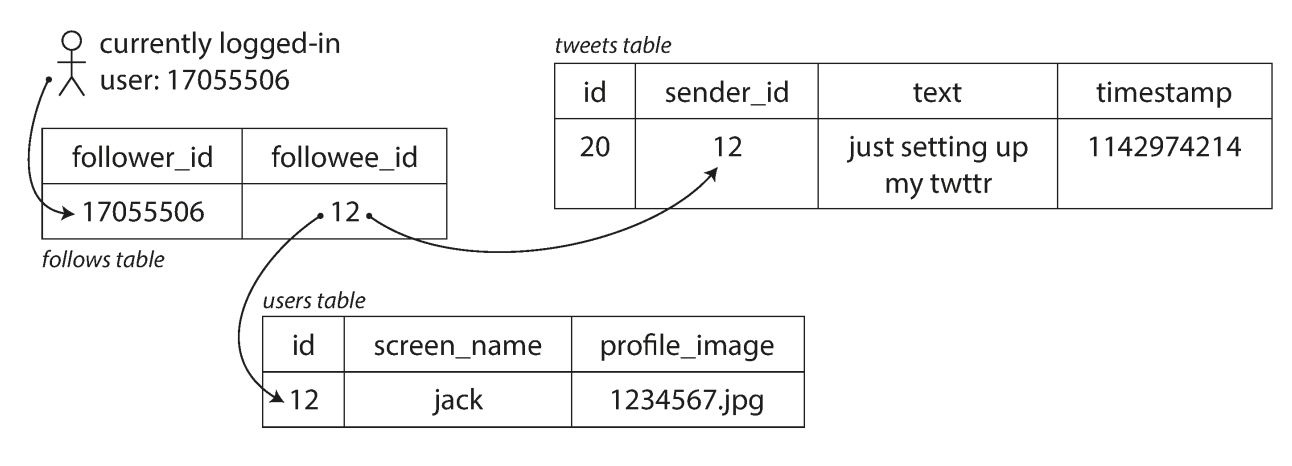
Posting tweet will insert a new tweet into a global collection of tweets. When a user request their home time, lok up all the people they follow and find all the tweets for each of those users, merge them(sorted by time).
-
-
sql SELECT tweets.*, users.* FROM tweets JOIN users ON tweets.sender_id = users.id JOIN follows ON follows.followee_id = users.id WHERE follows.follower_id = current_user
-
-
Maintain a cache for each users's home timeline. When a user posts a tweet, look up all the followers and insert their caches with the new tweet into their timeline cace. The read to home timeline is cheaper since all the result is pre- calculated.
-
-
Tweeter switch from approach 1 to 2 as the data load increasing -> since read is much more than write, so do some additional work in writing time is ok.
-
Approach 2 has a problem is that for celebrities, they have much more followers then others and if they post a tweets, there will be huge amount of writes -> whose overhead cannot be ignored(considering they are aiming for 5s target to finish home timeline load)
-
In the end they do a hybrid way: normal people approach 2 and celebrities are adopting approach 1 to avoid too much writes.
Describing performance
- With data load increasing, how is the performance affected ? Or how many system resources needed if you want to keep the performance not affected.
-
Batch processing (Hadoop): throughput is important (number of request can be processed per sec); total time for a database to run a job in a certain size; service response time in an online system
- Response vs latency: sometimes used as synonymously but have slight difference: response is for client , which include the time of processing and the time of transmission in the network; while the latency is the duration of a request to be handled.(in server side)
-
Single response in a system has no use; we need to think about the distribution of the response times overall.
- Same request to server can have different processing time due to data size;
- Even we assume they are equal, there are still variation due to random latency like: a GC, a page fault forcing read from disk; mechanical vibration in the server rack, context switch to a background process ...
- Average / mean is not good because it's not typical, you don't know how many sets actually experiencing the delay.
-
Percentiles: is much more useful: e.g. median(50th percentile) lets you know how long half of users typically wait.
- P99, p95, p999 are common , they are referred as tail latency
- Tail latency effects user experiences.
- There is a balance of cost and optimizing the last 1 or 0.1 percentile of response time. Besides, those are sometimes effected by random/unexpected response which cannot be controlled
-
SLO: service level object vs SLA: service level agreement : contact that defines the expected performance and availability of a service.
-
Queueing delay account largely for the response time ate high percentiles due to server(CPU limitation)
- Head-of-line blocking: head of line/queue are slow and following are fast but in the view of client, those all are slow. -> measure response at client side.
- When doing load test, send request independently to avoid head of line blocking.
-
Percentile in practice :
- Tail latency amplification : small number of slow requests make the whole requests looks slow.
- Calculate the latency on a ongoing basis : rolling window for dashboards.
- Keep a list of response time for all requests within time window and sort the list every minute / or there there are efficient algorithms: forward decay, t-digist, HdrHistogram.
- Averaging percentile is meaningless-> use histograms.
Approaches for coping with Load
- Think about the system architecture often when service is growing fast.(data load as well)
- Scaling up(vertical scaling) vs scaling out(horizontal scaling)
- Scaling up: moving to a more powerful machine
- Scaling out: distributing the load across multiple smaller machines.
- Also know as shared-nothing architecture.
- Two ways are used mixed in terms of condition.
- Elastic : add or reduce resource based on the loads detected.
- Vs manually scaling : human analyzes the capacity and decide to add more resources.
- Elastic is good if system load is unpredictable but manual scale is simpler and has fewer operational surprises.
- Systems varies so no magic scaling sauce(one-size-fit-all scalable architecture)
- Good design is based around assumptions : which operations are common and which are rare.
Maintainability
Operability
- Make it easy to operations team to keep the system running smoothly
- Works that are good operability
Simplicity
- Make it easy for new engineers to understand the system, by removing as much as complexity as possible from the system.
- Complexity leads to more cost and more bugs
- Accidental complexity : not from the problem the software solves but from implementation
- Use abstraction to solve this issue. Improve code quality
- e.g. Java hide the machine code , CPU register stuff , SQL hide on-disk and in-mem data structures
Evolvability/Extensibility: Making change easy
- Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change.
- Agility : to make change quickly and reliability