Chapter10 Batch Processing
- Service (only system ): wait request from client to process
- Batch : takes large amount of data and process and output some data
- Stream (near real-time ): something in the middle
Batch Processing with Unix Tools
Simple Log Analisys
-
The log is a the request log for a server , this can help find the top 5 most popular website

Chain of commands versus custom program
-
You can also write small scripts to do this.
ruby counts = Hash.new(0) File.open('/var/log/nginx/access.log') do |file| file.each do |line| url = line.split[6] counts[url] += 1 end end top5 = counts.map{|url, count| [count, url] }.sort.reverse[0...5] top5.each{|count, url| puts "#{count} #{url}" } -
It's not concise but readable , and the process flow is different
Sorting versus in memory aggregation
- Scripts may run out of the memory if the data set is too large while
sortin Linux will handle this-> it split the data into disk and parallels sorting into multiple cores.
The Unix Philosophy
-
- Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new “features”. > 2. Expect the output of every program to become the input to another, as yet unknown, program. Don’t clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don’t insist on interactive input. > 3. Design and build software, even operating systems, to be tried early, ideally within weeks. Don’t hesitate to throw away the clumsy parts and rebuild them. > 4. Use tools in preference to unskilled help to lighten a programming task, even if you have to detour to build the tools and expect to throw some of them out after you’ve finished using them.
-
automation, rapid prototyping, incremental iteration, being friendly to experimentation, and breaking down large projects into manageable chunks— sounds remarkably like the Agile and DevOps movements of today.
A uniform interface
- In unix , that interface is a file. -> sequence of bytes
Separation of logic and IO wiring
- Unix system use stdin and stdout
- Makes it flexible -> you can build your logic with stdio, and logic don't cares about the input format
Transparency and experimentation
- The input files to Unix commands are normally treated as immutable. This means you can run the commands as often as you want, trying various command-line options, without damaging the input files.
- You can end the pipeline at any point, pipe the output into less, and look at it to see if it has the expected form. This ability to inspect is great for debugging.
- You can write the output of one pipeline stage to a file and use that file as input to the next stage. This allows you to restart the later stage without rerunning the entire pipeline.
- But they are in single machine
MapReduce and Distributed Filesystems
- Effective tool for processing the input and producing output
- Running a MR job doesn't modify the input
- In Hadoop implementation of MapReduce, the filesystem like stdin is called HDFS(an open source implementation of Google File System)
- HDFS is based on shared nothing principle
- A daemon process runs on each machine to allow others access the file on the machine
- And there is a central server called NameNode keeps track which node stores which files
- Data are replicated on the hardware level in many machines
MapReduce Job Execution
- A similar to the simple log analysis in the previous section:
- Read a set of input , and break it up into records
- Call the mapper function to extract a ket and value from each input record
- Sort all of the key-value pair by key
- Call the reducer function to iterate over the sorted k-v pairs. Same key in the records will be combined to the same key in the list.
- To create a MapRecuse, you need to implement mapper and reducer
- Mapper called once : extract the key and value from the input record
- Reducer: the framework collect all the values and calls the reducer with an iterator over the values
Distributed execution of MapReduce
- The main difference from pipelines of Unix Command is that : MapREduce can parallelize a computation across many machines without writing code to handle the parallelism
- A Hadoop MapReduce job's paralyzation is based on partitioning:
- The MapReduce scheduler tries to run each mapper on one of the machines that stores a replica of the input file (each machine has enough spare RAM and CPU to urn the map task) -> putting the computation near the data - >saves copying the input file over the network, reducing network load and increasing locality
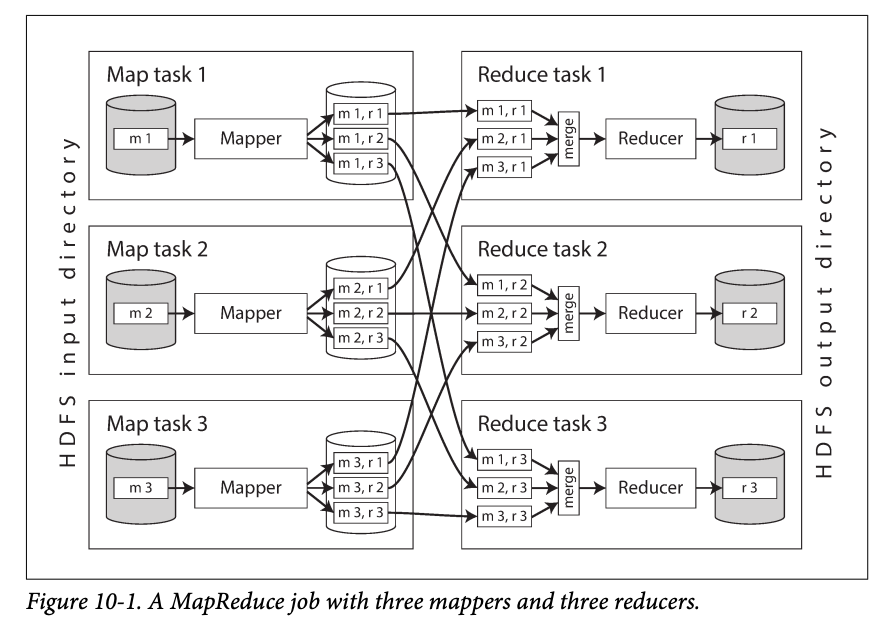
- The code will be copied to the machine that runs the map function. The map starts and records passed to the mapper callback.
- Reduce is also partitioned, and framework use hash to determine the same key will be in the same reducer
- The dataset may be large and cannot perform sorting in memory so output will be partitioned by reducer, and stored in the mapper's disk.
- Shuffle : after the mapper read the input and write the output, reducer will connect to each reducers download file in its partitions and sort.
- Reuters runs with a key and an iterator , iterator will scan all the records with the key and handle them with any logic, and output anything.
MapReduce workflows
- Single MapReduce can do limit things, in the log analysis, single MP job can know the visit count of single page but it cannot know the top 5, which needs another round of sorting.
- Job chain is called workflow. First job output become the second input
- It's like a set of commands
- We can say the batch processing is successful when all the jobs are done -> since there are many jobs so many schedulers are developed : Oozie, Azkaban...
Reduce-side Joins and Grouping
- Join in batch processing means resolving all occurrences of some association within a dataset.
Example: analysis of user activity events
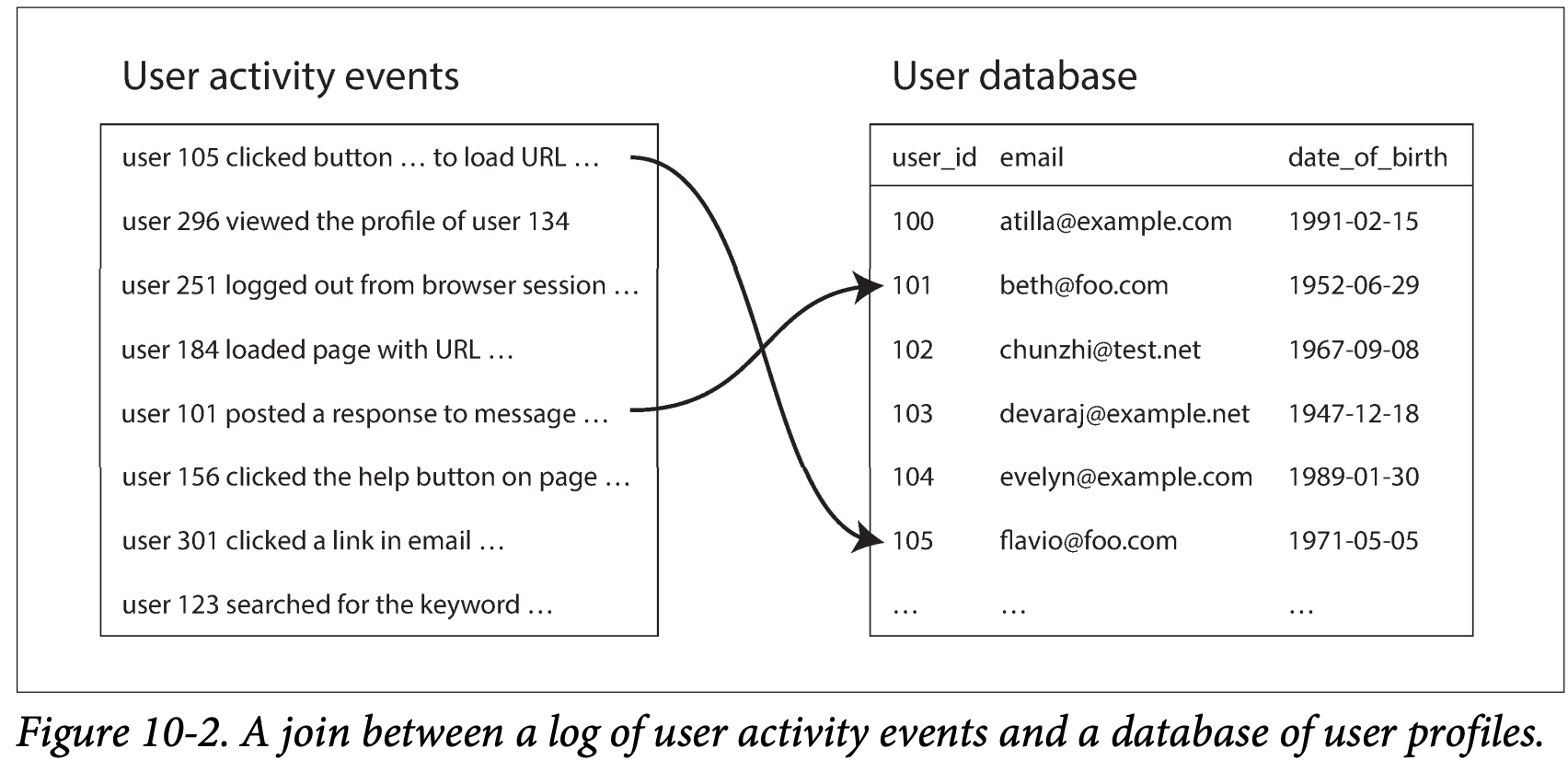
- Company wants to analysis which group like what most, so they process the event in the left, but the event has only the user id so they need to join the user profile table.
- One implementation of join is to query the table for each user id it sees. -> this is time wasting
- A better way is to do the computation in one machine -> random access request overs network for each record is too slow. And request remote database makes the data nondeterministic
- So we make a copy of the database and stores somewhere , in one place
Sort-merge joins
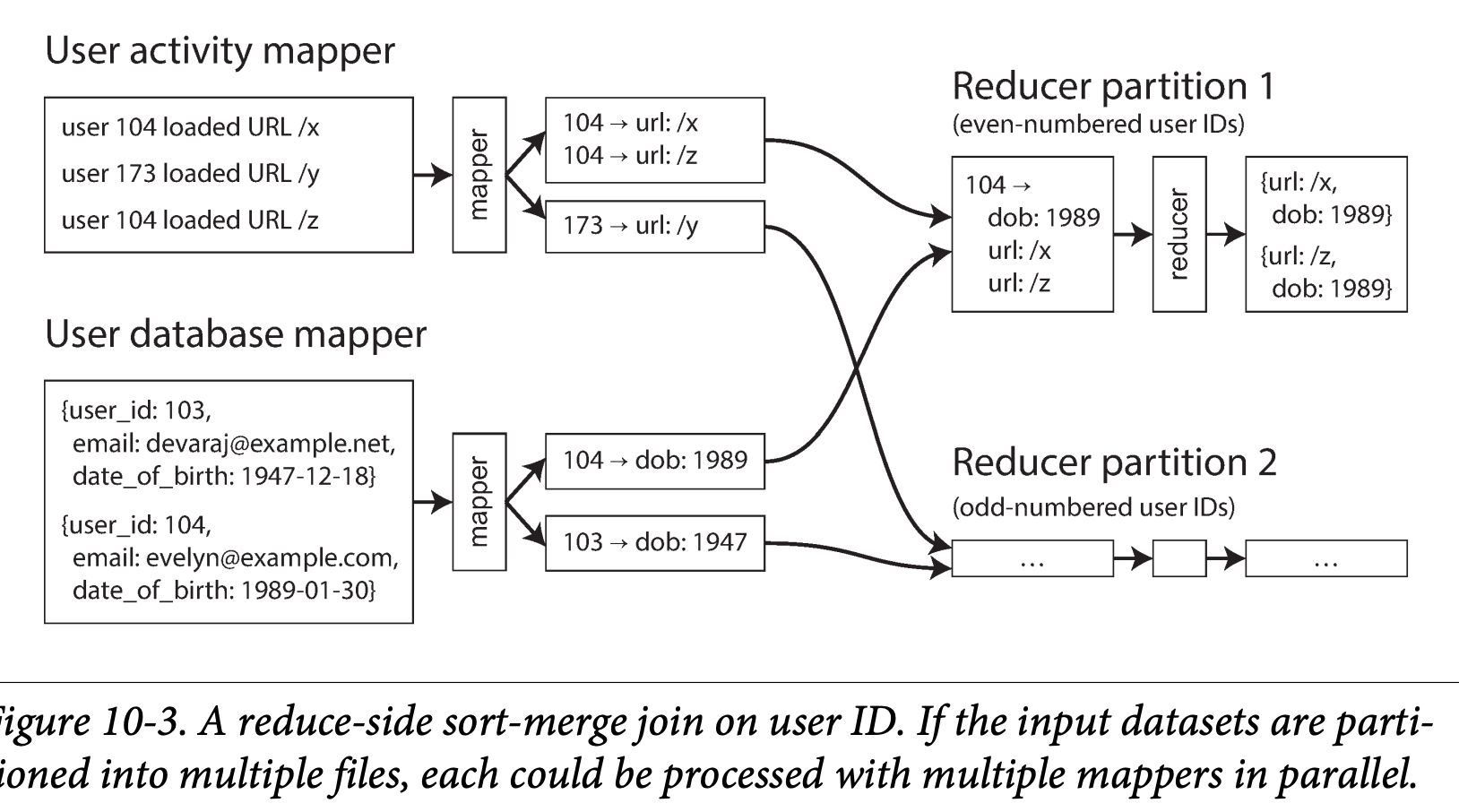
- Mapper output sorted by key , and reducer connect them .
From here I will skip the notes and quickly read original book.
For the part3 of this book dive too much into the details of the implementation, which is not necessary for me currently.