Chapter2 Data models and Query Languages
- Data models effects how your software is written, but also how we think about the problem we are solving
- Application engineers model real-world objects to programming objects and data structures. (API layer)
- Lower level, when you want to store these objects, they are expressed in general-purpose data model, JSON,XML, tables in relational db or graph model.
- Database engineer decides ways of representing those data in terms of bytes in memory, disk or on a network
- Lower level hardware engineers figure out how to represent bytes interns of electric currents, pulses of light....
- Each layer hides the complexity of the layer below by providing a clean data model.
- This chapter will compare some databases.
Relation models versus document model
The birth of NoSQL
Driving force behind NoSQL:
- A need for greater scalability than relational databases can easily achieve, including very large dataset or very high write throughput.
- A widespread preference for free and open source software over commercial database products.
- Specialized query operations that are not supported by relation databases.
- Frustration with restrictiveness of relational schemas.(desire for dynamic and expressive data model.)
The Object-relational mismatch
- Translation layer needed in OOP and SQL data model -> ORM
- But they cannot completely hide the differences between the two models.
- For example :
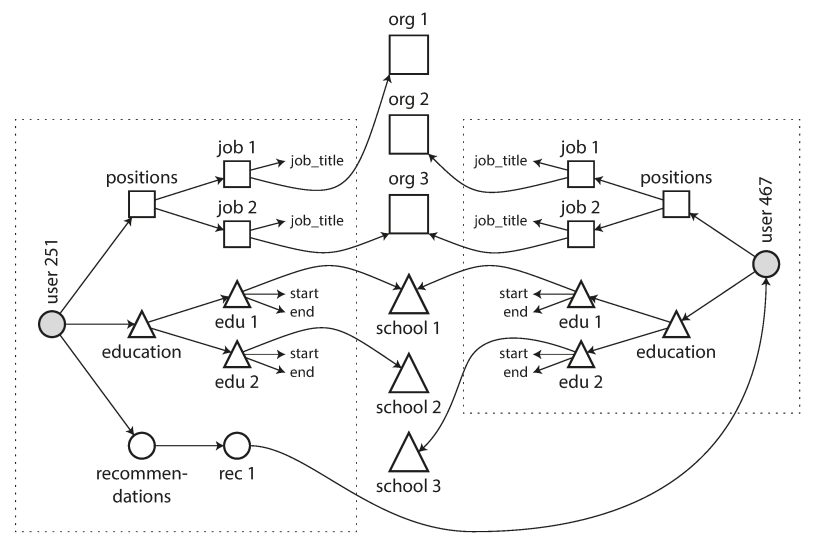
- We have a resume model with some user info;
- But one person has many education/working experience-> one-to-many relation
- User a separation table to store the positions/education -> connected with foreign key
- SQL store structured data types and XML data.
- Encode jobs/eduction info as JSON or XML and store it on a text column in the database, let application decode/interpret its structure a content. (DB cannot query the values inside of encoded column)
- Resume -> self contained document, a JSON representation can be appropriate. -> Document-oriented db: MangoDB, CouchDB, RethinkDB, Expresso....
- But this kind of documents lacks of schema . (Advantage or disadvantage? )
- Locality : relations database performing multiple queries while in JSON documents, all related info are in one place.
- One-to-Many relationship can be explicitly expressed in the JSON documents.
Many-to-one and Many-to-Many Relationships
- region_id and industry id are in ID not free text , why -> Free text vs standard list :
- Consisten style and spelling across profiles
- Avowing ambiguity (several cities has the same name)
- Ease of updating (name stored in one place (the mapping of standard representation and name))
- Localization support
- Relations between standards lists but no such info in free text
- ID can be meaningless thus no need to change, -> free text is meaningful to human so change will cause all change to the text. -> incurs write overheads and risk of inconsistence. -> removing duplications is called normalization
- Many-to-one relationships -> can leverage normalization -> not match nicely to the document data model.
- In relaational db, joins are easy
- In document db, joins are weakly supported (on-to-many don't need join, they are in one document)
- Application code need to support join function if needed.
- Even if the application are fit for the document data model, application data becomes interconnected over time with new features
- Feature 1 : recommendation(including others position and names..(an entity )) from other, can be shown in the name of position
- Organizations and school names are string, but what if they are entities referenced. (Who each of them has host pages...)
Are Document Databases repeating history
Revisit document model and relational model history :
- Network model: a node can have multiple parents, they are connected by pointer, if you have no path of your desired record, you have to go through the paths to find you one; besides, update in this structure become complex
- Relational model: not nested structures, any records can be retrieved in the table(schema) with nay condition.inserting new rows without worrying the foreign key relationships.
- Query optimizer decides which parts execute in which order and indexed used; (effective access 'path') -> new indexed can be added with original query to leverage
- Comparison: both relational and document databases are referring related items using foreign key/document reference. Document databases has similar structure of hierarchical model in the old day but different in terms of many to one and many to many relationships.
Relational versus Document databases Today
Arguments are :
Document : better performance due to locality, schema flexibility, and closer to application object structure.
Relational : better support for joins and many to many and many to one relationships.
Which data model leads to simpler application code?
- If the application has document-like structure, then document model is good. Relational technique of shredding -> splitting a document-like structure into multiple tables can lead to complex schema and unnecessary complicated application code.
- Doc models has limitations: you cannot directly refer to a nested item within a document, there is a pinter like reference to another one. -> not a problem if the nest is not too deep.
- Weak Join support may not be a problem if no relations used in the application-> analytical application who record event occurring with time.
- If you use many to many more, you either reduce the need for joins by denormalization -> but you need more application code to handle the data consistent. And increasing application code complexity will be there to emulate join function.
- Decisions are made of the data items relationship.
Schema flexibility in the document model
- Schema-on-read : document model assume some kind of structure existing ; so it's not totally schema less . (Traditional relations database -> schema on write: schema are explicit and database ensures all written data conforms to it)
- Format change : in document you just do the change in the code ; in relational database, you might need a schema change and a migration if needed . This can be quite slow .
- Also, update is slow since every rows will be rewritten.
- Schema on read are suitable for :
- There are many different types of objects
- The structure of the data is determined by external system over which you have no control .
Data locality for queries
- Only applies when you need large parts of the document at the same time. -> you load a large table and only use a small portion of it -> waste
- So if you want to leverage this , you'd better eep the file fairly small and avoid writes that increase the side of a document.
- This locality is not solely in the document database. Many other relational and BigTable data model (Cassandra and HBase) put related tables together for locality.
Convergence of document and relational databases
- PostgreSQL and MySQL supports XML and JSON
- RethinkDB and MongoDB supports join like functions. (MongoDB do some client side join thought it's slow.)
Query Languages for data
- Impressive language : tell PC to perform certain operations in a certain order
- Declarative: specify the pattern of the data you want (condition), and how you want the data be transformed(sorted, grouped, aggregated)(query optimizer do the index search, join methods, execution order... )
- Declarative hide implementation of database engines. -> allows performance improvement without changing queries. -> code depended on that may be broken if change queries.
- Declarative languages often lend to parallel execution.-> can better utilizing modern multicore CPUs; imperative language is hard to run paralleled since they specify the execution order -> so declarative languages have changes to be faster.
Declarative queries on the web
-
Basically for the declarative languages, there is a explainer or something that help to explain the intrusions or languages, compared to the imperative languages who has to define the order or the instructions by coder themselves.
-
Example in a browser : XSL or CSS selector -> declarative
-
If you want selected page to have a blue background, using CSS
css li.selected > p { background-color: blue; }xsl // XPath expression <xsl:template match="li[@class='selected']/p"> <fo:block background-color="blue"> <xsl:apply-templates/> </fo:block> </xsl:template>

-
Using core DOM API, code would be like (imperative):
javascript var liElements = document.getElementsByTagName("li"); for (var i = 0; i < liElements.length; i++) { if (liElements[i].className === "selected") { var children = liElements[i].childNodes; for (var j = 0; j < children.length; j++) { var child = children[j]; if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") { child.setAttribute("style", "background-color: blue"); } } } }
-
-
CSS will automatically detect the >p rule no longer applies and remove blue backgrounds as soon as the selected class is removed(if no CSS, the blue background will not be removed)
-
CSS and Path hide the DOM details, if you want to improved the document.getElementsByClassName("selected") performance, you don't have to change the CSS queries, without CSS, you need to change the code.
MapReduce Querying
-
MapReduce is a programming models for processing large amounts of data in bulk across many machines, popularized by Google.
-
A limited from of MapReduce is supported by some NoSQL, including MangoDB and CouchDB to perform read-only queries across many documents.
-
It's a hybrid pattern of declarative and imperative. -> its query logic is expressed with snippets of code, but those will be called repeatedly by the processing framework.
-
It;s based on map and reduce functions.
-
An example : you are a marine biologist and you want to add an observation records to you db , one day you want to generated a report saying how many sharks you sighted per month:
-
PostgreSQL(who has no MapReduce supported)
postgresql SELECT date_trunc('month', observation_timestamp) AS observation_month, sum(num_animals) AS total_animals FROM observations WHERE family = 'Sharks' GROUP BY observation_month;The date_trunc('month', timestamp) function determines the calendar month containing timestamp, and returns another timestamp representing the begin‐ ning of that month. In other words, it rounds a timestamp down to the nearest month.
-
In MongoDB:
db.observations.mapReduce( function map() { var year = this.observationTimestamp.getFullYear(); var month = this.observationTimestamp.getMonth() + 1; emit(year + "-" + month, this.numAnimals); }, function reduce(key, values) { return Array.sum(values); }, { query: { family: "Sharks" }, out: "monthlySharkReport" } );The filter to consider only shark species can be specified declaratively (this is a MongoDB-specific extension to MapReduce).
The JavaScript function map is called once for every document that matches query, with this set to the document object.
The map function emits a key (a string consisting of year and month, such as "2013-12" or "2014-1") and a value (the number of animals in that observation).
The key-value pairs emitted by map are grouped by key. For all key-value pairs with the same key (i.e., the same month and year), the reduce function is called once.
The reduce function adds up the number of animals from all observations in a particular month. The final output is written to the collection monthlySharkReport.
-
-
Map and reduce are restricted to what they can do. -> they are pure function that use data, and don't do data queries.
-
SQL can also above MapReduce to support distributed system
-
Usability problem: you need to write the coordinated js functions very carefully, normally harder than normal queries.
-
MangoDB supported query optimizer (due to declarative language) called aggression pipeline -> like subset of SQL but -> using JSON syntax
Graph-like Data models
- Many to many relationships are common in data.
- Nodes in a graph can be in same type and different type
- Ways of structuring and querying data in graph
- 2 models
- 3 query languages
Property graphs
-
Vertex consists of : an id, a set of outgoing edges, in coming edges, a collections of properties(k-v pairs)
-
Edges: an id, tail vertex(edge start), head vertex(where edge ends), a label describe the relationship between two vertices; a collections of properties(k-v pairs)
-
The graph can be stored in relational tables in two tables, one for edges and one for vertexes.
postgresql CREATE TABLE vertices ( vertex_id integer PRIMARY KEY, properties json ); CREATE TABLE edges ( edge_id integer PRIMARY KEY, tail_vertex integer REFERENCES vertices (vertex_id), head_vertex integer REFERENCES vertices (vertex_id), label text, properties json ); CREATE INDEX edges_tails ON edges (tail_vertex); CREATE INDEX edges_heads ON edges (head_vertex);- Any vertex can have an edge connecting it with any vertex. No schema restriction which kinds of things can/cannot be associated.
- Vertex -> incoming and outgoing edges -> travers a graph (thats why tail_vertex and head_vertex has index on it)
- Diffrent relationship labels allows you to store different type of objects which still maintain a clean data model.
-
Good evolvability: as you add features to the application, a graph can be easily extended.
The cypher query language
-
Created for Neo4J. It's a declarative language for property graphs.
cypher CREATE (NAmerica:Location {name:'North America', type:'continent'}), (USA:Location {name:'United States', type:'country' }), (Idaho:Location {name:'Idaho', type:'state' }), (Lucy:Person {name:'Lucy' }), (Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica), (Lucy) -[:BORN_IN]-> (Idaho) -
e.g. find the names of all the people who immigrated from the United States to Europe. -> find who have a BORN_IN edge on a location within the US and also LIVING_IN edge to location within Europe, and return name property of each those vertices.
cypher MATCH (person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}), (person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'}) RETURN person.name
Graph queries in SQL
-
You can query things using SQL but it's more difficult. -> normal relational data model has fixed join -> here you need to traverse the edges so you don't know how many joins you need in advance.
- A person can lives in stage, city, or country -> different levels of location and hierarchy.
- Cypher 'WITHIN*0' can be concisely -> follow a within edges zero or more times , like an
*operator in a regular expression
-
sql WITH RECURSIVE -- in_usa is the set of vertex IDs of all locations within the United States in_usa(vertex_id) AS ( SELECT vertex_id FROM vertices WHERE properties->>'name' = 'United States' UNION SELECT edges.tail_vertex FROM edges JOIN in_usa ON edges.head_vertex = in_usa.vertex_id WHERE edges.label = 'within' ), -- in_europe is the set of vertex IDs of all locations within Europe in_europe(vertex_id) AS ( SELECT vertex_id FROM vertices WHERE properties->>'name' = 'Europe' UNION SELECT edges.tail_vertex FROM edges JOIN in_europe ON edges.head_vertex = in_europe.vertex_id WHERE edges.label = 'within' ), -- born_in_usa is the set of vertex IDs of all people born in the US born_in_usa(vertex_id) AS ( SELECT edges.tail_vertex FROM edges JOIN in_usa ON edges.head_vertex = in_usa.vertex_id WHERE edges.label = 'born_in' ), -- lives_in_europe is the set of vertex IDs of all people living in Europe lives_in_europe(vertex_id) AS ( SELECT edges.tail_vertex FROM edges JOIN in_europe ON edges.head_vertex = in_europe.vertex_id WHERE edges.label = 'lives_in' ) SELECT vertices.properties->>'name' FROM vertices -- join to find those people who were both born in the US *and* live in Europe JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id; -
Obviously, cypher and is more suitable for this data model.
Triple-stores and SAPRQL
-
Almost the same as the property graph model, only using different words but same idea.
-
turtle @prefix : <urn:example:>. _:lucy a :Person. _:lucy :name "Lucy". _:lucy :bornIn _:idaho. _:idaho a :Location. _:idaho :name "Idaho". _:idaho :type "state". _:idaho :within _:usa. _:usa a :Location. _:usa :name "United States". _:usa :type "country". _:usa :within _:namerica. _:namerica a :Location. _:namerica :name "North America". _:namerica :type "continent".
The semantic web
NA
The RDF data model
Resource description framework
Can be written as XML
The SPARQL query language
-
a query language for triple stores. ->
-
Cypher patterns are borrowed from this sparkle, so they look alike.
-
SPARQL PREFIX : <urn:example:> SELECT ?personName WHERE { ?person :name ?personName. ?person :bornIn / :within* / :name "United States". ?person :livesIn / :within* / :name "Europe". } -
Difference of CODASYL and graph mode;
- Graph model has no schema restriction
- Graph model can start from any vertex
- Vertex and edges are not ordered
- Queries in graph model is declarative
The foundation: Datalog
Older model.