Chapter3 Storage and Retrieval
Data structures that power your database
- Log based database needs index to find particular data efficiently.
- The idea behind is basically keep some additional data aside , which helps you locate data you want.
- Adding index incurs overhead of writing, but boots reading
- Application engineer add index wisely .
Hash Indexes
-
K-V index can be implemented by hash map.
-
e.g. you have a in memory hash map that stores the key and offset of the data for that key. You don't have to go through all the file(log-structured file on disk), you only refer the map and go to the right position and retrieve data. -> this is the default storage engine(Bitcask) of Riak behavior.
-
Riak offers high-performance reads and write when all the keys fits in the available RAM.
-
Data can use more space than memory available since only required data are loaded; if others data needed we could do a disk I/O; if the data is already in the disk, we don't need disk IO.
-
It's suitable for the data whose value is frequently updated: like the data of a cat video and its play count. -> you have many writes but not too many keys so they can be all in memory.
-
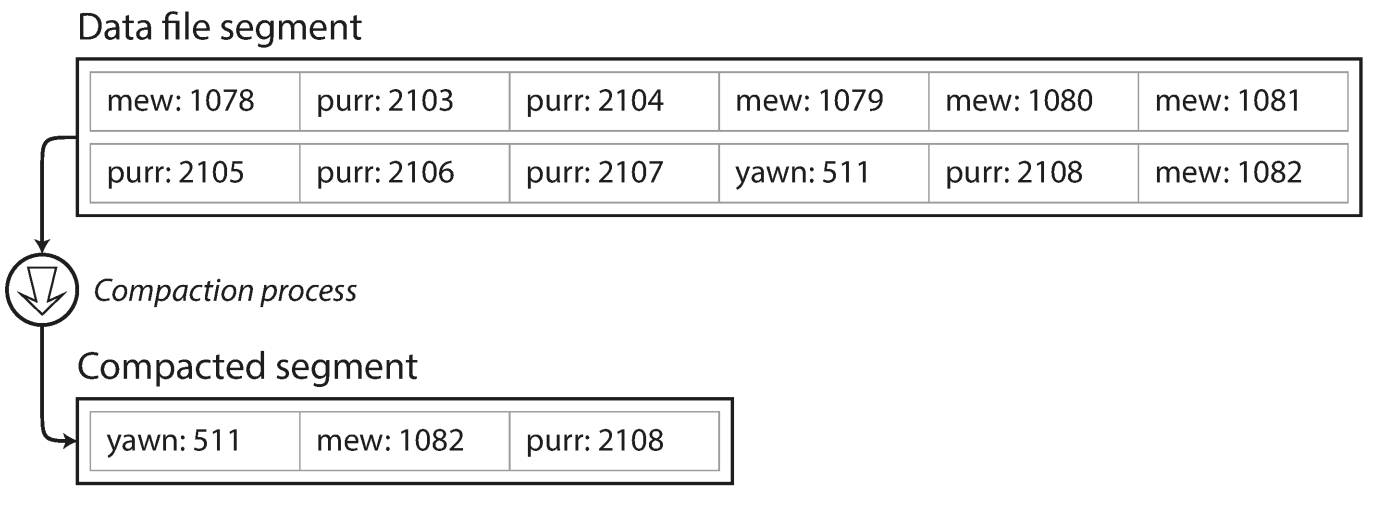
Append-only data log files can be split into segment(fixed size) -> to avoid running up the disk space -> compaction can save up space by abandoning old data(duplicated keys).
-
Segments can also be merged together when compaction(assume they tends to become smaller after compaction) -> this creates new segments by a background thread. -> we can continue serving read and writes
-
Each segment has a in memory hash table mapping keys to file offset.
-
Issues in real implementation:
- File format : binary is good , data size in byte followed with raw string
- Deleting records: append a special deletion record -> tombstone. When log segments are merged and compaction, these tombstone will be skipped.
- Crash recovery : Riak stores a snapshot for each segment's hash map on disk to accelerate restore in memory map -> compared with reading all the segment file and rebuild maps.
- Partially written records : Bitcask files include checksum , allowing corrupted parts of the log to be detected and ignored.
- Concurrency control: only have one writer.
-
Pros of append only:
- Appending and segment merging are sequential write operation are generally much faster than random writes.
- Concurrency and crash recovery are much simpler -> you have the operation history
- Merging old segments avoid the problem of data files bettering fragmented over time.
-
Limitations:
- Hashtabe must fits in memory . -> you could mainatain on disk but it doesn't perform well .(lots of random access )
- Ranges queries are not efficient -> you have to look up each key individually
SSTables and LSM-Trees
-
Sorted String table: keys are sorted and no duplication(within merged segment file)
-
Pros:
-
Merging is simple and efficient -> merge sort like -> you copy the lowest key among each segment file into new file and repeat;
- If the same key appears in several inputs segments, we could only keep the most recent segment file; -> a segment contains all the written value, if one value is outdated, all the values on the segment is outdated and we can abandon.

-
Index can be sparse -> you can leverage neighbor to find the key since they are ordered , you don't have to keep all the keys

-
To save space and reduce I/o bandwidth, the records can be compressed before writing to disk ; each in memory index the points ay the start of a compressed block
-
Constructing and maintaining SSTables
- In memory we can use balanced tree data structure -> red black tree or AVL tree
- How this engine works :
- When a write comes in, add it to a in mem data structure -> sometimes called memtable;
- When the memtable gets bigger the some threshold, -> write it out too disk aas an SSTable file. -> this can be done efficiently since tree already maintained the kv pairs sorted by key. The SSTale becomes the most recent segments file to the database -> while this memtable is being written to the database, a new memtable can start to serve writes.
- In order to serve read, first try to find the key in memtable, then in the most recent on disk segment, then the next older segment
- From time to time, run a merging and compaction process in the background to combine segments files and to discard overwritten or deleted values .
- It suffers : when database crashes, the data in memory and not being written to disk can be lost. -> keep a separate log on disk to which where write is immediately happened. -> for restoration , it's discard when the memtable is written to the disk.
Making an LSM-tree out of SSTables
- The algorithm is used in levelDB and rocksDB, kv storage engine design to embed to applications. Similar storage engine are used in Cassandra and HBase.
- Log structured merge tree : merging and compacting sorted files.
- Lucene: an indexing enigen for full text search used by Elasticsearch and Solo, using a similar method for sorting its term dictionary.
- Full text search is based on the similar idea ; give a word in a search query, find all documents that mention the word.
- This is implemented by a kv structure , key is a worked and value is a list of IDs of all documents that contains the word. In lucene, this mapping is kept in SSTable liked sorted files, which are merged in background as needed.
Performance optimizations
- Bloom filters can be leverage to check is a key is existing -> accelerate key looking up in LSM-tree algorithm when the key doesn't exist.-> otherwise you have to check memtable, disk segments one by one. Introducing many unnecessary disk IOs.
- Different strategies determine the order and time of how SSTables are competed and merged.
- Size-tiered and leveled compaction: LevelDB and RocksDB uses level companion ; HBase uses size-tiered and Cassandra compaction support both.
- Size-tired : newer SSTables are successively merged to older and larger SStables.
- Level compaction: the key range is split ip into smaller SSTables and older data is moved into separated levels , which allows the compaction to proceed more incrementally and use less disk space .
- This way is simple and effective even the dataset is bigger than the available memory ; and range queries is supported because of sorted records ; and the write can be in high throughout because of the sequential writing
B-trees
-
K-v index but different design with log structured index
-
Log-structured break the database down into variable sized segments; while b-tree break the database down into fixed size blocks -> which more corresponding to the hardware(disks are arranges at fixed size blocks)
-
Each page can be identified using an location, and can be referenced -> on disk
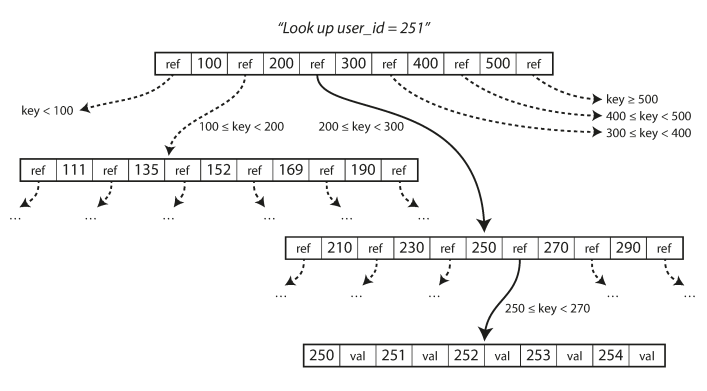
-
You have a root and you start from it every time you want to search a key. Each Child is responsible for a range of keys ; eventually after layers, a leaf node is found with either the value, or the location where the values can be found.
-
Branching factor: the number of the child pages referenced in one page. Above graph is 6 and normally this value could be several hundred.
-
Updating the value: you load the key value, you update value, you write back;
-
Adding new key value: find the write position, if no available space; the tree will be split.
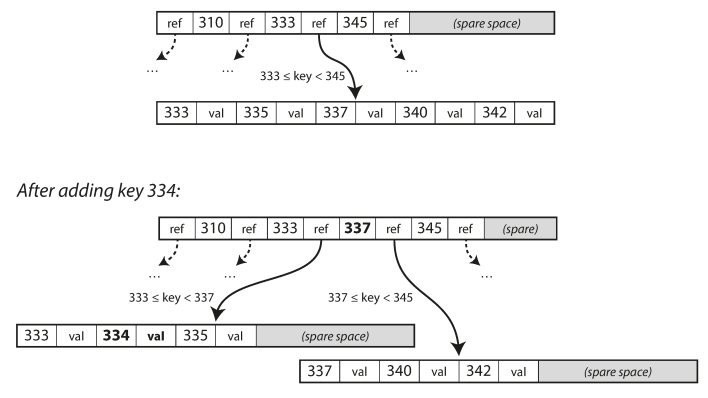
-
This algorithm ensures the tree remains balanced: a b-tree with n keys always has a depth of O(logn); most database can fit into a four levels depth b-tree, so you don't need to follow many pages referees to find the wanted page. -> A four -level tree of 4KB pages with a branching factor of 500 can store up to 256TB.
Making B-Trees reliable
- The basic write will overwrite the page on disk with new data (assuming the write doesn't change the page location) -> contrast to the log structured append only to files
- A dangerous situation :
- When you insert a record and a child node is overfull -> you need to spilt the page and rewrite two new ; and their reference on the parents needs to be updated as well.
- If the database crashed, there could be an crashed index -> orphan page.
- To make this reliable -> additional data structure on disk : a write ahead log(WAL), also known as redo log. -> append only, page changes need to write to this redo log before it applies to the tree. -> can be used in the restoration after crash to make consistent state. (-> what if crashed when writing WAL?)
- Concurrency control the multiple treads is going to access the B-tree at the same time. -> latches (lightweight locks ) -> compared with log structured which is simpler(do merging and compaction in background without interference)
B-tree optimization
- Instead of using WAL for crash recovery, some database (LMDB) use a copy-on-write scheme. -> a modified page is written t a different location and new version of the parent pages in the tree is created pointing at the new location. -> useful for concurrency control.
- saving space by not storing the entire key but abbreviating it. Especially the keys on tiger interiors of the tree -> they only need to provide the boundary to help locating -> this will allows higher branching factor - resulting in lower level.
- Many implementation tries to make the neighbor pages put together to help accelerate disk seek -> though it's difficult to maintain the order as the page amount increasing . -> may need page by page looking for.
- Reference to left and right have been added to avoid scanning keys moving back and forth from child to parent.
- B-tree variants such as fractal trees(B+tree) borrows some log structures ideas to reduce disk seeks.
Comparing B-trees and LSM-trees
Advantages of LSM-trees
- A b-tree much write very piece of data at least twice. One for page and one for WAL. And there is overhead for overwriting a singe page event small piece is changed.(and some engines even override the smear page twice to avoid ending up with a partially updated due to power failuer)
- Log structured also rewrite multiple times due to repeated compaction and merge SSTables. -> write amplification : single write results in more writes. -> a particular concern on SSD since they have limited lifetime writes.
- If write head application, the performance bottleneck could be the rate where the database can write to disk -> write amplification cost more writes on disk and less bandwidths the disk can serve writes.
- LSM-tree are typically able to sustain higher write throughput than B-tree
- Lower write amplification
- Sequentially write compact SSTable files rather tag having to overwrite several pages in a tree. (This is particular important in a magnetic hard dived where sequential wires are much faster than random write )
- LSM tree can produce smaller fiesta on disk than b-tree due to merging and compaction. B-tree will have some unused space due to fixed size page when spilt .
- In many SSD, the random writes will be turned into sequential. -> so the storage engine write pattern is less pronounces -> but lower write amplification and reduce fragmentation are still good -> allows SSD more read and writes request within the available I/O
Downsides of LSM-trees
- Background process of merge and compaction impact ongoing read and writes. -> and this is unpredictable compared with B-tree queries.
- Compassion arises at high write thought put : write bandwidths shared between loving, flushing an memtable to disk and compaction threads.-> as database increased size, more compaction happens
- If write throughput is high and compaction can not keep up, the unmerged segments will soon run out the disk space and read also slows down because they need to check more segment files. -> and typically the SSTable based storage engine don't throttle the wire rate. -> you need to monitoring carefully.
- Keys in b-tree are single copy while lsm tree has many duplicated keys. -> b-tree advantage in transaction -> semantics can directly attach to the tree.
Other indexing structures
- Primary index : used to identity a record in the database;
- Secondary index : created not based on the PK, -> build relation with primary index -> help perform joins efficiently,
- Can be constructed by the k-v index but may be duplicated keys
- Can be solved by return the list matching the key
- Or adding additional identified to make the row identical
- Can be constructed by the k-v index but may be duplicated keys
Storing values within the index
- For k-v index, the value can be two types
- The actual row in questoin
- Or the reference to the row stored elsewhere
- The place stored where row stored is called heap file (stores data without order) -> help avoid duplications in secondary index since they refer only the place and the same data are stored in one place.
- Updating a value without changing the key
- Heap file approach can be quite efficient-> if the new value is nor larger than the original one, -> in place update
- If the new file is larger -> may need to move to a new place and all indexes may be updated the original locations.
- Clustered index vs non clustered index
- Clustered : the row directly stored in the index value -> to avoid the additional reference overhead ;
- Covering index:
- Compromise of clusters and non-clustered index, who stores some of the tables rows
- indexes stored the desired data and queries are answered by the queries alone.
- Clustered index and covering index has good read performance but with write overhead; and database also needs to go to addition efforts to enforce transactional guarantees.(applications don't want to see inconsistencies due to the duplication)
- e.g. when you are referring a non PK column, they might be non identical for each row, so heap file helps reduce duplicate by saving the only reference and point to only one place when they are referring other PKs.
Multi-column indexes
- Concatenated index: combine several fields into one key by appending one column to another. -> the order matters
- Like the old phone book, if you want to search people with particular first name , for people with first name and family name, you can search it, but the index is useless when you want to search people with particular family name.
- Multi-demensinal indexes are more general
- e.g. say a restaurant search website lets you search restaurants in an area, it will check the longitude and latitudes;
- A LSM-tree or B-tree index s not able to answer this kind of question efficiently, they can only give you a range of longitude/latitude but any latitude/longitude but not both simultaneously.
- One way is t transfer the two-d number into single number and use the b-tree index ; or use specialized spatial index like R-tree
- More examples : multi-color search products in a e-commerce website or a weather website to search the weather in many dimensions.
Full-text search and fuzzy indexes
- Above queries assumes that you know all the data; what if you don't know the data or you have typo?
- Full text search engine allows a search for one word expand to include synonyms of the word
- To ignore grammatical variations of words
- To reach for occurrences of words near each other in the same document and support linguistic analysis
- Lucene allows search for words with in a certain edit distance -> use SSTable like structure -> a small in memory index to tell the queries which offset in the sorted file they need for a key -> in memory index structure is like a trie.
Keeping everything in memory
- RAM becomes cheaper so it's feasible to keep the database in memory (in single machine or distributed to several machines)
- These kind of database still write to disk : only for append-only log for durability; reads are served from memory -> writing to disk also has advantage : can be easily backup and analyzed and infected by external utilities
- The key of performance improvement is not from they don't need read from disk but they don't need to encoding the in memory file data to the format can be written to disk
- Another advantage of memory database they provide many data models that are difficult to implement with disks based indexes.
- Anti-caching : evict LRU data from memory and load back when needed -> thus memory can hold more data than its actual size. -> like the OS virtual memory.
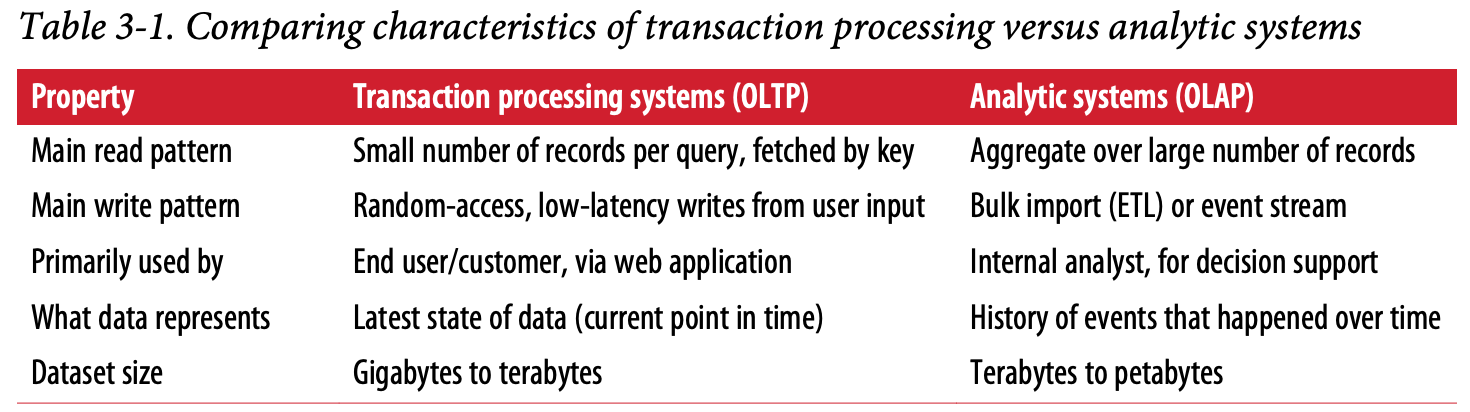
Transaction Processing or Analytics?
OLAP vs OLTP
Data warehousing
-
Separate database that analyst can query to the hearts content without interfering OLTP operations.
-
Copies from OLTP, parsed to an analysis friendly schema -> this process is called ETL (extract, transform, load)
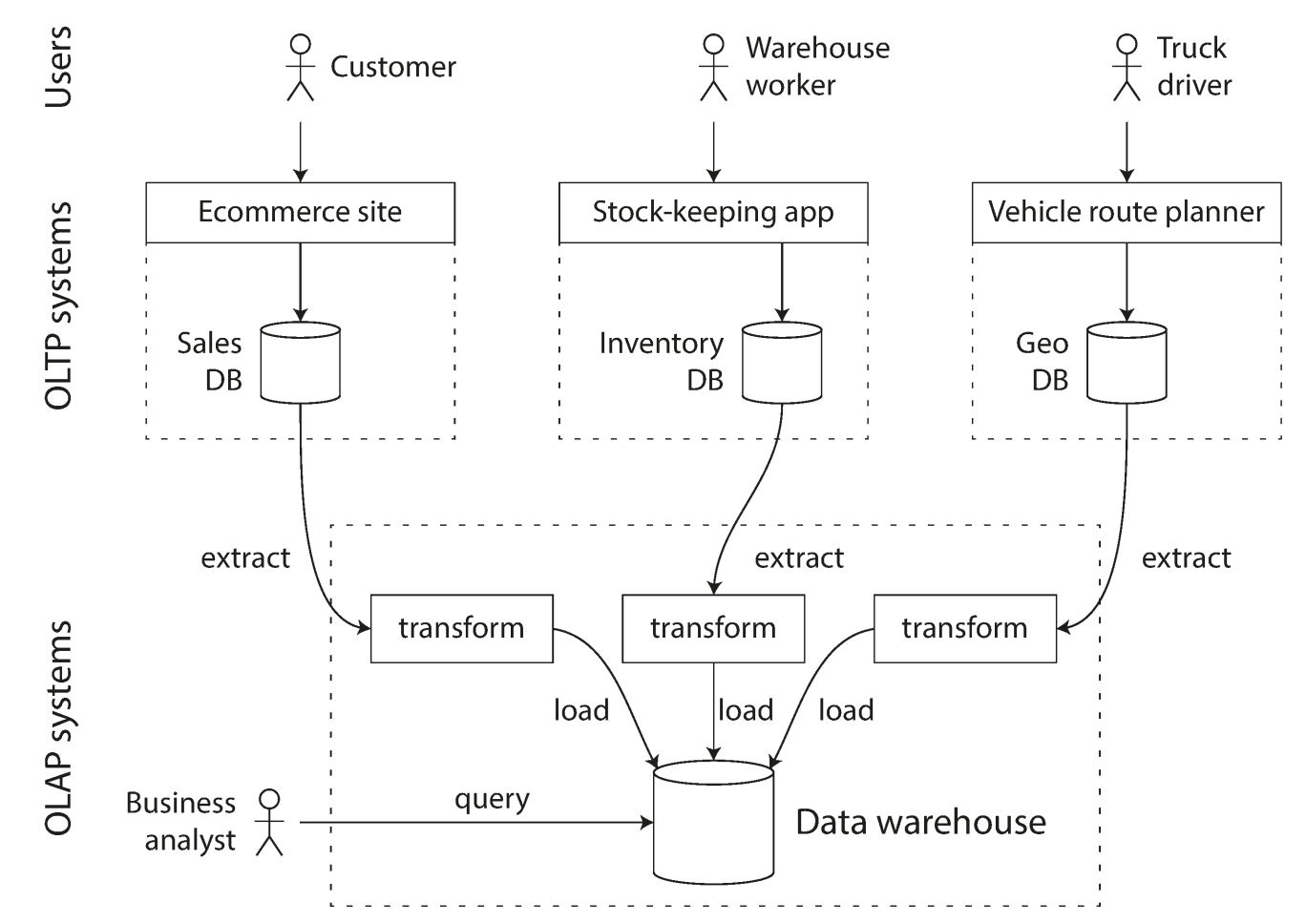
-
-
Another advantage is that the data warehousing schema can be analysis friendly
The divergence between OLTP databased and data warehouse
- Relational OLTP database and a data warehouse looks alike on surface, they both use SQL queries
- But they are different internally since they have very difference query pattens based on their purpose.
Stars and snowflakes: schemas for analytics
-
Most data warehouse use star schema (dimensional schema)
-
Where "star" came from:
-
The record of the data we want to analysis->core table -> called fact table
-
The data can be very large some the data stored on the fact table is reference -> to dimension table
-
One fact table to many dimensional table -> like a star
-
Even data and time are often represented using dimension tables ; which allows additional information(such as public holidays) about dates to be encoded
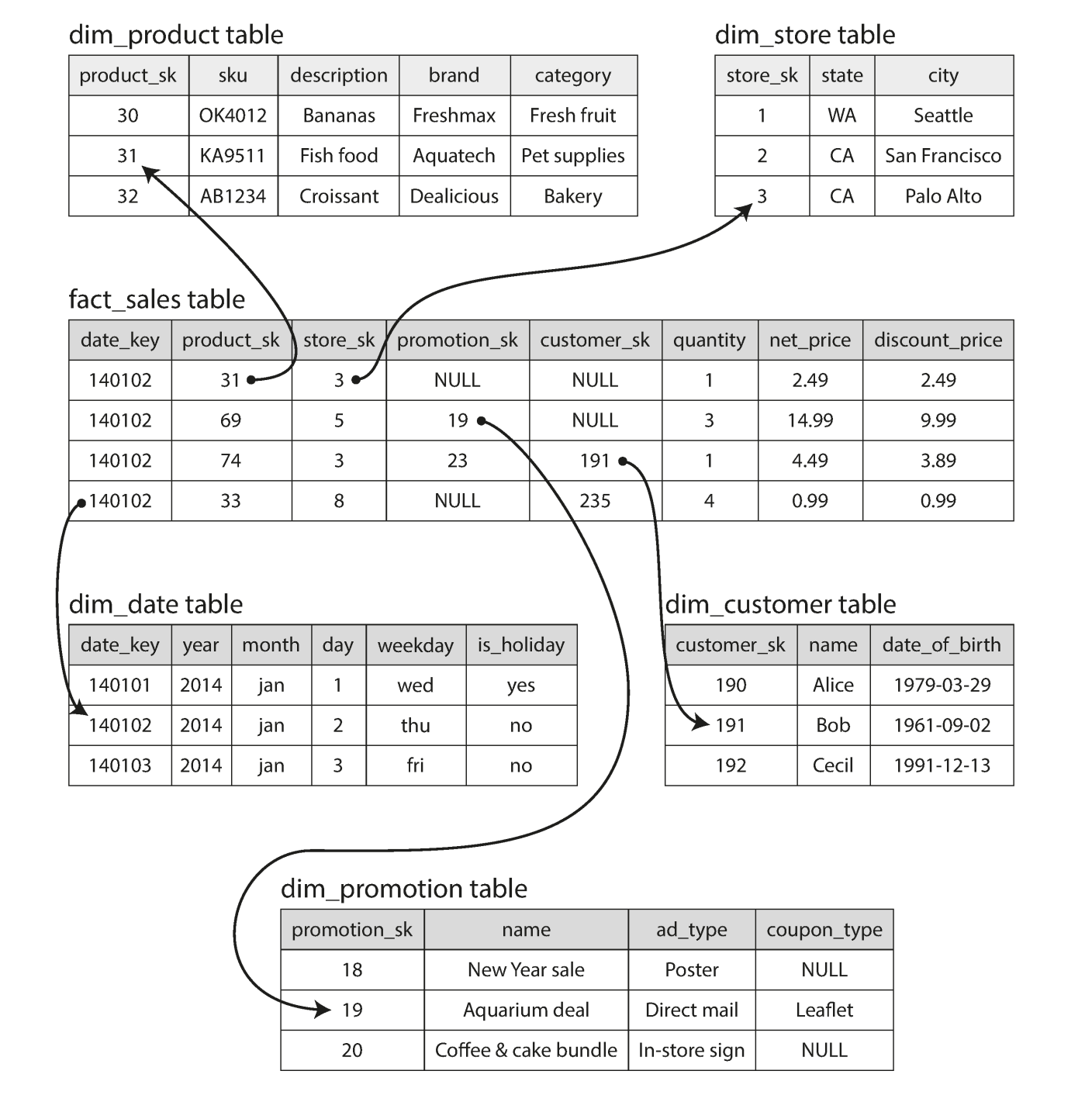
-
-
Snowflake schema : where the dimensions are further broken down to sub dimensions. -> can be more normalized but more complex to work with.
-
Tables are wide in a data warehouse , include many metadata that might be relevant.
Column-Oriented Storage
-
Although the tables are wide but we most of time use few of them. -> how to execute the queries efficiently?
-
Column-oiented storage : don't store all the values from one row together, but stored all the values from each column together instead. If each column is stored in a separate file, a query only needs to read and parse those columns that are using in that query, which can save a lot of work.
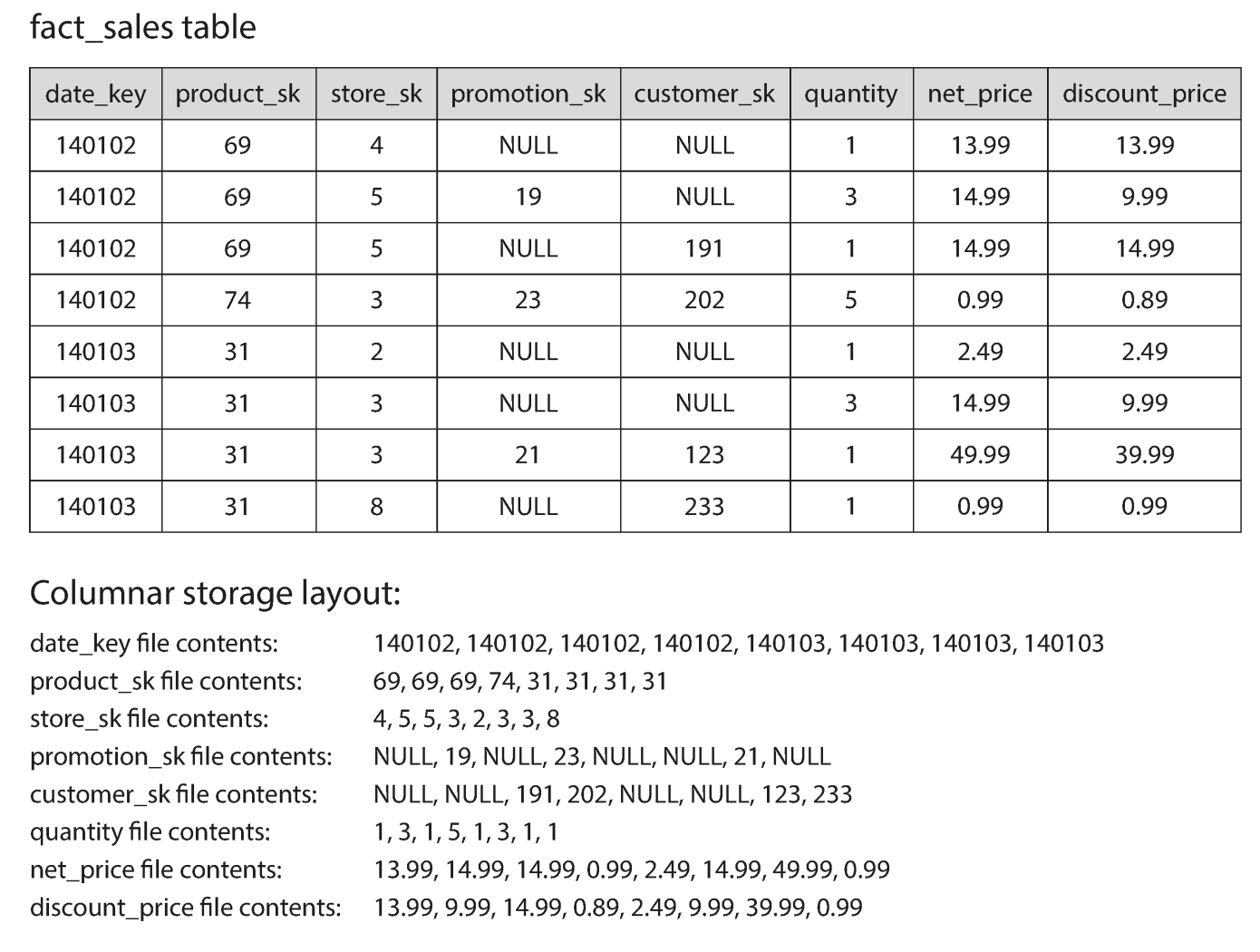
-
Column style relies on each column file containing the rows in the same order.
Column compression
-
Bitmap encoding :

-
The number of the distinct values in a column is small compared to the number of rows. 1 means has that value while 0 is not
-
If n is bigger, (n is the number of distinct values), there will be many 0s, we can additionally do a run-length encoding.
-
e.g. bitmaps are suitable in such situation :
-
sql WHERE produck_sk IN (20, 68, 69):Loads he three bitmaps for product_sk=30, product_sk=68, product_sk=69, and calculate the bitwise OR of the three bitmaps, which can be done efficiently
-
Memory bandwidth and vectorized processing
- Bottleneck :
- CPU mispresictions and gullible in the CPU instructions processing pipeline
- Bandwidth for getting data from disk into memory
- For 1, column oriented can help to reduce the data loaded from disk;
- Vectorized processing : For 2, column oriented can also help
Sort Order in column Storage
- The order of rows can be in order to help index;
- If we want order values in a single column, we need to move the whole row for those values, otherwise you only move a column value will mismatch other value for different records.
- You can have a value to order and another value as secondary order key
- The order can also helps the compression like we did before the run-length encoding. (After ordering, we have a sequence of consecutive same values) -> like we used in the bitmaps
- The compression effective is stronger on the first sort key and more jumped up for the second and thirds...
Several different sort orders
Having different sort orders for all values
helps redundant
mainly helps answer different types of queries
Writing to column-oriented storage
- Writes might become more difficult
- It's hard for column-oriented database update in place like we did in B-tree, and if you want to insert in the middle, all the records might be moved.
- But we can leverage LSM-tree: all writes goes to the memory first and then write to disk in bulk. It doesn't matter the in-memory store is row or column oriented. When enough writes have accumulated, they are merged with the column files on disk and written to new files in bulk.
Aggregation : Data Cubes and Materialized Views
-
Not all data warehouse are column oriented but they do faster;
-
Materialized aggregates :
- Data warehouse queries often involve an aggregate function.
- The can be cached to avoid calculate every time queries.
-
Materialized view :
- They are calculated copies in the database (compared with the relational database who is a virtual table)
- Each updates will cause update for such views but database will handle this
- So this materialized view only used in OLAP (it has more reads and rare writes since writes will cause the view updates which is expensive)
-
Data cube or OLAP cube
- Dimensions cross generated aggregation tables
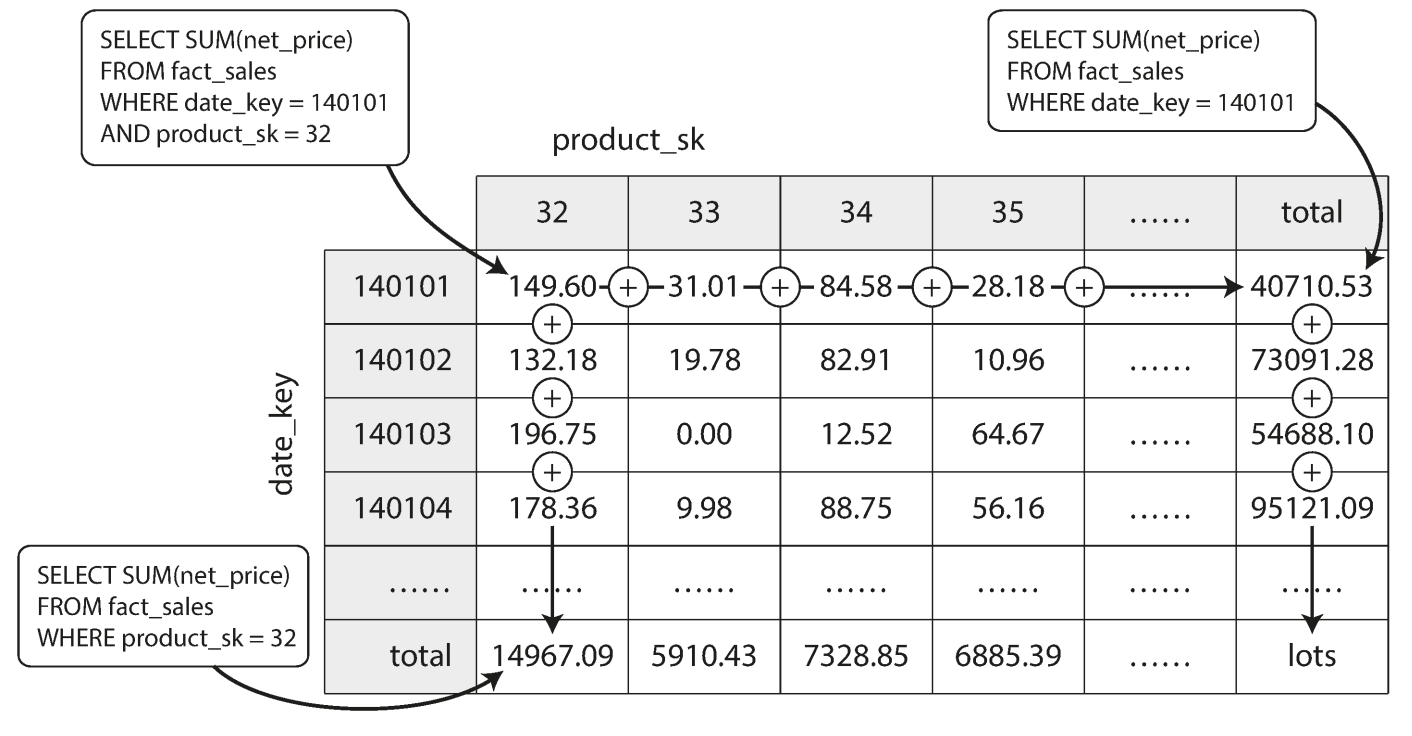
- Certain queries can be very fast ; but they can be inflexible since lack of raw data;
- so many data warehouse keep as much as more raw data and use aggregated data cube as performance boost for certain queries.