Chapter4 Encoding and Evolution
- In this chapter, we will explore how several formats handle schema change and how they support system where old and new data coexist.
- How these formats are used for data storage and communication
Formates for encoding Data
- Programs usually work with data in two different representations: one is in-memory data structure arrays, maps...., those structure are optimized for CPU to handle with pointer; the other one is byte(like JOSN document) that used for data transformation in network or file system.
- They need to be somehow transferred from each other :
- In-memory-> bytes : encoding
- Bytes->in-memory: decoding
Language specific Formats
- Many programing languages provides handy libraries to do the serialization and deserialization , which allows you using minimum additional code, but:
- The encoding format will be tied to a particular language
- Security: In order to restore the encoded data, they are allowed to be restore from any class if we encounter some attacker they might execute any malicious code.
- Data versioning for back/forward compatible is neglect. As they are designed for quick and easy encoding.
- Efficiency is also an afterthought. (JAVA serialization has bad perf)
JSON, XML and Binary variables
-
Moving to standardized encodings can be written and read by many programming languages, they are popular but with some problems:
- There is a lot of ambiguity around the encoding of numbers-> XML and CSV cannot distinguish between a number and a string who consists of digits ; JSON can do this but it doesn't distinguish integers and floating-point numbers.
- JSON and XML have good support for unicode string, but the don't support binary strings -> as a work around, people encoding the binary data as text using base64, then it can be used. -> increasing data size.
- Optional schema support are powerful but hard to learn and implement. -> some tools don't use schemas -> need to hardcode.
- CSV has no schema and relies on the application to define . -> updating the columns and rows will be manually handled. And the escaping rules are vague.
Binary encoding
- For data used only internally, we could use lower common denominator encoding format for better compaction speed.
- There are some binary implementation for the JSON, but the space gain vs human readability remains to be evaluated.
Thrift and Protocol Buffers
-
Both of the Thrift and protobuf requires schema; using some interface definition language ; this can be done via tools
-
Thrift has two binary encoding :
-
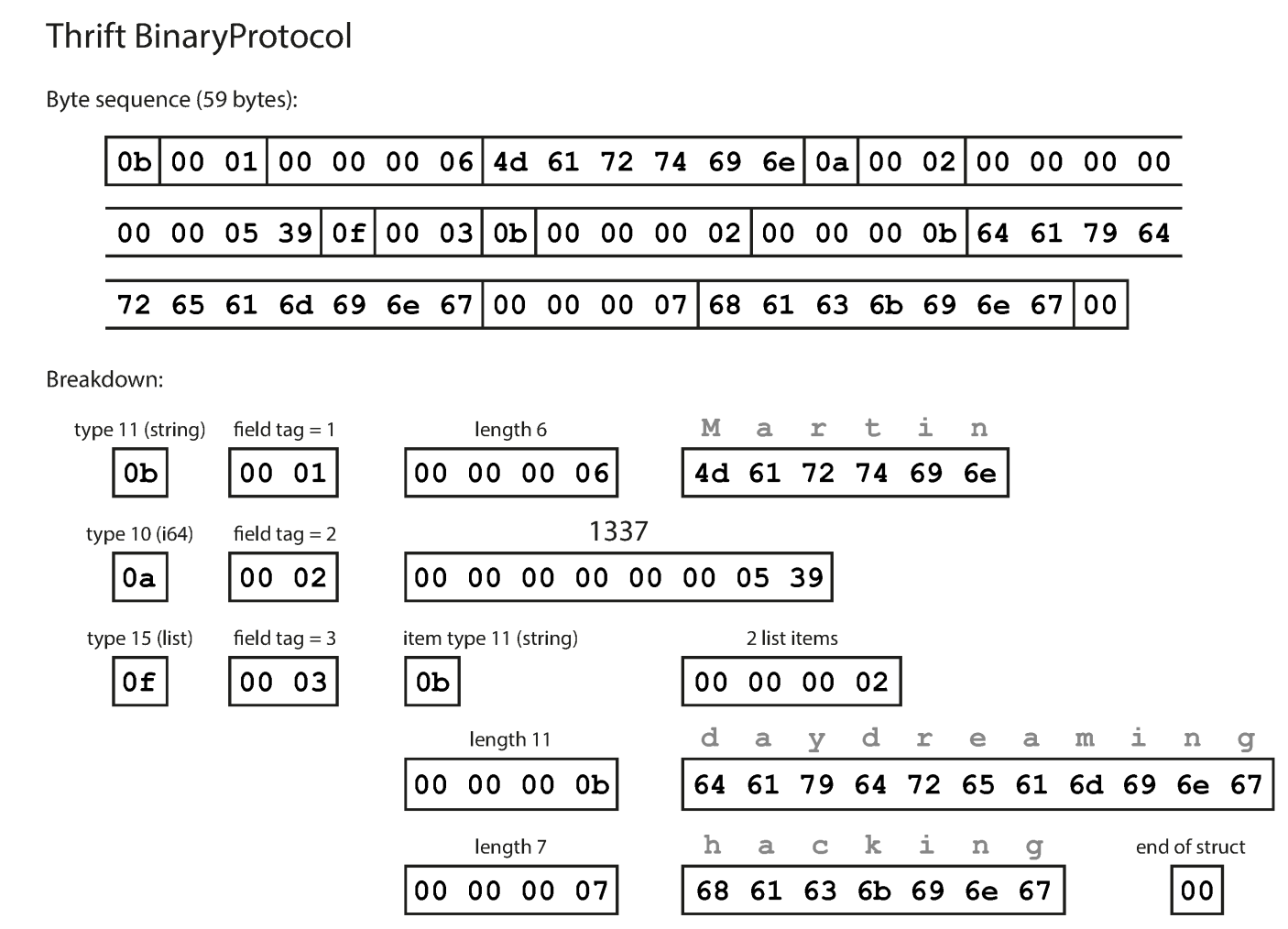
BinaryProtocal
- Field tags are used instead of field name -> tag are referred schema definition
-
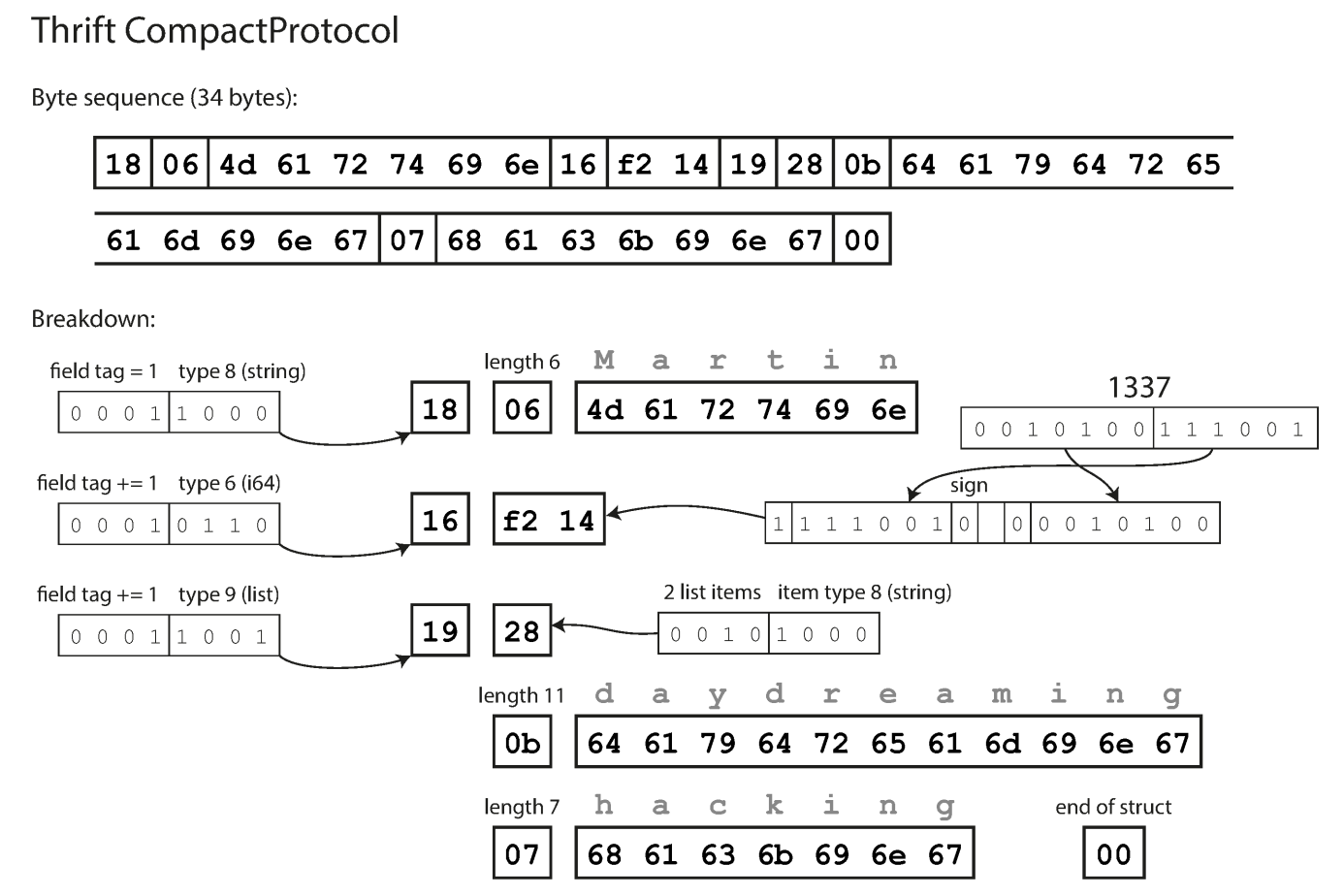
CompactProtocol:
- Compact bytes by packing the field type and tag number into single byte and by using variable-length integers. (Numbers are compact in another level)
-
-
Protobuf: very similar to the compactProtocol.
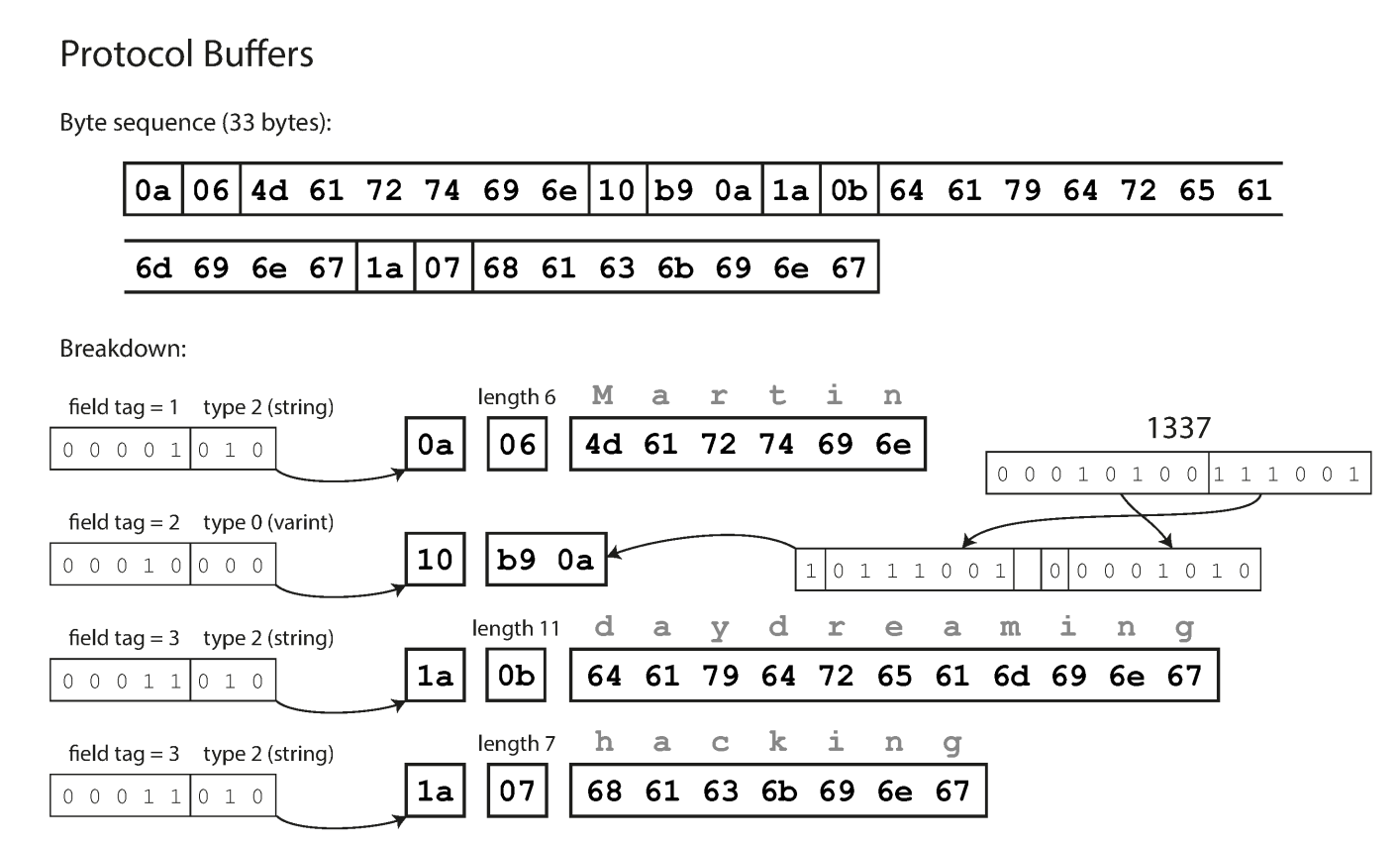
Field tags and schema evolution
- Schema evolution: schema changes overtime inevitably.
- Field tag binds field tag. -> Encoding data doesn't need to change the tags when we update schema, they only change the schema definition
- If we want to add new fields, simply add new field name, and given a new field number. -> forward compatibility-> old code will ignore the new field the don't recognize.
- Old tag still has the older meaning -> so old tag will always read the same old data -> backward compatibility
- Remove field is also like adding new field in forward and backward compatibility, but the removed field cannot be used in the future -> old code may still use the field to populate old field type data.
Datatypes and schema evolution
- Doable but data can be lose precision or get truncated.
Avro
- No tag number (nothing indicate the field type and identify the field)
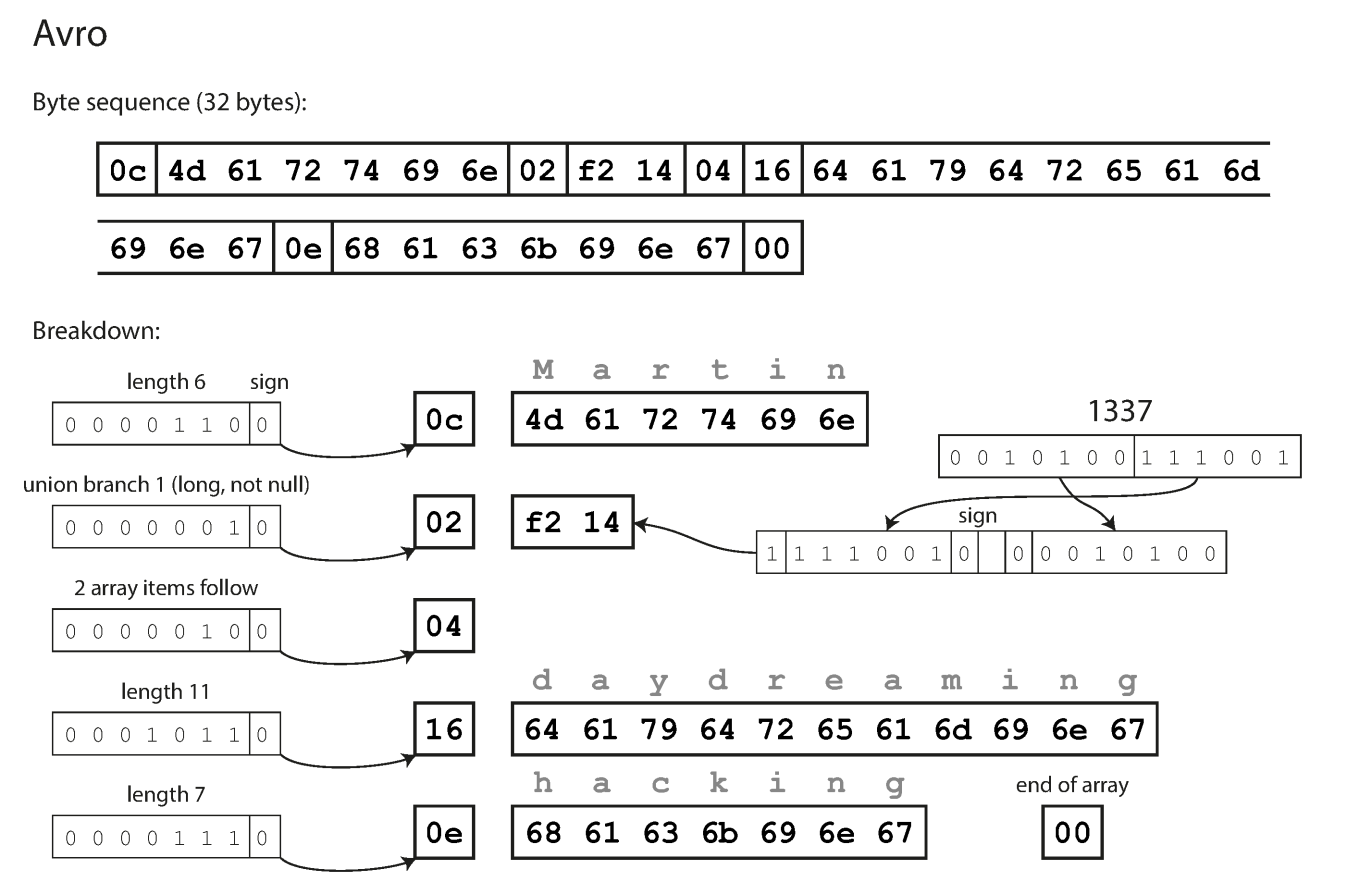
- Data can only decoded correctly if the code reading the data using the exact same schema as the code that wrote the data.
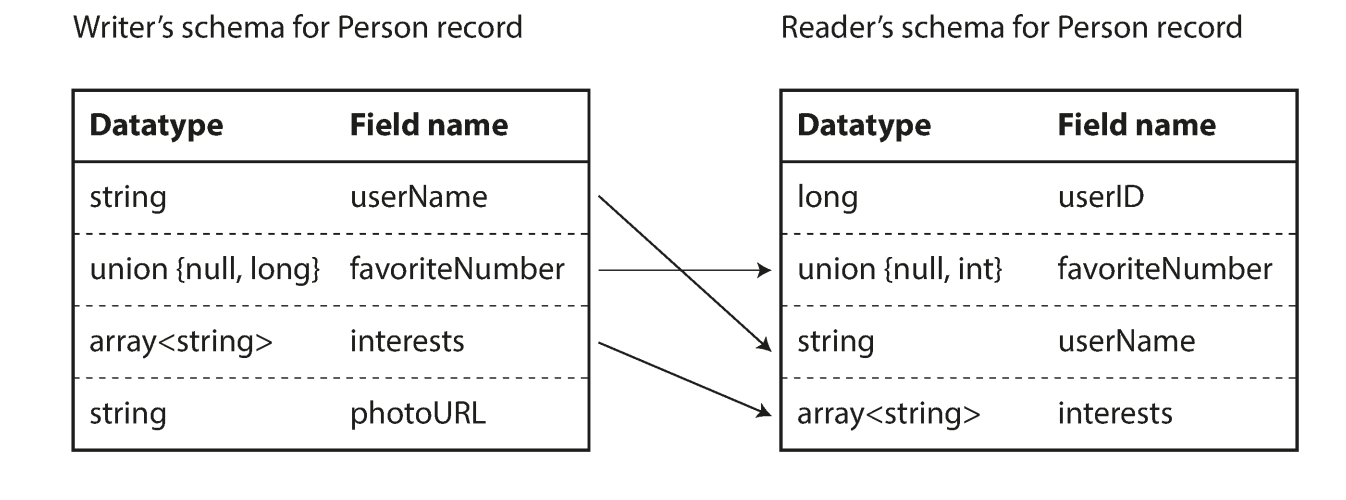
The writer's schema and the read's schema
- They don;t have to be the same, they only need to be compatible
- The don't have to be in the same order since the field are match with field name; if the writers schema has a field thats not in the readers schema, the field is ignored; and if a reader has a desired field cannot be found in the writers schema, a default value will be populated.
Schema evolution rules
-
With Avro, forward compatible means you have a newer writer schema and older reader schema, and in reverse, backwards compatible means you have a older writer schema and a newer reader's schema.
-
You need to add or remove a field that has a default value to maintain the compatibility
- You add a new field, when you read old data with new schema, the should have a default value for that field;
- If you add a new field without default value, new readers would not be able to read data by old writers -> break backward compatibility
- If you remove a new field without default value, old readers would not be able to read data by new writers -> break forward compatibility
But what is the writers schema?
- How does reader know writers schema?
- For large file with lots of records; these are defies at the start of the file format
- In database with individual record, they don;t have the same schema so -> version number to track the schema version for each record
- Sending records over a network connection: negotiate when connection setup .
Dynamically generated schemas
- No tag number is an advantage in some situation -> dynamically generated schemas
- Say you have several database tables and encoded them, each column is a tag;
- If the database schema changes, new Avro schema generated and datas are encoding to new Avro schema, but this doesn't break any old thing, they can still be match with old reader's schema .
Code generation and dynamically types languages
- Code generation: after a schema has been defined, you can generate code that implements this Chema in a programming language of your choice. (Java, C++...)
- -> this allows efficient in memory structures to be used for decoded data and it allows type checking and autocompletion in IDEs when programs that access the data structures.
- In dynamically type languages (python, js...), no point to do the code generation since there is no compile time type checker to satisfy.
- Avro has an optional code generation.
The merits of schemas
- They are more compact since they don't have field name in the encoded bytes;
- The file itself is valuable since they need to be decode and thus we can know if the the bytes schema are latest
- Schema requires you to check backwards and forwards compatibility
- Code generation for static language -> allows compile time type check.
Modes of Dataflow
Dataflow through Databases
- In a database the process that writes to the db encodes the data and the process that reads from db decodes it. -> this process may be single process accessing the db.
- Forwards and backwards compatibility are also often mentioned here.
- New data written ,old code still running(old code should ignore the new values)
- But you need to be aware of it and may need to take care of them at the application level.
Different values written at different times.
- Data outlives code: some code are very old and still exiting in the database ;
- Migration to new schema might be expensive for large data set and can be done by simply populate null for old rows of new column.
Archival storage
Take a snapshot of database: say backup for loading into data warehouse -> using latest schema.
Dataflow through Services : REST and RPC
Web service
- REST : design philosophy , emphasizes simple data formats, using URLs for identifying reduces and using HTTP features for cache control, auth and content type negotiation.
- SOAP: avoid using HTTP features -> independence -> comes with complex standards.
- The API of a SOAP web service is described using an XML-based languages called the Web Services Description Languages -> WSDL.
- WSDL enable code generation to access remote service using local classed and method calls (encoded to XML message and decoded again by the framework)
The problems with remote procedure calls (RPCs)
- A network request is unpredictable(network problems.. ) compared with local methods.
- A network request may not have any returns due to timeout and you don't know if the request processed
- Retry will cause issue , considering of idempotency
- The execution time of network request is unpredictable
- The parameter would be a big issue if they are large
- Translation may needed if client and server using different languages implementation.
Current directions of RPC
Some customization in the industry implementations that can mitigate the flow of problems above in same extend
Data encoding and evolution for PRC
- You need backwards compatibility on request and forwards compatibility on response -> based on that server will be updated first.
- In RESTful, adding optional field are considered maintain compatibility
Message-passing Dataflow
- pros
- Buffer when a recipient is unavailable or overload -> improve reliability
- Redeliver message to processed that has crashed -> prevent message being lost
- Separate sender and received -> useful in a cloud deployment where virtual machine often comes and go
- One message can be sent to several recipients
- Logically decouple the sender from recipient
Message brokers
- Message broker : is used : one process sends a message to a named queen or topic, and the broker ensures that the message is delivered t one or more consumers of or subscribers that queue or topic. There can be many producers and many consumers on the same topic.
- A topic provides only one-way dataflow. However a consumer may itself publish message to another topic. Or to a reply queue that is consumed bu the sender of the original message. -> similar to request/ response
- Message brokers doesn't enforce any particular data models -> message os just a sequence of bytes with some metadata .
- If the consumer republish message to another topic , the encoding needs to be noticed.
Distributed actor frameworks
- Actor model is a programming mode for concurrency in a single process Rather than dealing with the threads, logic is encapsulated in actors.
- In distributed actor model, this model is used to scale an applcaition across many nodes.
- Location transparency is better in actor than RPC -> it assume message never lost.
- Distributed actor mode : combine actor mode and message broker -> need to consider compatibility when rolling upgrade.
- Some examples :
- Akkas in Java
- Orleasn
- Erlang OTP