- Replication of database helps in many aspects
- Scalability -> spread increasing data load
- Fault tolerance/high availability -> one down, another take over;
- Latency/performance-> multiple datacenter across world might help avoid network travel across the earth;
- Scale to higher load:
- Shared memory (powerful machine): cost grow fast; limited fault tolerance -> vertical scaling
- Shared disk: several independent CPU and a shared disk(they are connected via network): may suffer from lock
- Shared nothing : horizontal scaling , has many nodes(machines) with their own CPU and disks;
- Data being distributed across machines to reduce latency and
- Survive from loss of entire datacenter
- Has tradeoffs though
Replication vs petitioning
Replication: keep a copy of the same data on different nodes, potentially in different location
Partitioning : splitting a big database into smaller subsets called partitions so the different partitions can be assign to different nodes. (Also known as sharding)
Chapter 5 we discuss replication and chapter 6 we talk about the partitioning; ch7 is about transaction (data system might go wrong), and in ch8 and 9, further fundamental limitations of distributed system.
DDIA Chapter5 Replication
Leaders and Followers
-
Replica: node that stores a copy of the database
-
How do we ensure all the data is in the replica in the end ? -> leader-based replication
-
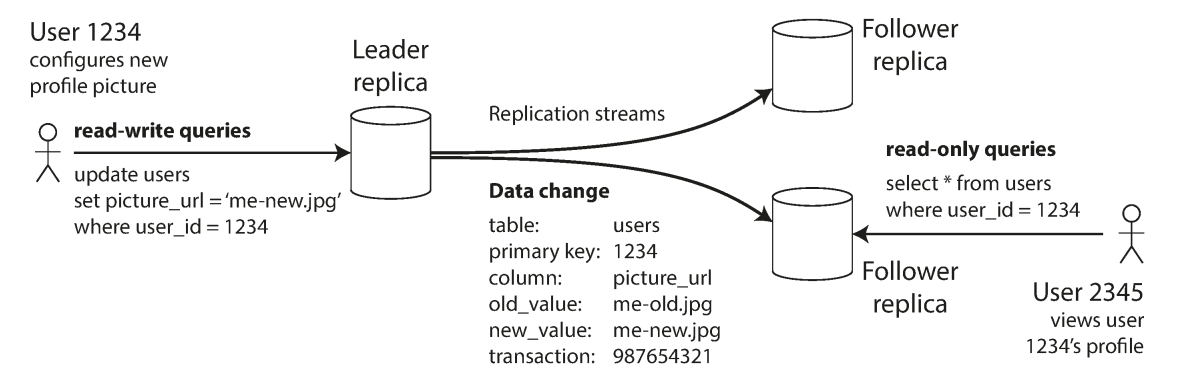
Leader based replication :
- We define a leader ; all the write must go to this node;
- Others node are followers, whenever a leader writes to its storage, it also send the data changes(replication log or change stream) to all its followers.
- Each followers takes the log and update its local copy of the database, by applying all write in the same order.
- When a client wants to read, any nodes can accept the request since all the nodes has the same data.
-
This mode is build-in feature in many relational DBs : PostgreSQL, MySQL, Oracle Data Guard, and SQL Server's AlwaysOn Availability Groups. And some non relational DB including MongoDB, RethinkDB and Espresso. -> and finally some other architecture: Kafka and RabbitMQ highly available queues.
Sync vs Async Replication
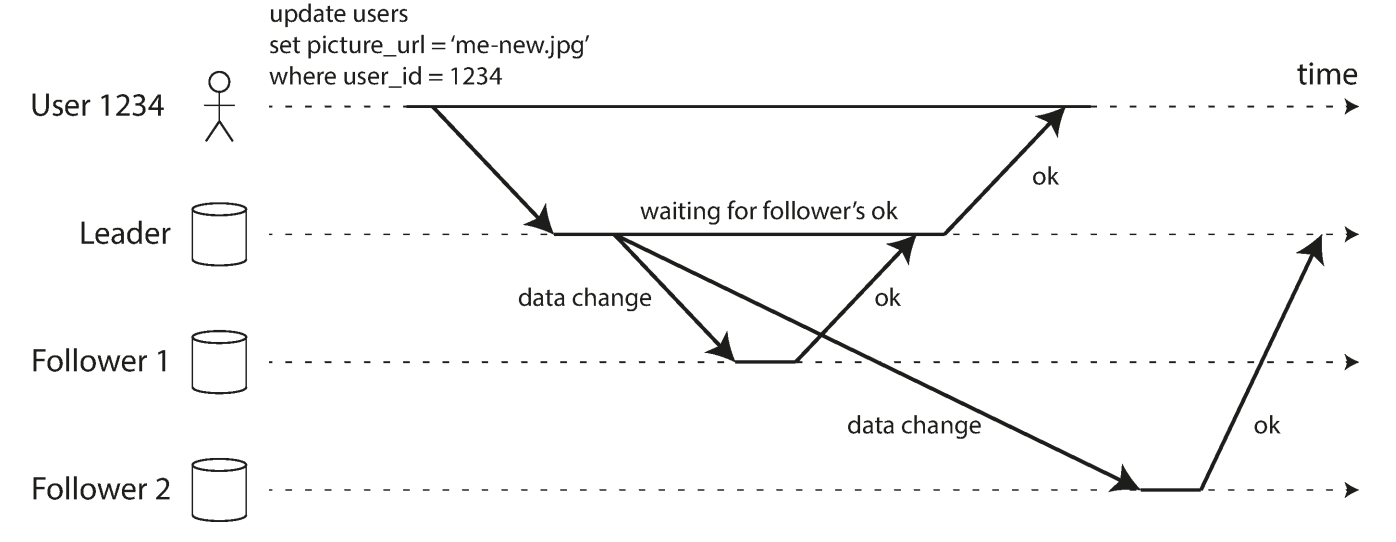
- The process of replication from master to follows when there is a new change for updating a picture.
- The replication of follower 1 is synchronous, the master wait until follower1 confirmed that it received the write before the master reporting success to the client and before making the write visible to other clients.
- The replication of follower2 is asynchronous : the leader sends the message but doesn't wait for a response from the follower.
- There is a delay before follower2 process the message
- This delays could be small
- But no guarantee on the delay so it might be large due to
- Follower is recovering from a failure and takes time to process the message
- The system is operating near maximum capacity
- The network problems between nodes.
- Pros &Cons:
- Pro: Followers is guaranteed to have latest copy of the data (consistent with leader)
- Con: if the follows don't respond, the write cannot be processed ; the master needs to block upcoming writes and wait until the synchronous replica is available again.
- In practice , if you are using synchronous replication -> this is saying we have one of the followers synchronous and others a async; -> so you have a t least two node have up-to-date data; and less chance of writes are being blocked due to the followers issue. -> semi-synchronous
- Leader based replication are often configured to be completely async. If the leader fails and not recoverable, any writes that not ye been replicated to the followers are lost. -> write is not guaranteed durable. -> but , the pro is that leader can nevertheless continue processing writes no matter how many followers failed.
Setting up New followers
- If a new node added and start to copy from master, -> there will be always new wires to leader and new node needs to constantly catching up;
- Locking db makes the system unavailable
- So normally the process is :
- Take a snapshot at some time point of db without locking db(like MySQL innobakcupex)(many db has this function )
- Copy the snapshot to the new follower node;
- The followers connects to the leader and request all the data changes happened after the time point -> this requires the snapshots is associated with an exact position int he replication log. (Log sequence number in PostgreSQL and binlog coordinates in MySQL)
- When the followers has processed the backlog of data changes since the snapshot we say it catch up , it's now continue to press data changes from leader
- The steps varies by database , some are fully automated while some are complex manually workflow.
Handing Node Outage
Follower failure : Catch - up recovery
- When a follower recovered from failure or something, it requests the change from leader before the fault occurs and apply all the changes. After this, it catches up to the leader and can continue receiving a stream of data changes as before .
Leader failure : Failover
- Failover: New leader promoted; clients direct traffic to the new leader; followers starts consuming data from new leader
- The failover can happen manually(admin notifies a leader failed and promote a new leader) or automatically
- Automatically failover :
- Determine the leader has failed; many reasons can cause this so often take the timeout as an evidence -> nodes talk to each other , and it's been some time that one node not responding.
- Choosing a new leader -> normally the replica with up to date data -> can be done by a election process or a previously elected controller node;
- Reconfigure the system to user the new leader : clients send request to the new leader and followers get data changes from the new leader
- Things can go wrong when :
- In async replication, a not up to date replica is elected as a new leader ; while the original leader come back and joins as a follower, but it has more newer data; how to handle the data? -> simply discard -> can violated durability
- Discarding data can be dangerous if other storage systems outside of the database need to be coordinated with database contents : In a Github incident, an out-of-date MySQL followers was promoted as the new leader and it use an incrementally counter as the PK, since its out-of-date date and the PK was gendered, where some are already assigned. -> these keys are used in bother db and redis, which causes private data disclosed to the wrong users.
- Split Brain: two node thinks they are leader -> can lead to data break -> some system can detect if more than one leader exists and shut down one -> needs carefully design in case of all the leader are shutdown.
- Right timeout to declare a leader is dead? Longer timeout means longer time to recover but short time can cause unnecessary failover. -> if the system is struggling with big load and becomes slow, the it's regarded as timeout and failover , though it's unnecessary
Implementation of Replication Logs
Statement based replication
- Logs every writes and send to followers
- Nondeterministic function such as
NOW(), is likely to generate a different data - If statements depends on some existing data in the database ; -> they must execute the same order on each replica -> this can be limiting when there multiple concurrently executing transactions
- Statements has side effects (triggers , stored procedures, UDFs,) may result in different side effects unless the side effects are absolutely deterministic
- Nondeterministic function such as
- There are work around but still have many Conner cases
- MySQL uses it before , VoltDB uses it and make it safe by requiring transactions to be deterministic
Write Ahead log(WAL) shipping
- A write , beside write to node disk, but also send via network to its followers -> used in ProstgreSQL and Oracle -> cons: very low level , defines which disk block stores which bytes , so bind to db engine and no possible to switch to other version.
- Zero downtime cannot happened if you don't allow different version of leader and slaves.
Logical(row-based) log replication
- Logical log vs physical log (previously), decouple with storage engines
- A sequence of records at the granularity of a row:
- Inserted row -> log contains new value of all columns
- Deleted row, log contains information(PK, or all the old values if no PK) to uniquely identify the deleted row
- Update row, log contains information(new values) to uniquely identify the updated row
- MySQL binlog: a transaction with several change generated several rows of log, with a row indication the transaction is done
- Decouple from storage engines internal -> can switch to different version even engine
- Logical log format is also easier for external application to parse -> when send to a datawarehouse or change data capture
Trigger Based replication
- Application layer defined: more flexible : want replicate subset of data , or to another database engine or m needs to handle write conflict
- Reading database log vs use trigger and stored procedure
- Trigger can log the change in another table
- Has greater overheads and bug pruned and limitations
Problems with Replication Lag
- Replication goals: availability, scalability and low latency
- For reading scaling architecture , where many more reads than write, you can increase the scalability by adding more followers to handle the requests.
- This only works for async replication since in sync replication, any node failure will cause the system blocked.-> increasingly likelier of down
- And in async replication, the slave may have out of date data -> however if you wait for a while and request follower again, its data may be up-to-date -> eventually consistency
- Eventually is vague it doesn't tell how long will be consistent
Reading you own Writes
-
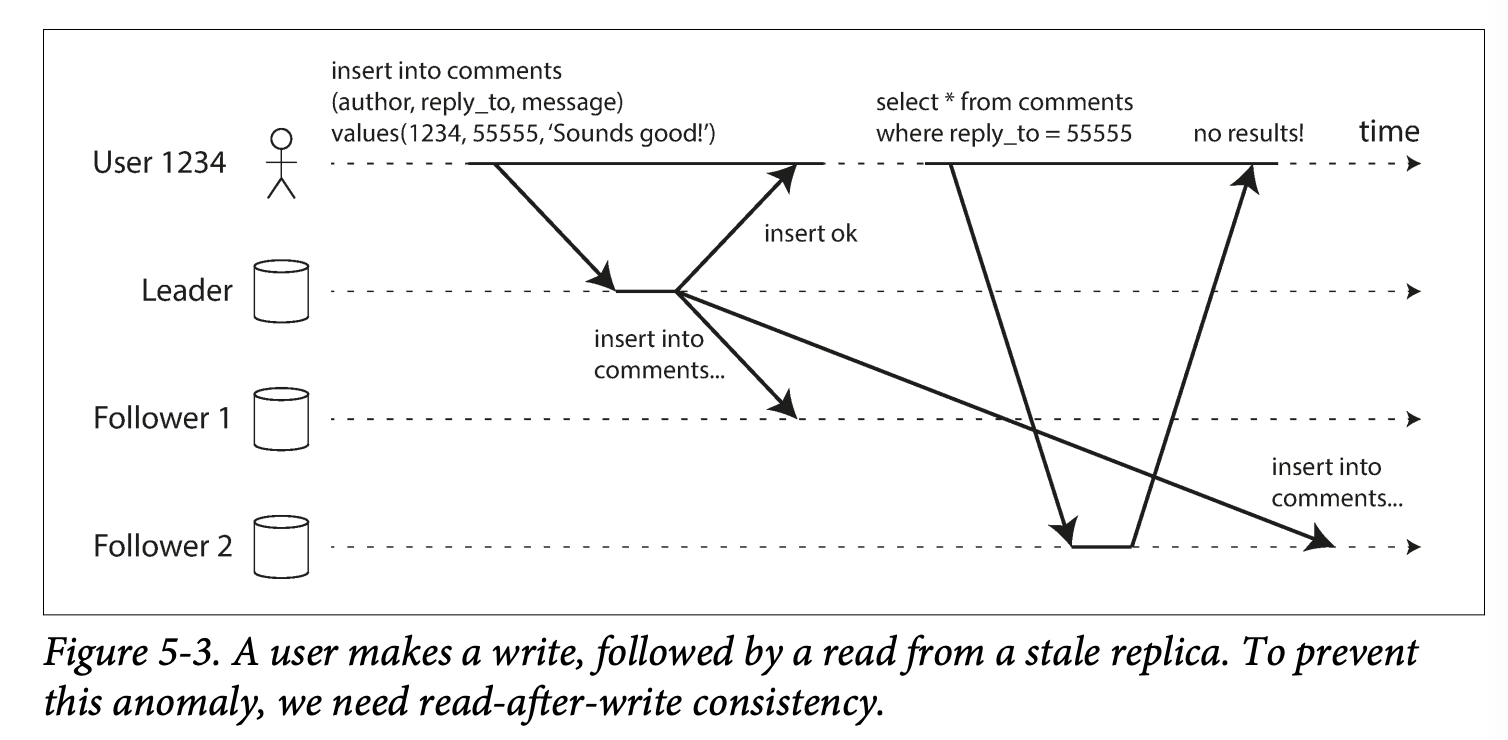
Application like comment system let user submit data and let them view the submitted data. The leader accepts the write request, but the follower may receive the read request
-
An issue arise when there is replication lag. User doesn't see what it has submitted just now.
-
Read after write or read your write consistency : this guarantees this user to see the data but not other users.
-
How to implement?->
- When something changed, read from leader otherwise read from follower . -> this requires you know some thing changed without querying it. -> tricky-> user profile is only editable for user themselves so read for this can only go to leader
- If most of things can be edited bu many users then this approach 1 is not useful. -> some other thing needs to be referred . -> you can track last update time and all the read 1 min after the read goes to the leader. (Or you can monitor the replication lag on followers and prevent queries on followers more than one minute behind the leader)
- Client can remember a timestamp of its recent write. -> then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp.
- If the replica is not up to date, the client can wait or goes to another replica.
- If the replica are distributed across datacenter, then any request to to the leader needs to be routed to the right data center.
-
Another issue is single user access data using different devices :
- Client don't know each other timestamp of write in their local , which may need be centralized
- If Replicas across different data centers, it's not guaranteed request of single user from different device will be routed to the same center. -> you may need to route the request to the leader data center first if needed
Monotonic Reads
-
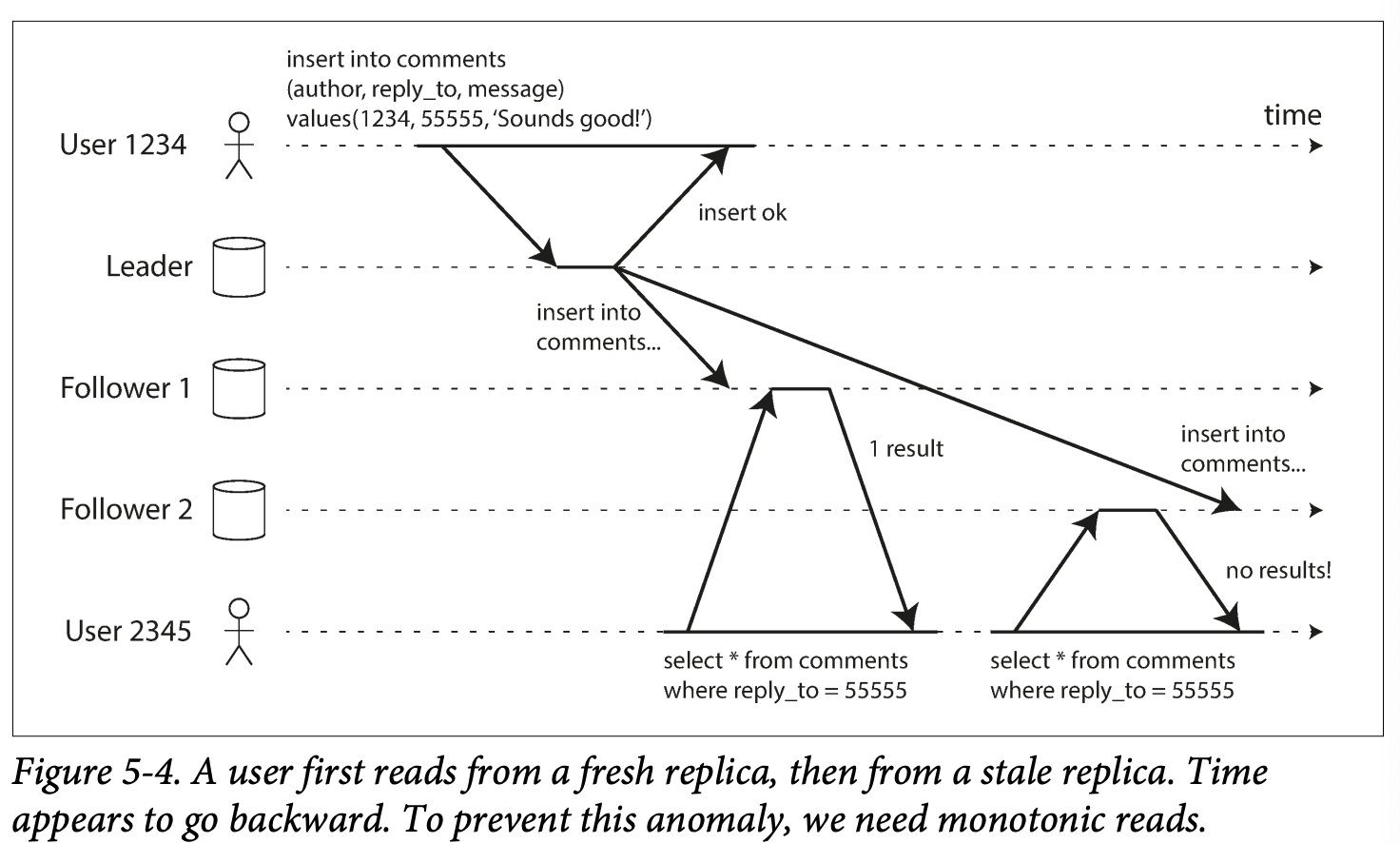
User see thing moving backwards in time
-
e.g they make a request and the refresh page and make another request, the requests are routed to different node.
-
User 1234 make comments, its replicated to follower1, user 2345 read the comments and find the new comment , then make a another read but the request routed to follower2, at that tome the comment isn't replicated to the slave and user 2345 didn't find the comment, which is confusing
-
Monotonic reads guarantee user will not see older data
-
Implementation: make sure same user make reads from the same replica; the replica can be chosen based on a hash or user ID, rather than randomly
- If node failed , user request will never to another replica.
Consistent prefix reads
-
If a sequence of write happens in a certain order, then anyone reading those writes will see them appear in the same order
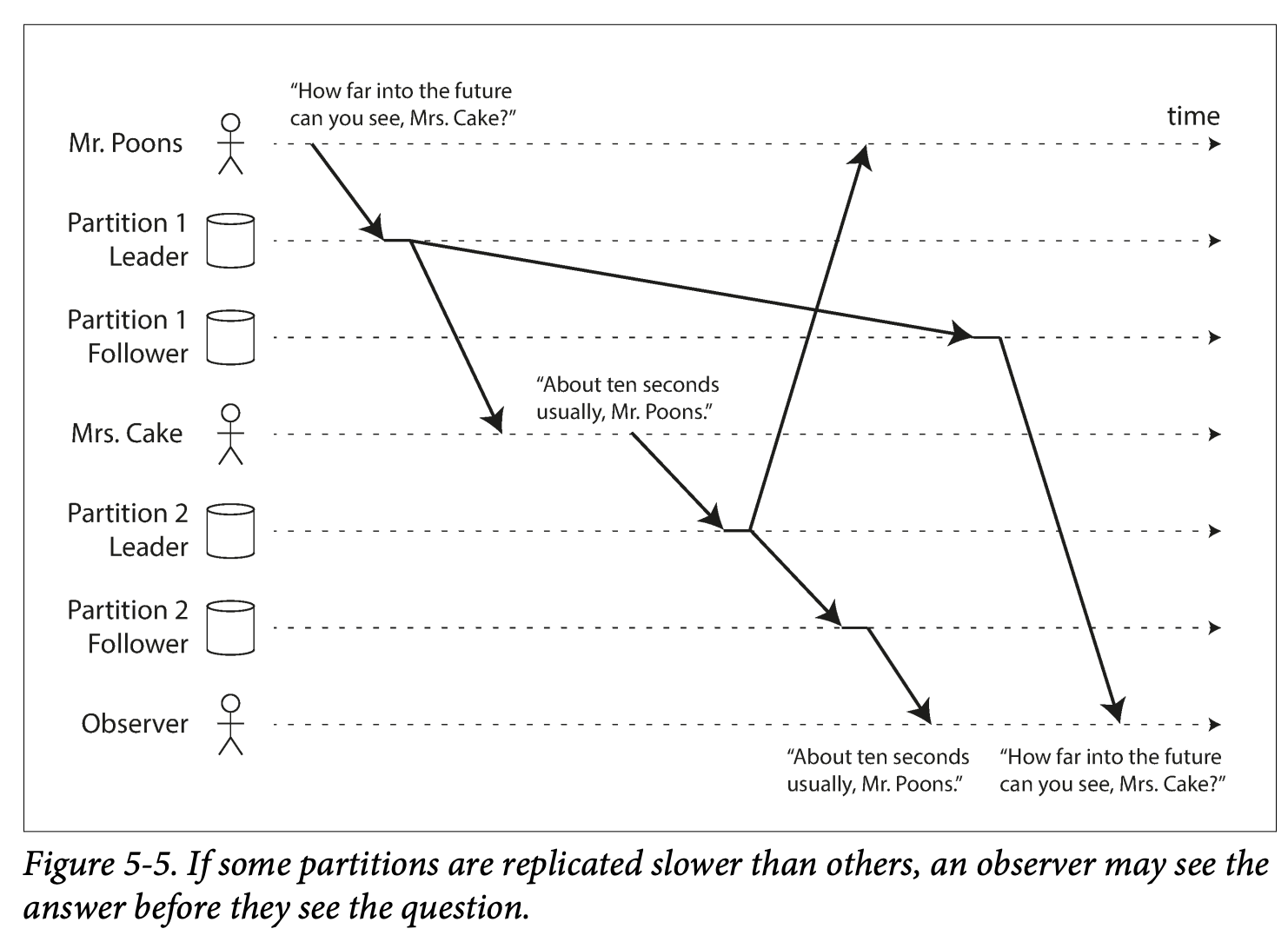
-
Solution : write with causality relation write to the same partition.
Solutions for replication lag
- We discussed ways can somehow gureantted the consistency , but those requires additional complex in code and application
- Database handle this with transaction , providing a stronger guarantee, while free developers , but they undermine performance significantly
- More to discuss in the future chapter
Multi-leader replication
- Multiple node accept writes as leader; and they act as follower as other leaders.
Use cases for multi-leader replication
Normally it's not used in single datacenter for it's adding complex more than benefits
Multi-datacenter operation
You have a database with replicas in many datacenter
-
In single leader configuration, leader must reside in a datacenter and all the writes must go through that datacenter .
-
In multi-l leader configuration, you can have leader in each datacenter: within in each datacenter, regular leader - follower relocation is used ; between datacenter, each datacenter's leader replicates its changes to the leader in other data centers.
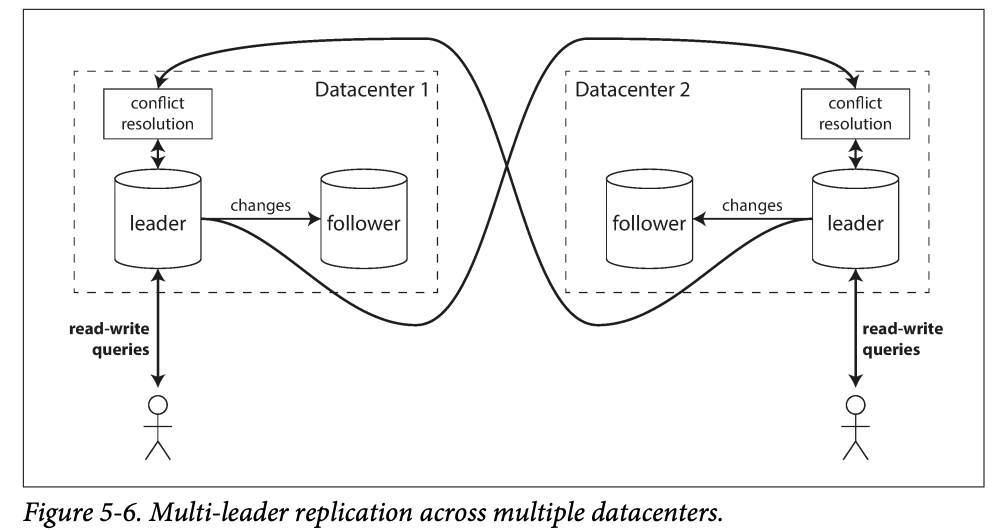
-
Pros:
- Performance: all the writes go over the internet to the datacenter with leader in single leader configuration ; while in multiple leaders , writes are process in local datacenter, and writes are replicated asynchronously to the other damtcenters. -> this may let the performance better
- Tolerance of datacenter outrages : single leader will have failover when data center of leader is down while multiple leaders scenario, others will continue to work , and when the failed datacenter is back, the replication catches up
- Tolerance of network problems : for single leader, the request is sensitive to the network condition since the traffic among datacenter are sync(they need to find the leader datacenter) ; while in multiple leader configuration, since they are async replication, it can tolerate temporary network issues
-
Cons: the same data may be concurrently modified in two different datacenters -> those conflicts needs to be resolved
-
Some database has this in default some has addition implementation with external tools Tungsten Replicator for MySQL, BDR for PostgreSQL, and GoldenGate for Oracle.
-
This multi-leader configuration has many pitfalls so it should be avoid if possible
Clients with offline operation
- Say you heve calendar app and you need user see the meetings no matter it's online ,and the change can be synced to other devices when it;s next online
- In such case, every device has a local database that acts as a leader , and there is an async multi-leader relocation process between replicas in different devices -> Each device is a data center
- CouchDB is design for this mode of operation
Collaborative editing
- Realtime collaborative editing apps allows several people;e edit a document simultaneously
- We don't see it;s a database replication problem but they have many in common : when user edit the docs the change reflect immediately in their local replica , and asynchronously replicated to the server and other users who are editing the doc
- If you want to guarantee there is no conflict , the application must obtain a lock when a user is editing , if another user wants to edit the same doc , they have to wait for the other user committed and release the lock. -> this is like a single leader replication with transactions on the leader .
- For faster collaboration, you may want to make the unit of change very small (a single keystroke) and void locking. This approach allows multiple users to edit simultaneously but also bring all the challenges of multi-leader replication including requiring conflict resolution
Handling Write conflicts
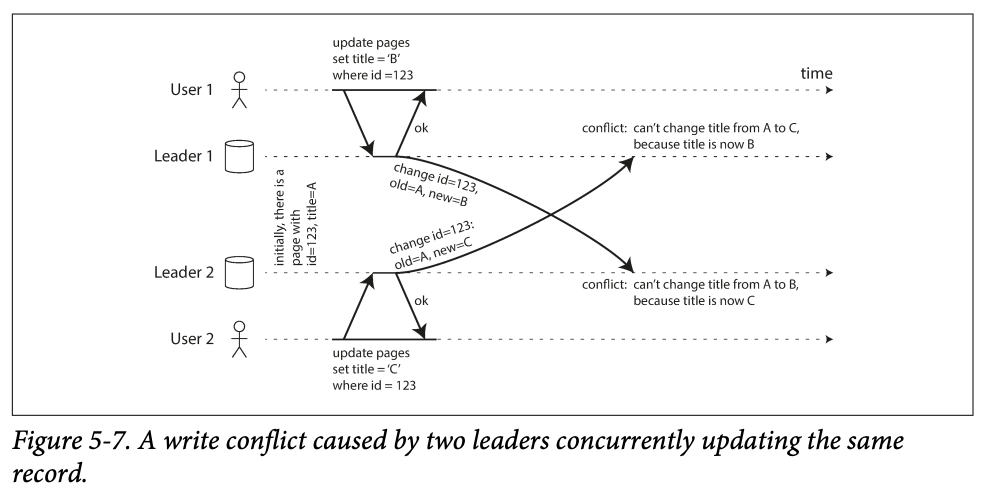
Synchronous vs async conflict detection
- In single leader database, the second writer will either block and wait for the first write to complete ; or abort the second write transition, forcing the user to retry the write.
- In the multi leader , both write are successful and will be detected later
- So you can make the conflict detection synchronous -> wait for the rewire to be replicated to all replicas before telling the user the write was successful -> lose the advantage of each leader can accepts write independently
Conflict avoidance
- Avoid conflict if possible is better than detect them after this happens
- e.g. in an application where user can edit their own data, you can ensure a particular user's requests are always routed to the same datacenter and user the later in that datacenter for read and write . -> different users use different datacenter(perhaps based on geographic proximity to the user) -> this is essentially single leader
Converging toward a consistent state
- All replicas must arrive at the same final value when all changes have been replicated.
- Ways of achieving this :
- Give each write unique ID , duck the write with a highest ID as the winner and throw away to other writes . If timestamp is uesd, this is known as air write wins(LWW) -> dangerous -> data loss.
- Give replica an ID and higher ID has higher priority of writing. -> data loss
- Records all the conflict data and introduce additional application code to handle this .
Custom conflict resolution logic
- On write : as soon as the database system detects a conflict in the log of replicated changes , it called the conflict handler.
- On read : conflict writes are stored and next time data is read , these multiple versions of the data are returned to the application (CouchDB)
- Conflict resolution usually applies at the level of an individual row or file but not a transaction
What is a conflict
- Two user changes the same data concurrently and changes to different values
- More subtle : same meeting room booking by two people at the at the same time from two leaders.
Multi-leader replication topologies
-
The replication topologies describes the communication paths along which write are propagated from one node to another
-
If you have only two leaders : the topology would be like lead 1 must send all traffics to leader2; while if you have many leaders, you can have these :
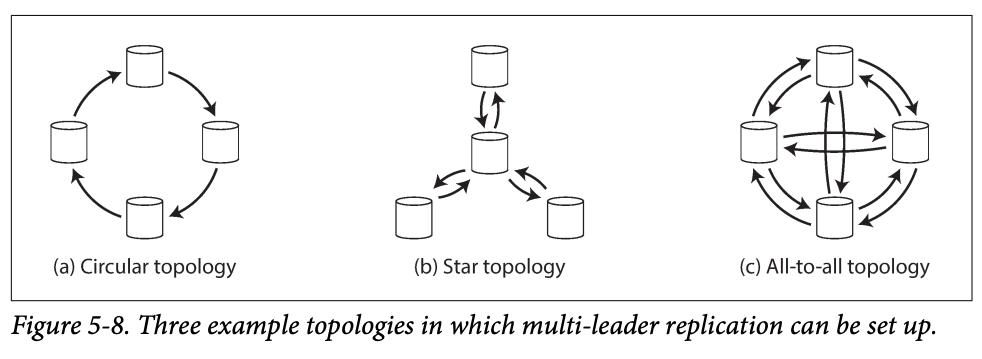
-
Circular and star topology, their nodes needs to pass writes to others and read from others, so to avoid infinite loop, they have an ID for each node and each write is tagged with the id of at the nodes it has passed through. -> to ignore processed
-
These two topoes are fragile , if one node is down, the system might down.
-
The issue of all to all (multi -leader ) is that : some writes has dependency but they arrives at the wrong order . -> Causality
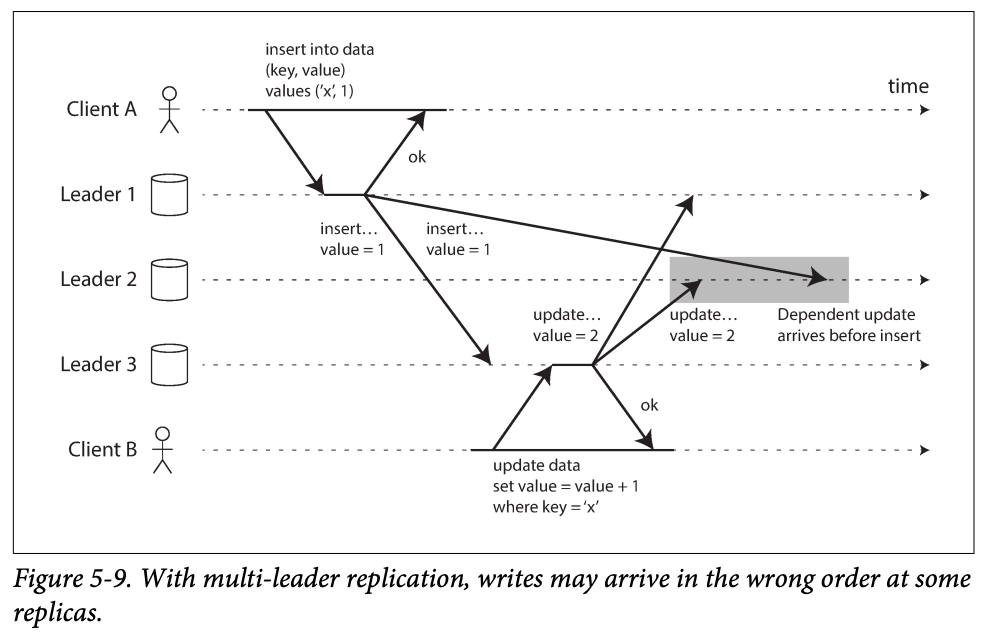
-
Version vectors are used to order these events ; however conflict detection is poorly implemented so be careful when you use multi-leader replication
Leaderless Replication
Dynamo-style
Writing to the database when a node is down
- Failover doesn't exist
- The user send request to all the replicas, and 2 of 3 received the request and response so it regards this request is successful -> quorum
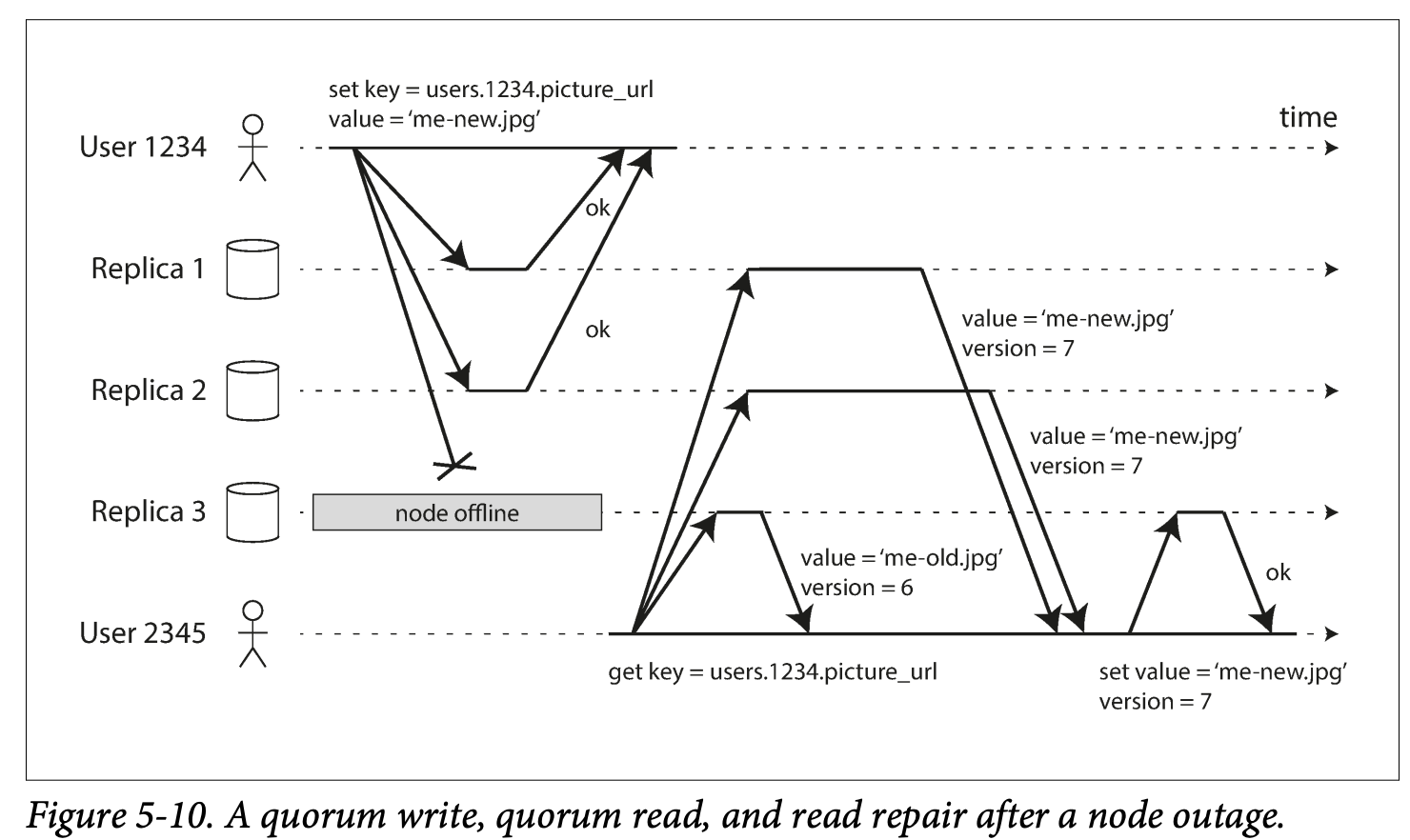
- When the failed node comes back, it may has out dated value, when a read request to it, it may return an outdated value -> so the read request is also send to all the nodes and all the returned value has a versioning number which can tell the user who is the latest data
Read repair and anti-entropy
- How does a unavailable node catch up when it's back ?
- Two mechanism ins dynamo-style datastores :
- Read repair : when a client makes a read form several nodes in parallel, it can detect any stale response .-> by version number -> work well for the values that are frequently read
- Anti-entropy process: a background process that looks for difference in the data between replicas and copies missing data from one to another -> no order , may be delay
- Not all system has those two mechanisms
Quorums for reading an writing
- If there are n replicas, every write must be confirmed by w nodes to be considered successful, and we must query at least r nodes for each read. -> as long as w + r > n, we expect to get an up-to-date value when reading
- In dynamo-style the number is configurable; and make a n an odd number, w = r = (n + 1) /2 (thus w + r > n);
- You can also specify your w , r; for example you have many read and few writes, you can benefit by setting w = n and r = 1; reads are fast but one write fail cause all write fail
- In w + r > n situation :
- If w < n, we can continue process writes if a node is unavailable
- If r < n, we can continue process reads if a node is unavailable
- With n =3, w = 2, r = 2, we can tolerate one unavailable node;
- With n =5 w = 3 r = 3 we can tolerate two unavailable node;
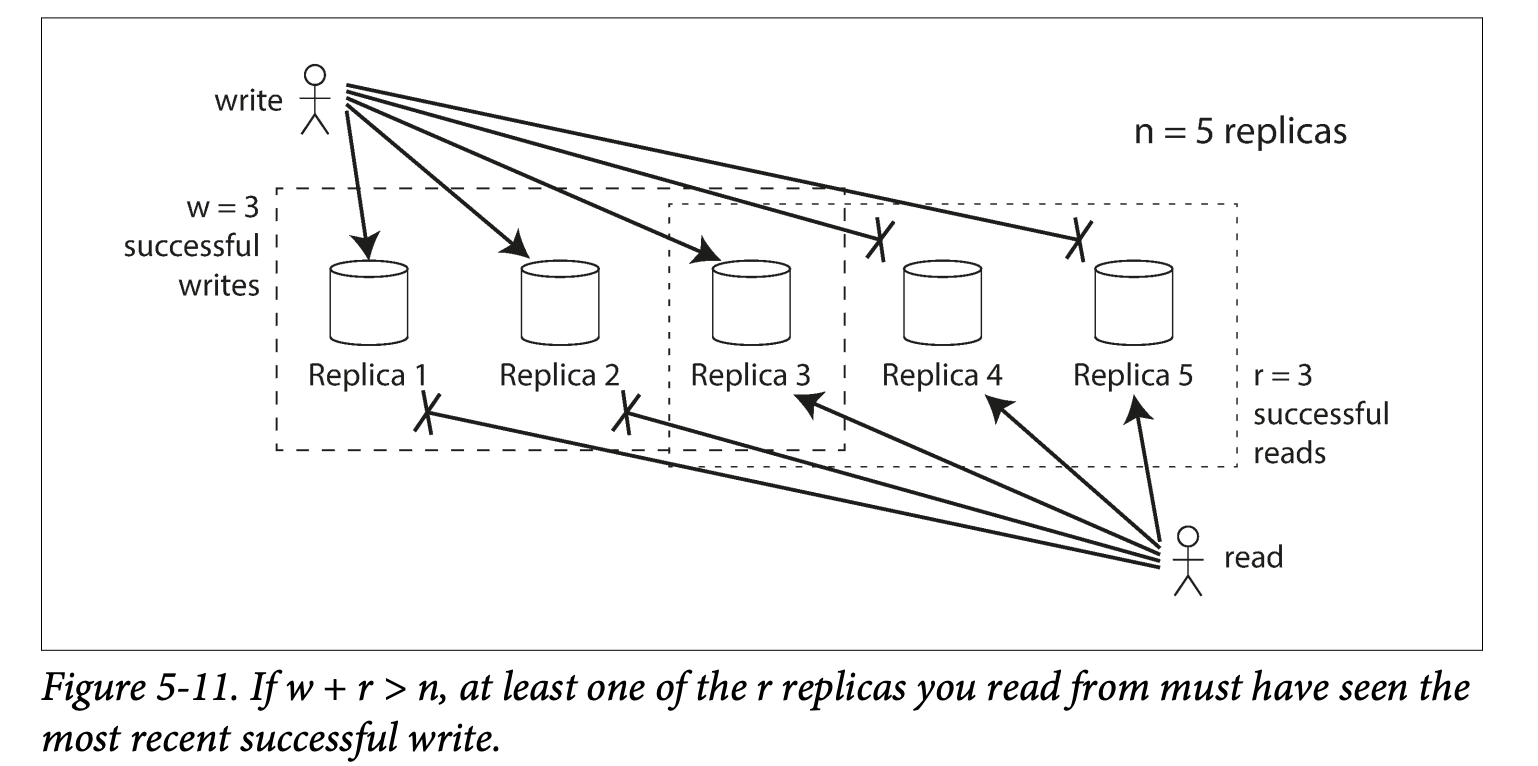
- Normally writes and read are sent to replicas in parallel
- If there are less than w or r replicas, system will return error , reasons are
- Replicas shut down (crash or outrage)
- Error executing the operation (such as due to disk full )
- Network between client and server
Limitations of Quorum Consistency
- The quorum are not necessarily majorities, it only matters that the sets of nodes used by the read and write operations overlap in at least one node.
- W + r can be smaller than n, in this case , reads and writes will still be sent to n nodes but smaller number of successful responses is required for the operation to be succeed.
- You have higher chance to read the stale values. But the pro is that it allows higher availability and lower latency since you don't depends on many nodes, if there are network issue or some replicas are unreachable, you have higher chance to continue processing the reads and writes .
- Even w + r > n, changes are there that stale values are returned :
- A sloppy quorums(n machines changed) is used, writes node are no longer overlapped with read nodes.
- If two wires happened concurrently , it's node clear which one happened first in this case, the safe solution is merge the concurrent wires -> winner picked and some writes may be lost
- If a write happens concurrently with a read, the write may be reflected on only some of the replicas, in this case, it's undetermined whether the read returns the old or the new value (you don't know if the user request which one)
- If a write succeeded on some replicas but failed on others, and overall succeed on fewer that w replicas, it's not rolled back on the replicas where is succeeded. -> if a write was reported failed, subsequence reads may or may node return the value from that value .
- If a node carries a new value fails , and its data is retread from a replace carries na old value, the number of replicas stored the new value may fall below w, breaking the quorum condition.
- Even if veering working correctly, there are edge cases in which you can get unlucky with the timing .
- So don't take the w and r as absolute guarantee (even they can affect the chance you get stale values)
Monitoring staleness
- You need to know if your database are returning stale values from an operational perspective
- For leader-based replication, the database typically expose metrics for the replication log , -> you can feed into a monitoring system -> by comparing the difference of the leaders position and slaves position (position means the number of writes it writes so far )
- In leaderless replication, there is no fixed order which dirties are applied. -> makes monitoring difficult
Sloppy Quorums and Hinted Handoff
- Leaderless replication : low latency , hight availability and with occasional stale reads
- A network cut off the client and some nodes , even thought the nodes are alive -> they might be treated as dead -> in the situation, there are fewer w and r reachable node remain -> no longer reach a quorum
- You have two choices:
- Returns error
- Or accepts writes anyway and write them to some other reachable nodes but not among n nodes -> sloppy quorum
- Sloppy quorum: writes and read still requires that w and r successful response , but those may include node that are not among the designated n nodes.
- Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate "home" nodes. -> hinted handoff
- Increasing availability , but even when w + r > n , you cannot guarantee read the latest value for a key. -> latest value are temporarily write to some other node outside of n home nodes.
Multi-datacenter operation
- Leaderless replication is suitable for multi-datacenter operation, since it's designed to tolerate conflicting concurrent writes network interruptions and latency spikes.
- Cassandra and Voldemort implement their multi-datacenter support within the normal leaderless model :
- the number of replicas n includes all the nodes in all data centers, and you can configure the number of nodes in each center .
- Each writes send to all data centers but only requires a quorum of node within local datacenter -> so it will not effected by the cross data center link
- Riak keeps all communication between clients and database node local to one datacenter , so n describe the number of replicas within in one datacenter. Cross datacenter replication between database clusters happens async in the background (like the manner in multi-leader replication)
Detecting concurrent Writes
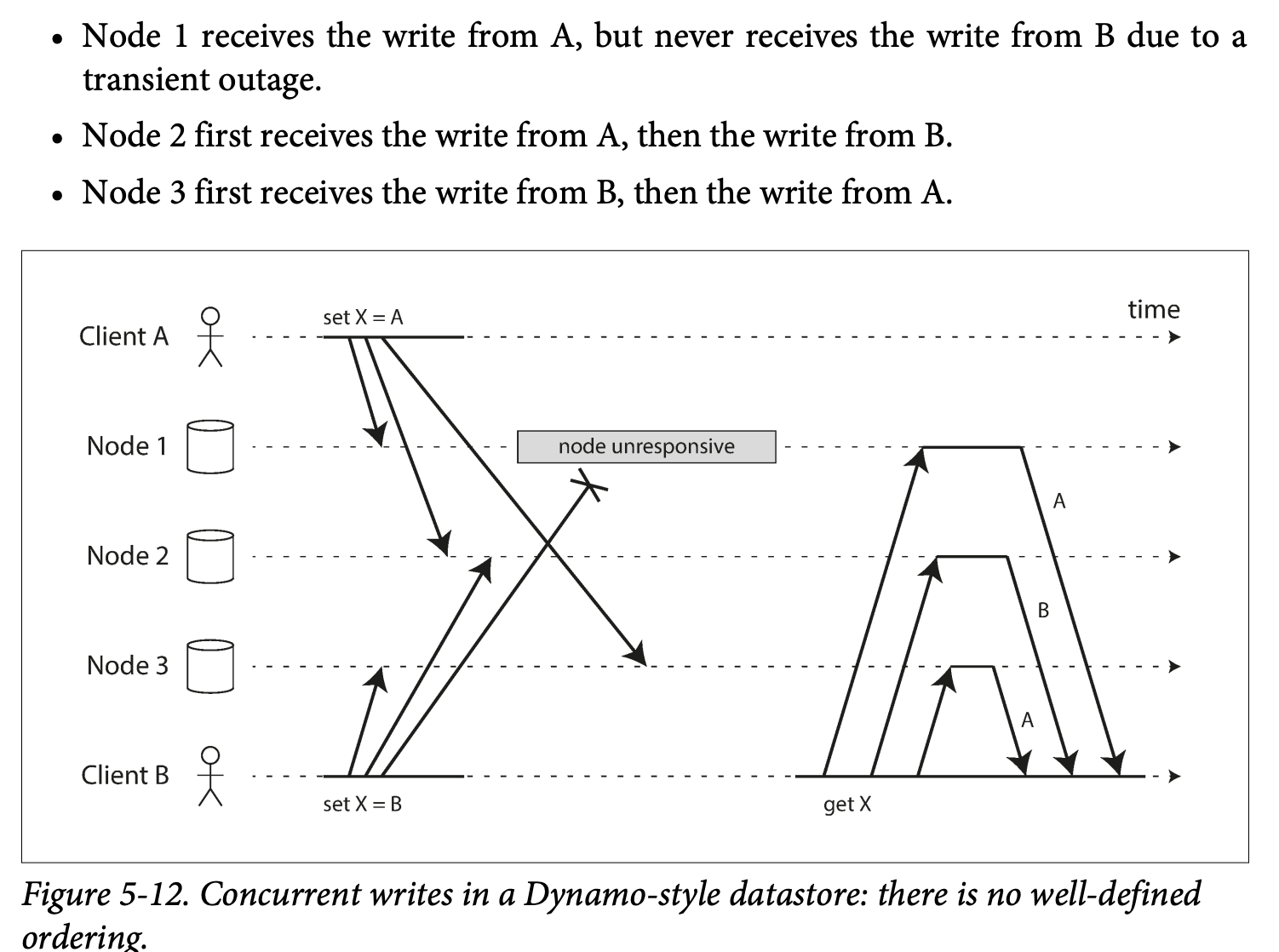
- In order to achieve eventual consistent, the nodes need to converge towards the same value.
Last Write winds (discarding concurrent writes)
- Allow the older value to be override , if the system cannot determine, the value will be copied to every replica, and all the replicas will eventually converge to he same value
- Actually there is no order -> they happened in concurrent
- We can force order : say we use timestamp -> LWW
- The cost is :only one write survive and others are dropped silently
- Safe way of using it is -> ensure that a key is only written once and thereafter treated as immutable , thus avoiding any concurrent updates to the same key. Cassandra gives every writes a UUID
The "happens-before" relationship and concurrency
- How do we decide whether two writes are concurrent?
- Two operations changing the same key -> concurrently (they don't know each other)
- If A is inserting a value and b is changing the value-> they must no be concurrent -> B causally depend on A(B changing a value that must insert by A first )
- Concurrent: They don't know each other but don't necessarily happened at the same time.
Capturing the happens before relationship
- An example that illustrating an algorithm capturing the happens before
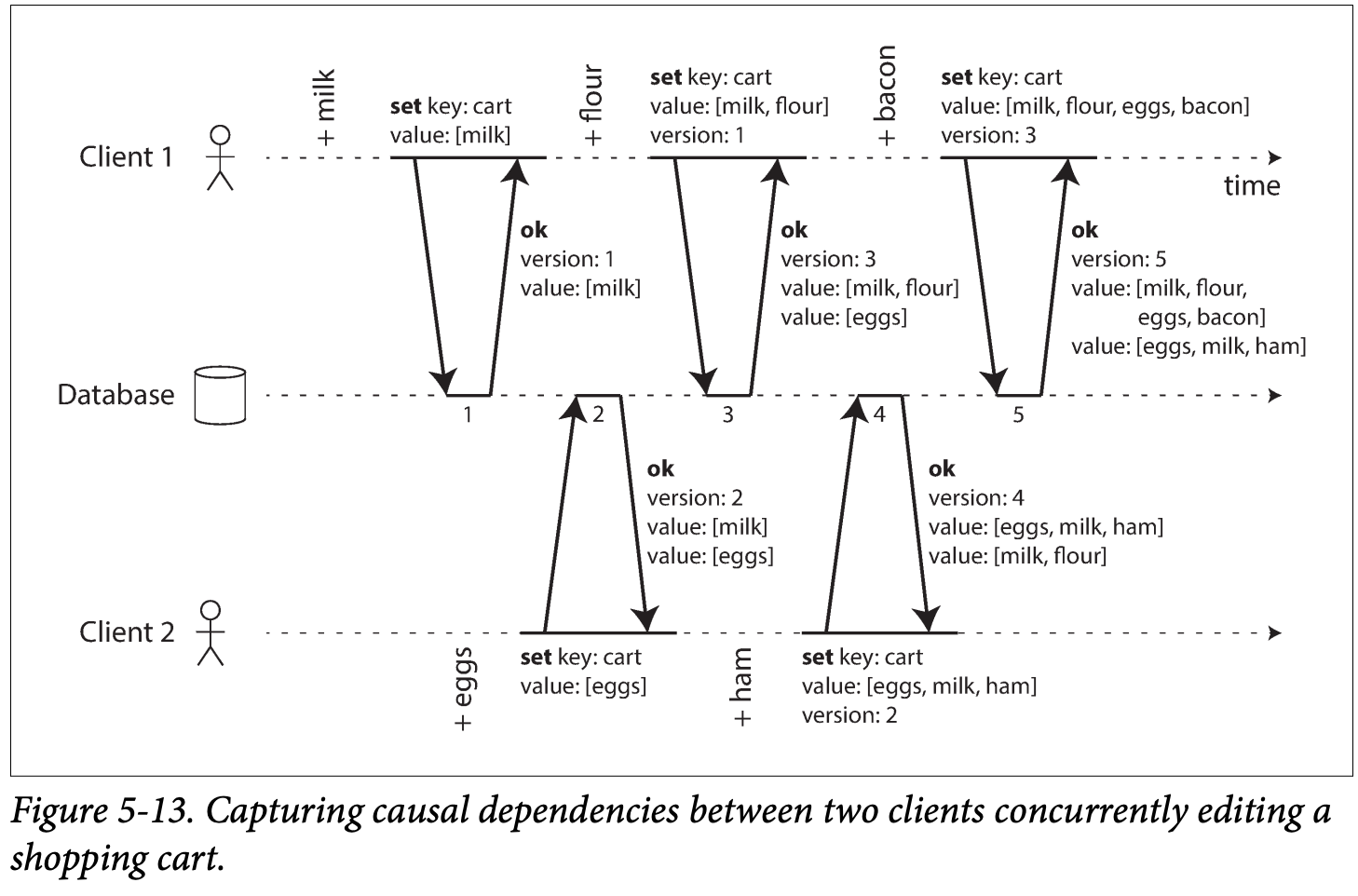
-
The arrows indicate the happened before :
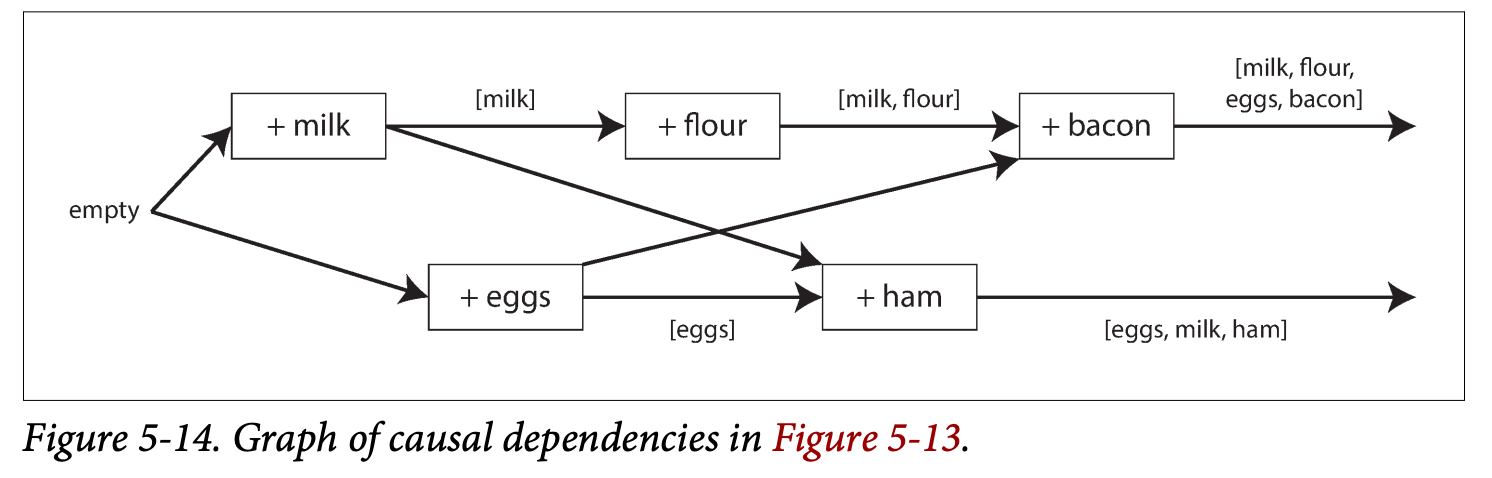
Keeps all the value that it cannot identify the causality, and let user to handle the conflict them selves.
Ensure no data is silently dropped , but requires client to do extra work -> clean up siblings
Merging concurrently Written values
- Pick on value based on version umber (may lost data) -> do some more intelligent work
- In the above case, take the union is good approach -> but cannot handle removing concurrently -> may leave a version number for the value deleted by some clients
Version vectors
- Each replica has version for each key -> collection of versions -> version vector