Chapter6 Partitioning
Scalability is the main reason for partitioning : different partitions can be places on different node in a shared-nothing cluster . Thus, large dataset can be distributed across many disks and the query load can be distributed across many processors.
This chapter will discuss ways of partitioning , and how the indexing interacting with data partitioning ; then talk about the rebalancing if you want to add or remove nodes in the cluster; finally we discuss how databased route requests to the right partitions and execute queries.
Partitioning and Replication
- Partition is usually combine with replication so that copies of each partition are stored on multiple nodes. -> partitions can be in multiple nodes for fault tolerance.
- A node may store more than one partition , in a leader based replication model the combination can look like: it's like the node is no longer the smallest unit of leader and slave, some partitions in a node might be the leader of otters while some partitions are followers of others.
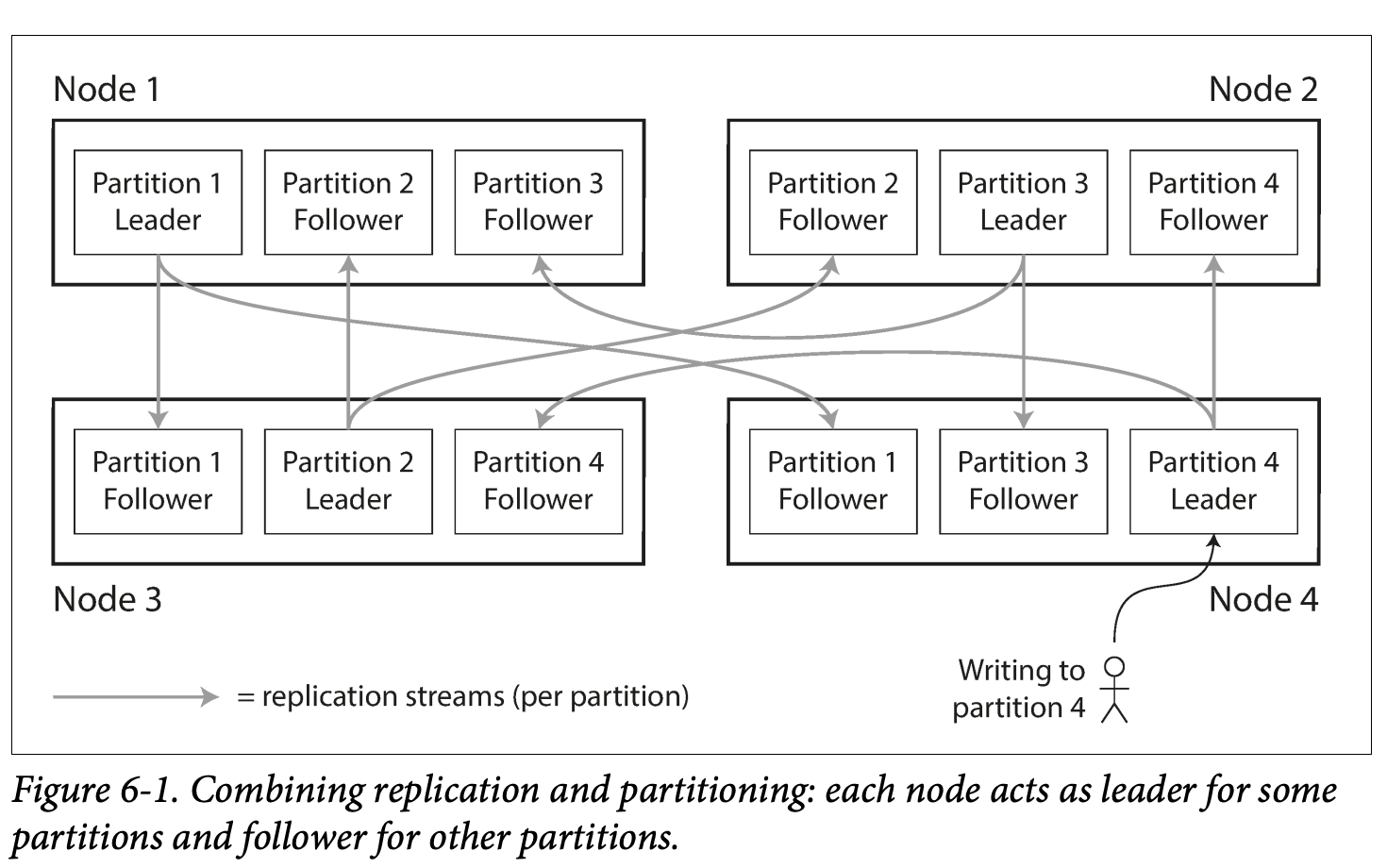
Partitioning of key-value data
- Goal of partitioning : spread the data and query load evenly across nodes.
- Skewed: some partitions have more dat or queries than others -> make partition less effective
- Hot spot: a node with disproportionately high load
- To avoid hot spot , the simplest way is to assign records randomly. -> disadvantage: your query becomes hard -> you need to query all the nodes in parallel to find the record
- A better way is : use a simple key - value model, in which you can always access data by its key
Partition by key range
-
One ways is to assign a continuous range of keys to each partition
-
If you know the boundaries between the ranges, you can easily determine which partition contains a given key .
-
If you also know which partition is assigned to which node , you can make your request directly to the appropriate node. -> node = bookshelf, book/volume = shard /partition, keys are partitioned alphabetically

-
The ranges of keys are not necessarily evenly spaced .-> TUVXYZ contains words equals A and B. -> rebalancing needed -> in HBase, BigTable, RethinkDB, and earlier version MongoDB
-
In each partition we can keep keys in sorted order : good for range query
-
Downside is that : certain access patterns can lead to hot spots. -> say we have a key of timestamp and partitioned by day, the write happens at the day we measure, so if we query today and the measurement happens, the write goes solely to the partition of today , bad
-
You may need something else as the key , say put the sensor name first and append the time -> then the write and read load from many sensors will spread across partitions more evenly
Partitioning by Hash of Key
- Many user hash function to avoid the risk of skew and hot spots
- You can assign each partition a range of hashes .
- Consistent hashing: a way of evenly distributed load across an interred-wide system of caches such as CDN.
- Cons: no efficient range query . In MongoDB, if you have enabled the hash-based sharing mode, any range query has to be sent to tall partitions and , Riak Couchbase and Voldemort don't support range queries on PK.
- Cassandra achieves a compromise : A table : compound primary key consists of several columns, one column is hashed to determine the partition and others are used as concatenated index for sorting the data in Cassandra's SSTables.
- Range queries can be efficient if first column is specified and scan other columns
- This enables elegant data model for one-to-many relationships: for example , in a social media site, one user may post many updates. If the Pk for the updates is chosen to be (user_id, update_timestamp), then you can efficiently retrieve all updates make by a particular user within some time interval , sorted by timestamp. (Different user may stored in different partitions)
Skewed workloads and relieving hot spots
- Hashing cannot mitigate the issue totally. In the extreme case, all the write and read to the same key, one partition can still be the hot spot -> a celebrity post to news cause storm.
- Now many database can not handle this kind of skews automatically so application engineers needs to take care of it. -> if one key is know to be hot, adding a random number to the keys and counting them to some other partitions.
- The bad of such way is you split the writes, you handle the reads with additional work , you have to read from those partitions and combine them.
Partitioning and Secondary Indexes
- A secondary index usually descent identify a record uniquely but rather is a way of searching for occurrence of a particular value : find all actions by user 123, find all articles containing the word "hogwash"...
- It added extra complexity, to be more specific in the partitioning, the y don't map neatly to partitions
- Two ways of partitioning with secondary index: document based and term based
Partitioning secondary indexes by Document
-
For example , you are operating a website selling used cars, each listing has a unique ID call it the document ID , and your partition the database the document ID
-
You want to let users search for cars allowing them to filter by color and by make, so you need a secondary index on color and make : whenever a red car is added to the database, the database partition automatically adds it to the list of document IDs for the index entry color:red
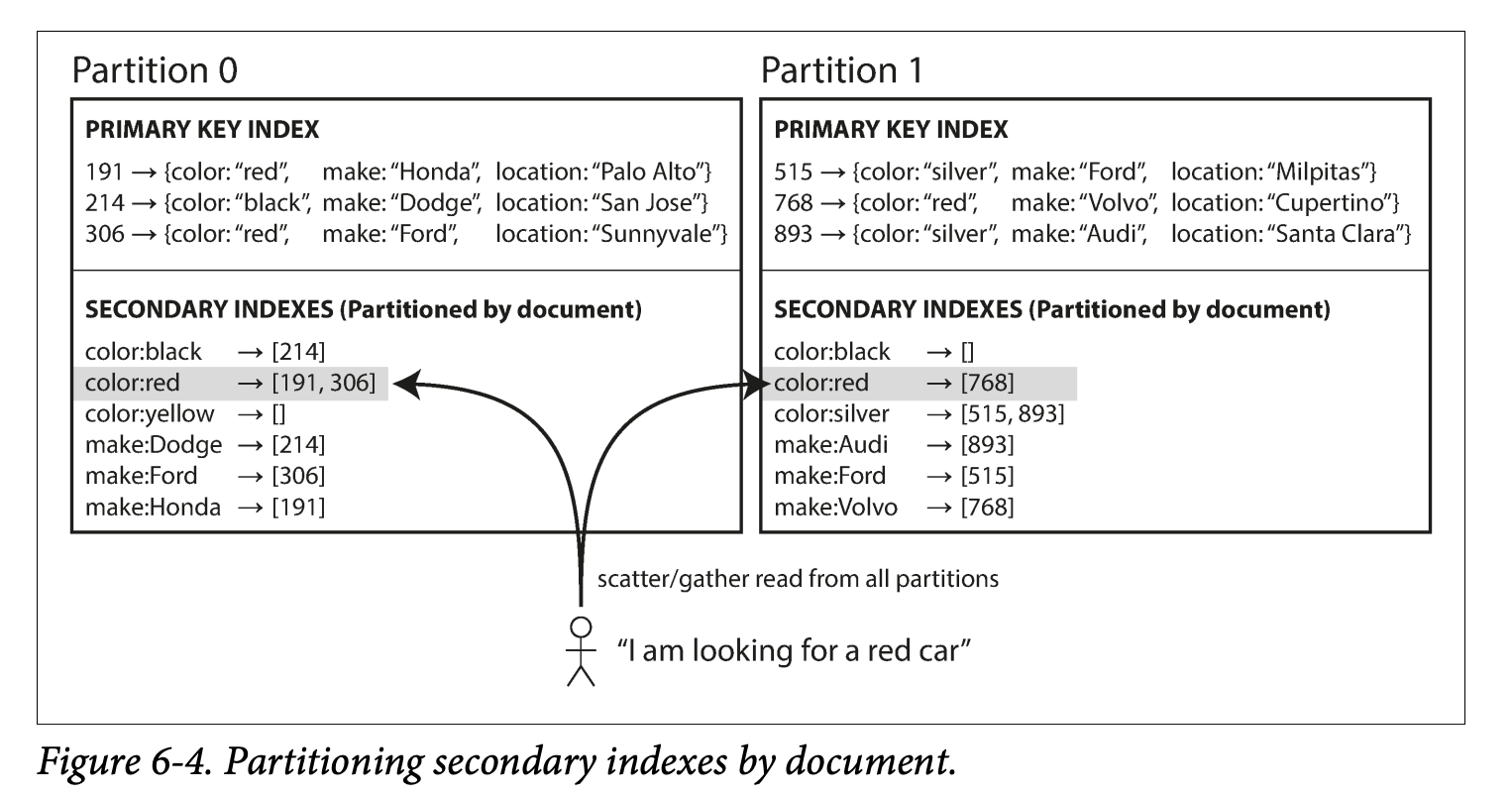
-
In this indexing approach , each partition is completely separate: each partition maintains its own secondary indexes , covering only the documents in that partition. -> it's own as local index since it only cares about the document in its partition
-
This approach to querying a partitioned database is sometimes known as scatter/gather -> different color and make are in many partitions
-
This approach is widely used
Partitioning secondary indexes by Term
-
Global index : covers all data in all partitions - > but we can't only store that index in one node. -> bottleneck
-
So the global index is also partitioned but with differently with the PK index.
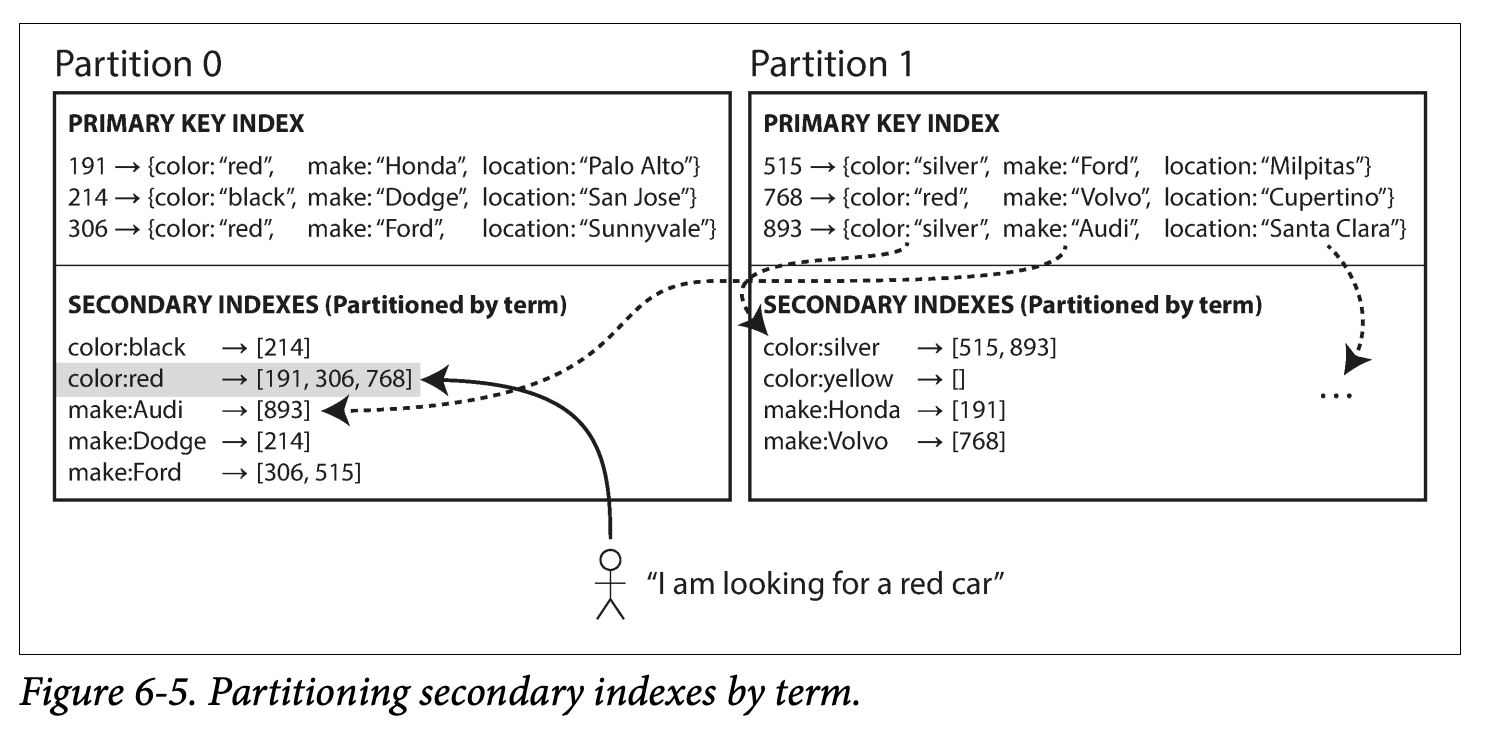
-
Term-partitioned : In this example, red cars from all partitions appear under color:red in the index, but the index is partition so that color starts from a-r are in partition0 and others s-z is in partition1;
-
We can partition the term by text /term itself which is good for range query, or can partition with hash, which is more even
-
Pros: Read is more efficient , it only needs to make a request to the partition containing the term that it wants
-
Cons: Writes are slower and more complicated , because a write to a single document may affect multiple partitions of the index
-
A distributed transaction across all partitions affected by a write is needed , which is not supported in all databases
-
In practice, this procedure is often async, (dynamoDB) -> may not be leveraged due to latency
Rebalancing Partitions
- The process of moving load from one node in the cluster to another is called rebalancing.
- Goals :
- The load should be shared fairly between the nodes in the cluster
- While rebalancing is happening, the database should continue accepting reads and writes
- Only necessary data should be moved between node to make balling fast and minis the network and disk I/O load
Strategies for Rebalancing
How no to do it: hash mod N
- The problem of mod (%) is that if the N is changed, most of the keys will need to be moved from one node to another -> such operation is expensive
- We need some approaches doesn't move non necessary data
Fixed number of partitions
-
Create many more partitions than there are nodes , and assign several partitions to each node . (Say 10 nodes with 1000 partitions ) -> if a node is added, this new node can steal a few from others until partitions are daily distributed once again(less impaction )(similar to removing a node )
-
Only partitions are moved between node. The total number of partitions does't change. The only changed is where the partition stays(the assignment) -> it's not immediately, it takes time to transfer a large amount of data over network - >so old assignment of partitions is used for reads and writes while the transfer is in progress .
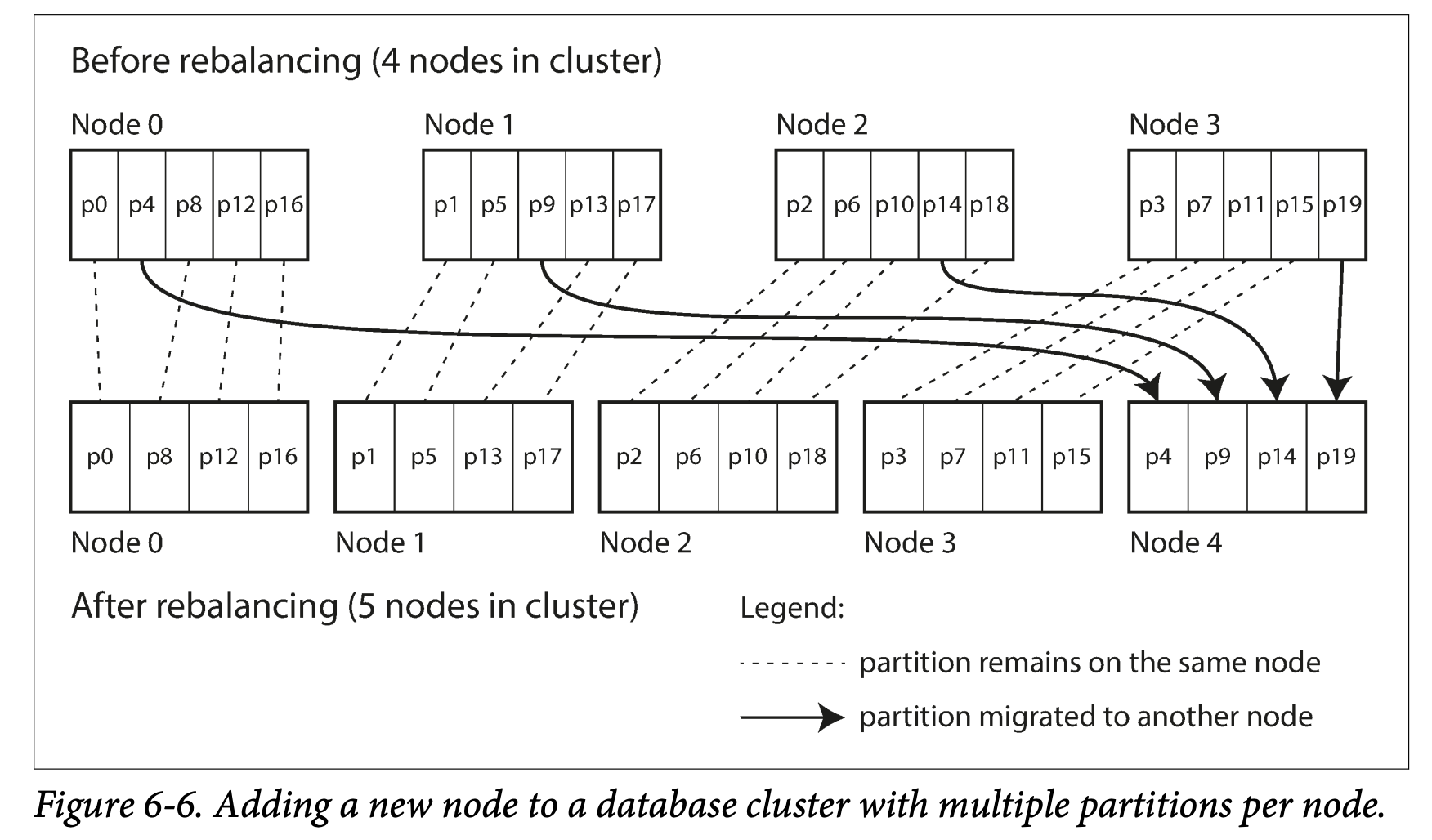
-
You can even account for mismatched hardware in the cluster: by assigning more partitions on more powerful machines .
-
This approach is used in Riak, Elasticsearch, CouchBase and Voldemort
-
The number of partitions is usually fixed -> so you might need a high number of partitions for future growth but with management overhead .
-
If the number is too big, rebalancing and recovery becomes expensive but if it's too small they incur too much overhead.
Dynamic partitioning
- If you use key range partitioning and the boundaries are wrong , you end up with all the data in one partition and you need to reconfigure boundaries manually which is boring
- Key range partitioned database such as HBase and RethinkDB create partitions dynamically. When a partition grows to exceeded to a configured size, it's split to two partitions, about half of the data end up on each side.
- If most data is deleted in a partition, it shrinks and merge with adjacent partition.
- Each partition is assigned to one node and each node can handle multiple partitions , after a large partition has been split one of its two valves can be transferred to another node to balance the load
- Pro: partition number adopt to the data volume
- Cons: an empty database starts with a single node, until it split, while others node are idle. -> HBase and MongoDB pre-split,
- Dynamic partitioning is suitable for hash partitions and key-range partitioning
Partitioning proportionally to node
- dynamic partitioning , the number of partitions is proportional t the size of dataset. -> the splitting and merge process keep the size of each partition between some fixed minimum and maximum
- Fixed number the size of each partition if proprotianonal to the size of the dataset
- Those two machines partition number has no relation with node number
- Cassandra and Ketama makes the number of partitions proportional to the node -> fixed number of partitions for each node
- Partition size grows with dataset's size , while node number keep the same
- When inscribing node number , partitions size shrink,
- Larger dataset needs more node , so this can keep the data size fairly stable
- When a new node added in the cluster, it picks random number partitions and split their half partition, leave half partition, -> may cause unfair split but with large amount of partitions , new node will get fair load.
Operations : Atomic or Manual Rebalancing
- Manual can somehow reduce the accident but need skills and carefulness
- While total automatic is careless but may be dangerous :
- If a node is down and response slow -> others thinks it's dead and do a rebalancing -> cause more pressure on others
Request Routing
-
Partitions are in many nodes, how does a client know which node to connect to when request ? -> rebalance -> assignment changes
-
Service discovery
-
Approaches :
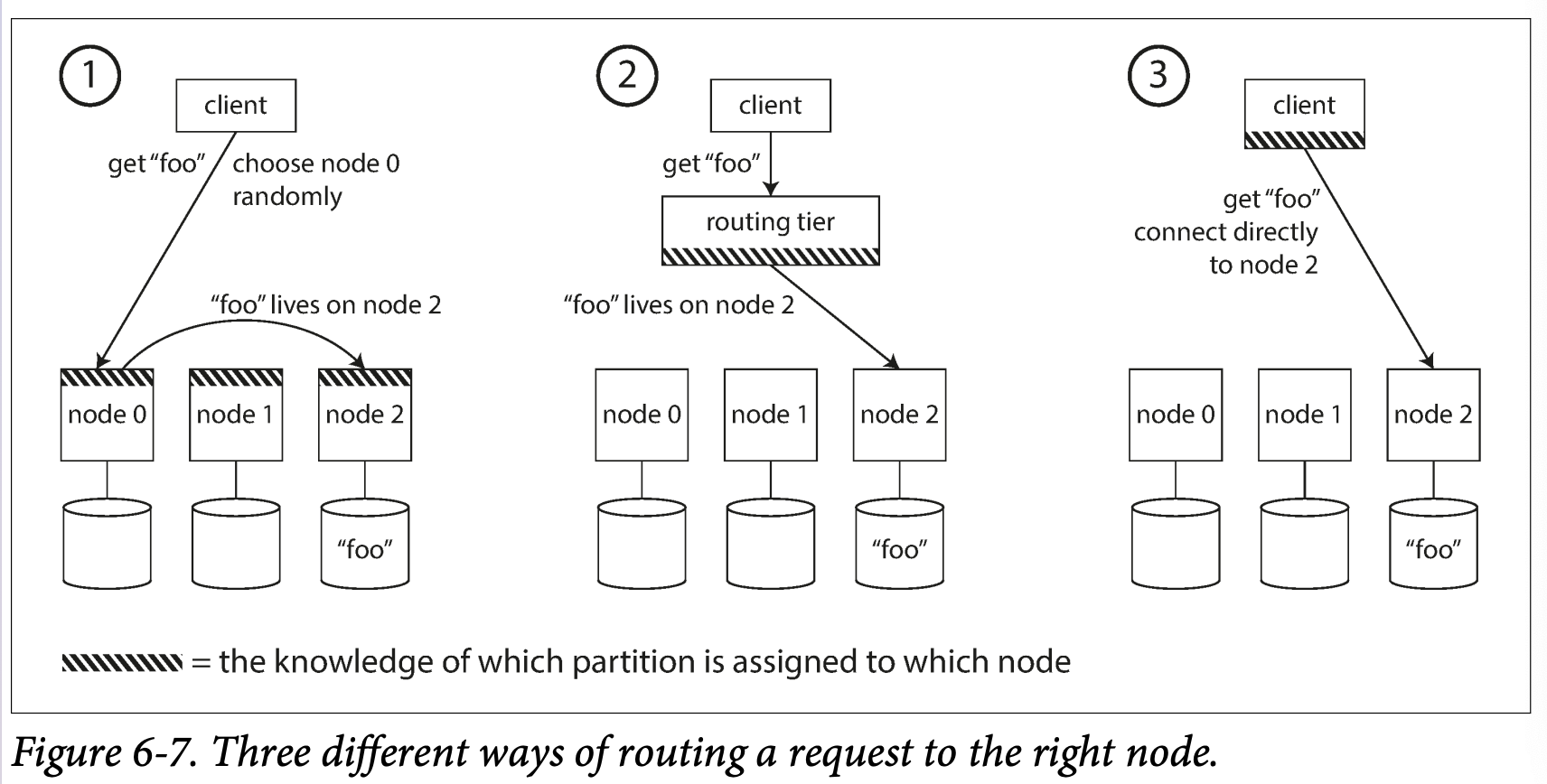
- Allow clients to contact any node . If the node owns the partition which the request applies , it can handle the request directly, otherwise, it pass to the appropriate node , receive the reply and passes the reply along to the client
- Send all request from clients to a routing tier first to determine the node that should handle each request and forwards them accordingly. -> requesting routing but also a partition-aware load balancer
- Require that clients know the partitioning and assignment of partitions to nodes.
-
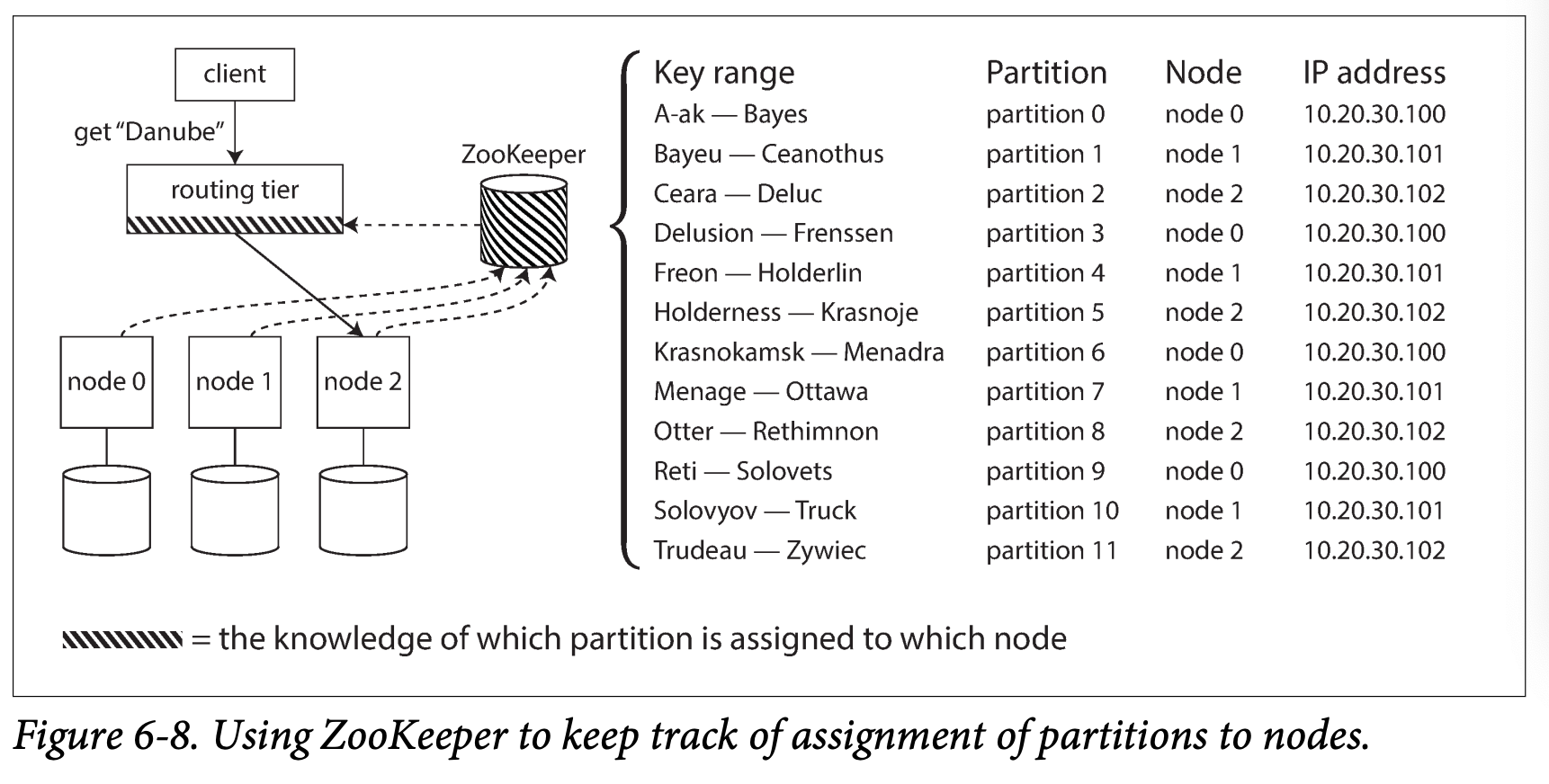
Many distributed data system rely on a separate coordination service such as ZooKeeper to keep trace of this cluster metadata .
-
LinkedIn's Espresso use Helix(in turn replies on Zookeeper) for cluster management ; HBase, SolrCloud and Kafka also user zookeeper to track partition management ; MongoDB has a similar architecture but it relies on its own config server implementation and mongos daemons as the routing tier
-
Cassandra and Riak take different approach : they use gossip protocol among nodes and disseminate any changes in cluster state.
- Request can be sent to any node and node can forward the request to appropriate node
- This mode can reduce complexity by avoid external coordination
-
Couchbase doesn't rebalance automatically.it configures a routing tier and Lears about routing changes from the cluster nodes.
-
DNS can be used for the routing tier to find the right IP to connect to.
Parallel Query Execution
- MPP: massively parallel processing relational database products , used for analytics .
- Special handling