Chapter7 Transaction
- A transaction is a way for an application to group several reads and writes together into a logical unit.
- Either the entire transaction succeed(commit); or it fails (abort, rollback)
The Slippery Concept of a Transaction
The meaning of ACID
- Atomicity, Consistency, isolation and durability
Atomicity
- Someting cannot be breakdown to smaller parts
- In ACID context , atomicity describe what happens is a client wants to make several writes but a fault occurs after some of the writes have been processed.
- Without it, some changes may take effect but we cannot know and when there is a retry, then some of the value will be changed twice .
- The ability to abort a transaction on error and have all write from that transaction discarded is the defining feature of ACID atomicity.
Consistency
- It's about your data that must always be true.
- AID are the properties of database while C is a property of application (database cannot guarantee consistency )
Isolation
-
It means concurrently executing transaction are isolated from each other.
-
Serializable isolation is rarely used since t carries a performance penalty.
Durability
- Durability promise that Ince a transaction has committed successfully and the data is has written will not be forgotten., even if there is a hardware fault or the database crashes .
- In a single node database, durability means the data has been written to nonvolatile storage such as hard drive or SSD, it usually involve a WAL or similar , which allows recovery.
- In a replicated database , durability means data has been successfully copies t some number of node, in order to provide a durability guarantee, a database must wait until these writes or replications are complete before reporting transaction successfully committed.
- Perfect durability doesn't exist.
Single-object and multiple-object Operations
-
Muti-object transactions : you want modify several objects at once ->when several pieces of data need to kept in sync
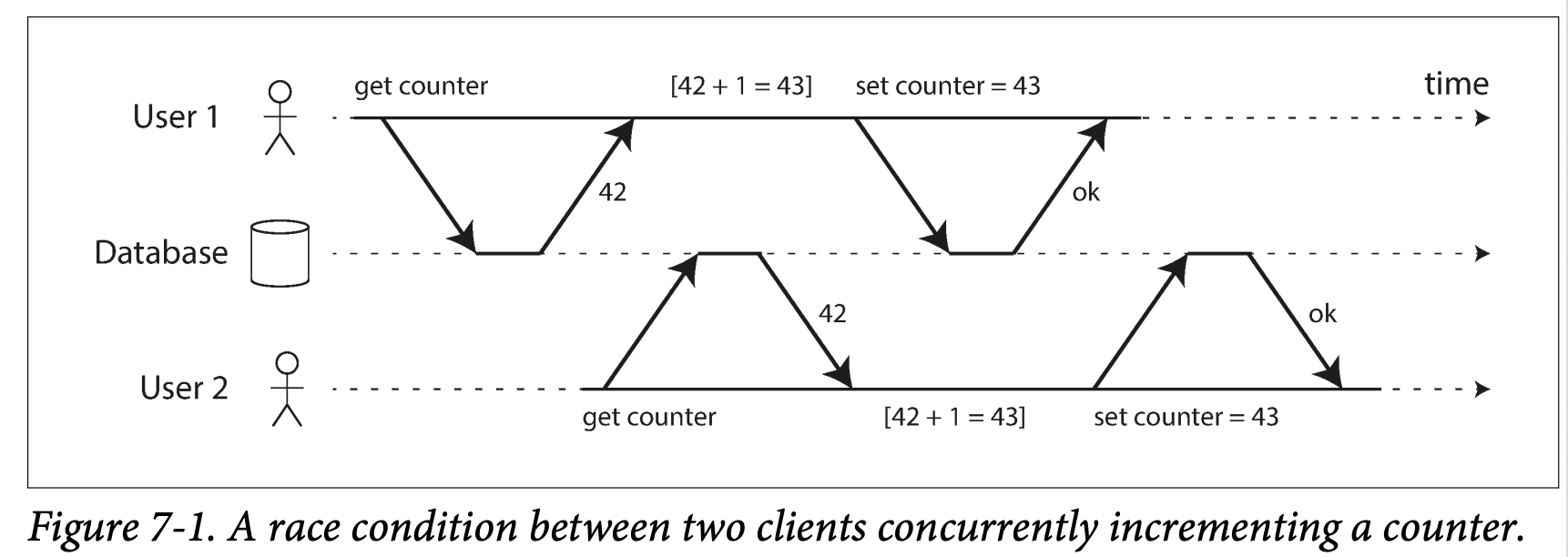
- say you want to query unread email count for a user:
SELCT COUNT(*) FROM emails WHERE recepent_id = 2 AND unread_flag = true;; - Now you find it;s slow when the count is large so you store the info in a separate table (-> a kind of denormalization)
- Now whenever a new message comes in you have to increment the unread counter as well , when it's marked read, you decrement the unread counter
- say you want to query unread email count for a user:
-
In one condition, User 2 experience the mailbox shows an unread message but the counter shows zero unread message because the counter increment has not yet happened -> isolation would have prevent this by ensuing that user 2 see either both the inserted email and updated counter , or neither, but not inconsistent halfway point.
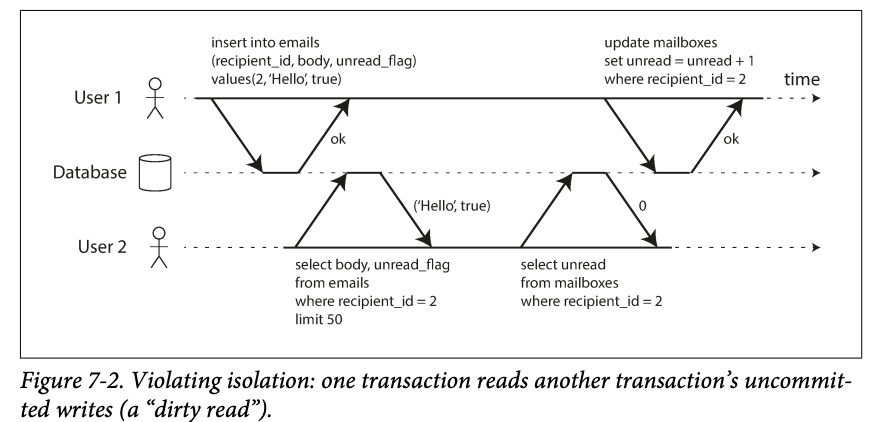
-
Atomicity: if an error occurs somewhere over the course of transaction, the contents of the mailbox and the unread counter might become out of sync.
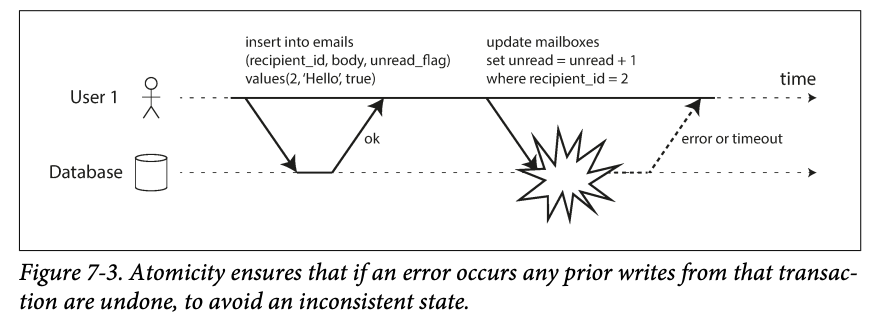
In an atomic transaction, if the update to the counter failed, the transaction is aborted and the inserted emails is rolled back.
-
Multiobject transactions require some way of deterring which read and write operations belong to the same transaction . -> in relational database , this is typically done based on the clients TCP connection to the database server , everything between BEGIN TRANSACTION and a COMMIT statement is considered to be part of the transaction.
-
Many non-relational database don't have such way pf grouping operations.
Single-object Writes
- Atomicity and isolation also apply when a single object is being changed : for example, imagine you are writing a 20KB JSON document to db: what if
- Network connection is corrupted after the first 10KB have been sent, does the db store the unparseable 10KB fragment of JSON?
- If the power done while the db is in the middle of overwriting the previous value, do you end up with the old and new value together?
- If another client reads document while the write is in progress , will it see the partially updated value ?
- Atomicity can be implemented using a log for crash recovery and isolation can be implemented using a lock on each obj
- The operations provided in write single object concurrently is not real transactions ;
- Transmutation is understood as a mechanism for grouping multiple operations on multiple objects into one into of execution
The need for multi-object transactions
- Scenarios that needs several objects to be coordinated :
- In a relational db, one row in table has a foreign key to a row in another table. -> multi-object transaction allow you ensure there reference remain valid.
- In a document data model, there is no join so when denormalization information needs ti e updated , like the previous email example, you need to update several documents in one go.
- Secondary indexes, you need to update them every time you change a value. There indexes are different database objects from a transaction point of view.
Handling errors and aborts
- Aborting enable safe retries
- But it't not perfect:
- The trancation is successful but network failed to return the ack, the retry will cause it be performed twice -> unless you have app layer deduplication mechanism
- If the error is due to overload, retry will make things worse.
- It;s only Wirth retrying after transient error (deadlock, isolation violation, temporary network issue and failover ), but not permanent issue (Constraint violation )
- If the transaction has side effects outside the database, those side effects may happened even if the transaction is aborted
- If the client process fails while retrying, any data it was trying to write to the database is lost
Weak Isolation levels
Serialization has performance cost so many database provide users with weak isolation which protect some transaction issue but not all .
Read Commit
- The most basic transaction isolation is read committed, with two guarantees :
- When reading from database , you will only see data that has been committed(no dirty reads)
- When writing to the database, you will only overwrite data that has been committed(no dirty writes)
No dirty reads
-
Dirty data: the data that hasn't been committed by a transaction, but seen by another transaction
-
Transaction running on the read commit isolation level must prevent dirty reads.
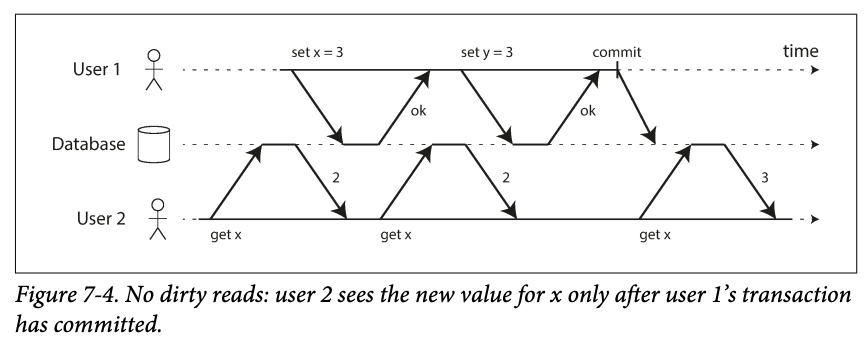
-
The reason for preventing dirty reads :
- Partial updates(some update but some aren't) in a transaction may be confusing : e.g. you have a new unread email, but the counter isn't updated.
- Writes needs to be rolled back should not be visible. -> if a transition aborted and some writes are going to be rollback.
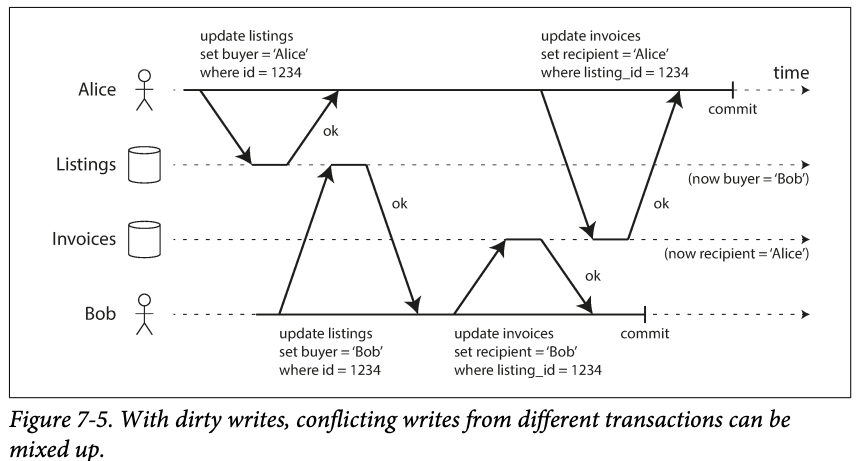
No dirty writes
-
Transactions running at the read committed isolation level must prevent dirty write by delaying the second write until the first write's transaction has commited or aborted.
-
The concurrency issue avoided:
-
Dirty read can lead to a bad outcome :
-
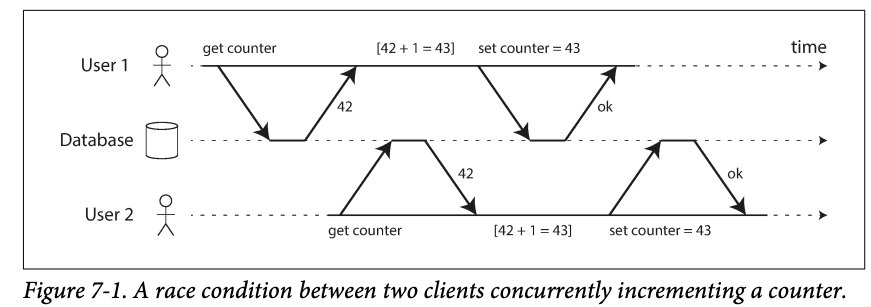
However, read committed doesn't prevent the race condition between two counter increments. The second write happens at the first write committed which is not a dirty write but this stills a problem.
-
Implementing read committed
- Most commonly database prevent dirty writes by using row-level locks:
- when a truncation wants to modify a particular object (row or document), it must first acquire a lock on that object.
- It must then hold the lock until the transaction us committed or aborted;
- Only one truncation can hod the lock for a given object.
- This is done by database in read committed mode (or stringer isolation levels)
- For dirty read:
- We could also give the object a lock when reading it; however;
- This doesn't work well in practice because a long -running write transaction can force many read-only transactions to wait until the long-running truncation has completed. -> harm performance
- So many databases : for every write , the database remember the old and new value, give the old value before the transaction committed and give the new value once the transaction committed.
Snapshot Isolation and Repeatable Read
-
e.g.
-
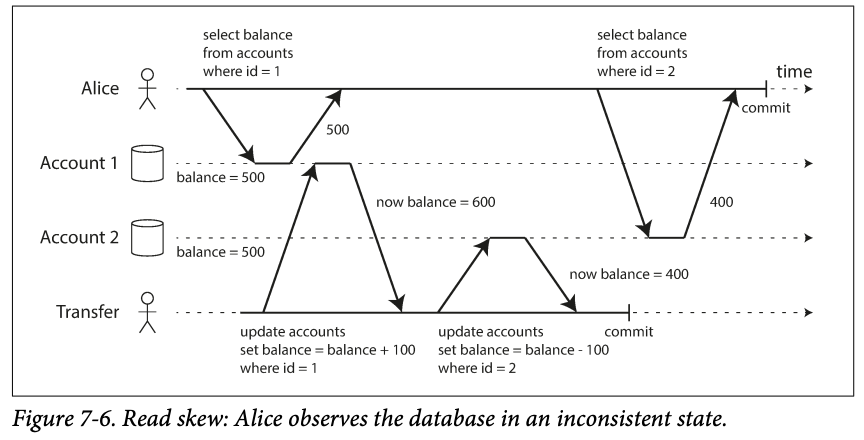
Alice has two bank account and each has \$500, she transferred 100\$ from account one to the other account two;
-
at same time, if she queries from the account1, she get the \$400, she queries account2, she get 500$ here(before the incoming payment has arrived).-> \$900 in total.
-
If she queries again, she get \$600 and now it's good.
-
-
This is called non repeatable read or read skew : she saw different queries result for the same query. (This is acceptable under read committed , the balance she saw(\$400) is indeed committed) -> it's not a lasting issue .
- There are some scenarios that read committed cannot handle
- Backup: the backup happens while the database is still receiving writes. You end up with some parts has new data while some has old data(in this case \$500)
- Analytic queries and periodical integrity checks : these queries checks the data at different time point -> which is non sense in such read skew
- Snapshot Isolation is the most common solution to the problem.
- Each transaction reads fro ma consistent snapshot of the database (the transactions sees the data that is committed in the database at the start of the transaction) -> will not affected by other transactions since it's reading a snapshot.
- It's helpful for long-running ,read only queries such as backups and analytics .(it's hard to understand when the data changes when querying) , consistent data would be easier to understand.
Implementing snapshot isolation
-
Write locks to prevent dirty reads , but no locks on reads -> performance -> reader never blocks writer and writer never blocks readers
-
The database must potentially keep several different committed versions of an object, because valorous in progress transactions may need to see the state of the database at different points of time. -> it maintains several version of an object side by side -> MVCC, multi-version concurrency control
-
In read committed isolation, the database only keeps two version : the uncommitted version and the committed version. -> MVCC is used here , two snapshots were used. While in the snapshot isolation, one snapshot is used for an entire transaction.
-
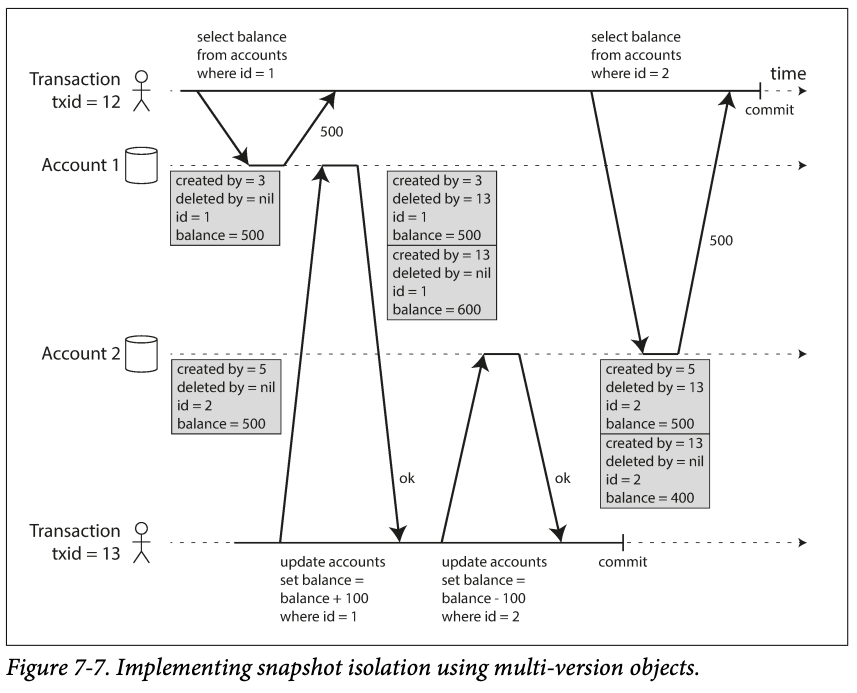
The implement in PostgreSQL: when a transaction is started, it is given a unique, always increasing transaction ID. Whenever a transaction writes anything to the database, the data it writes is tagger with the translation ID of the writer.
Visibility rules for observing a consistent snapshot
- When a transaction reads from a database, transaction IDs are used to decide which objects it can see and which are invisible.
- Defining visibility rules :
- At the start of the transaction, all the database makes a list of all the other transaction that are in progress path that time. Any write those transactions make are ignored ;
- Any write made by aborted transaction are ignored.
- Any writes made by transactions with a later transaction ID are ignored .
- All other writes are visible to the application 's queries.
- In the above example, when transaction 12 query account2, the balance 500 is returned, while the delete balance 500 is invisible since it's from transaction13.
- An object is visible if :
- At the time when readers's transaction stared, the transaction that created the object had already committed
- The object is not marked for deletion or if it is, the transaction request deletion is not committed at the reader transaction started
- Updating is internally becomes deleted and create.
Indexes and snapshot isolation
- How does index works in MVCC?
- Index pointe to all version and request index query to filter out invisible objects to the current transaction
- When GC deleted invisible old object, the index will also be deleted
- In practice many implementation details determine the performance of MVCC.
- PostgreSQL has optimization for avoiding index updates if different version of the same object can fit on the same page.
- CouchDB user B-tree, so the use an append-only /copy-on-write , which doesn't overwrite pages of the tree when they are updated , but instead creates new copy of each modified page. (From root) , non changed node will be immutable.
- Append-only B-tree , every write transaction create a new B-tree root, (which is a consistent snapshot of the database at some point of time when it's created) -> no need to filter out objects based on transaction IDs because writes cannot change current B tree. They can only create new roots. -> needs a background GC and compress
Repeatable read and naming confusion
- Different implementation has different names due to SQL standard doesn't have snapshot isolation concept
- Some databases only implement them to show market thought they are not real.
Preventing Lost Updates
- The lost updated problem can occur if an application reads some value from the database, modifies it and write back the modified value (a read-modify-write cycle). -> if two transactions do this concurrently, one of the modification can be lost, because the second write does not include the first modification. -> this happens when
- Incrementing a counter or updating an account balance (requires reading the current value, calculating the new value and writing back the updated value)
- Making al locals change to a complex value. e.g. adding an element to al list within a JSON document(requires parsing the condiment, making the change, an dwarfing back the modified document)
- Two users editing a wiki page at the same time, where each user saves their changes by sending the entire page to the server, overwriting whatever is currently in the database
Atomic Wirte operations
- Many database provide atomic update operations, which remove the need ti implement read-modify-write cycles in application code -> the best choice if supported
- Implemented by taking an exclusive lock the object when it's read so that no other transaction can read it until the update has been applied. -> called cursor stability
- Unfortunately, ORM frameworks make it easy to accidentally write code that performs unsafe r-m-w cycles instead of using atomic operations provided by the database. -> potential bug here if you don't know what you are doing
Explicit locking
-
If database doesn't provide atomic update operation, application can explicitly lock object being updated.
-
e.g. in a multiplayer games, several players can move the same figure concurrently. An atomic operation may not be sufficient, because the application also needs to ensure that a player's move abides by the rules of the game, which involves some logic that you cannot sensibly implement as a database query. -> a query isn't enough even the database provide atomic operation. So need a bigger lock
sql BEGIN TRANSACTION; SELECT * FROM figures WHERE name = 'robot' AND game_id = 222 FOR UPDATE; -- Check whether move is valid, then update the position -- of the piece that was returned by the previous SELECT. UPDATE figures SET position = 'c4' WHERE id = 1234; COMMIT;The
FOR UPDATEindicate that database should lock all the rows returned for updating -
You need to always be carefully when using locks to prevent race condition.
Automatically detecting lost updates
- Atomic operations and locks are ways by forcing the operations sequentially ; another way is to allow them update in parallel but detect the lost update, and then about the transaction and force it to retry its r-m-w cycle.
- Pros: database can perform the detection efficiently in conjunction with snapshot isolation. -> remove the dependency of application code handling or atomic database operation
Compare-and-set
-
In database that don't have transactions, there is an atomic compare and set operation.
-
Allow an update to happen only if the value has not changed since you last read it.
-
For example, to prevent two users concurrency update the same wiki page, you might try this:
sql -- This may or may not be safe, depending on the database implementation UPDATE wiki_pages SET content = 'new content' WHERE id = 1234 AND content = 'old content';If the content has changed and no longer matches old content, this update will have no effect. So you need to check the if the update take effect and rely if necessary
-
However, if the database where clause is reading an old snapshot, then the where could be true.
Conflict resolution and replication
- Things become complicated when considering data replication : data are replicated to many nodes and data can be modified concurrently on different nodes, - >additional steps needed to be taken to prevent lost updates
- Locks and compare and set assume there is one copy of write data while leaderless and multi-leader replication, data can be written in many node concurrently and replicate async.
- Instead, we replicate and merge those nodes in application code
- Atomic operations can work well in replicated context. Especially when the operations that orders don't matters(apply in different order can get the same result).
- Last written wins , which is the default in many databases , will cause update lost.
Write Skew and Phantoms
-
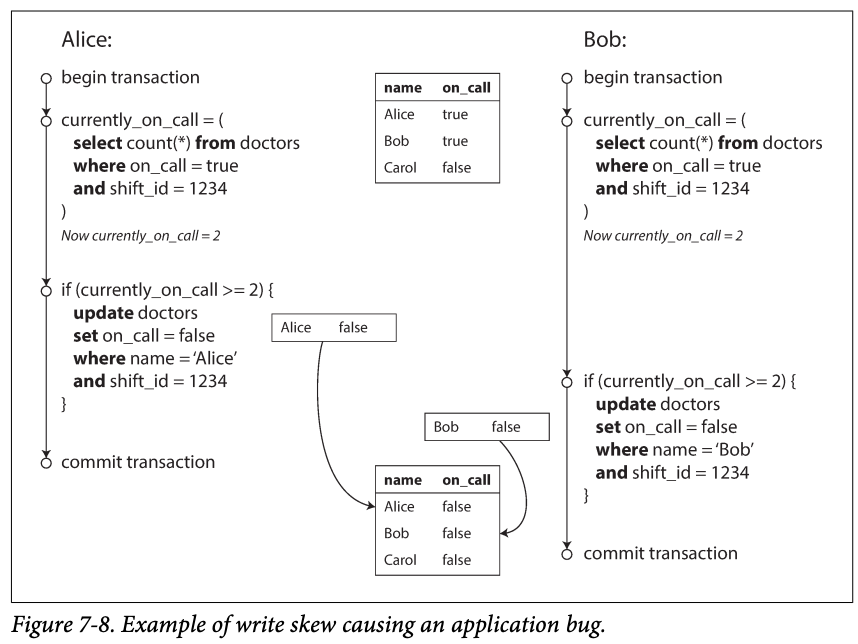
Consider an example first : a on call shift system for the hospital; there may be several doctors at a time on call but at least one should be oncall. Doctor can give up their shifts if there are others on calling in that shift.
-
Alice and bob both not feeling well and want to cancel the shift.
-
In each transaction, the application first check that two or more doctors are currently on call if yes, assume it's safe for one doctor to go off call since database is using snapshot isolation, both checks returns 2. So both transactions returns success and proceed to the next stage. -> no one is on calling
Characterizing write skew
-
Write skew: it's not dirty write nor a lost update since two transactions are updating two different objects.
-
If the two transactions had run one after another, the second doctor would have been prevented from going off call.
-
It can be regarded as a generalization of the lost update problem. : write skew can occur if two transactions read the same objects and then update some of those objects . In the special case here different transactions update the same object you get a dirty write or lost update
-
With write skew , out ways of prevent lost update may not help:
-
Atomic single - object operation don't help since multiple objects are involved
-
Automatic detection os lost update in some database implementation of snapshot isolation doesn't help-> it requires true serialization isolation
-
You can rely on configuring constrains in some database if supported. Such as uniqueness, foreign key ... triggers.. .
-
If you cannot use serializable isolation level, the second best option is to explicitly lock the rows that the transactions depends on.
sql BEGIN TRANSACTION; SELECT * FROM doctors WHERE on_call = true AND shift_id = 1234 FOR UPDATE; UPDATE doctors SET on_call = false WHERE name = 'Alice' AND shift_id = 1234; COMMIT;
-
More example of write skew
Meeting room booking system double booking
BEGIN TRANSACTION; -- Check for any existing bookings that overlap with the period of noon-1pm SELECT COUNT(*) FROM bookings WHERE room_id = 123 AND end_time > '2015-01-01 12:00' AND start_time < '2015-01-01 13:00'; -- If the previous query returned zero: INSERT INTO bookings (room_id, start_time, end_time, user_id) VALUES (123, '2015-01-01 12:00', '2015-01-01 13:00', 666); COMMIT;
Snapshot isolation doesn't prevent another user from concurrently inserting a conflicting meeting -> you need serialization isolation
Multiplayer game
Lock doesn't prevent two players moving figures to the same position. -> Constrain needed
Claiming a username
Unique constrain need
Preventing double-spending
Two spending item inserted concurrently -> user spend more than they have
Phantoms causing write skew
-
The pattern of the examples:
-
A select query checks whether same requirement is satisfied by searching for rows that match soem condition.
-
Depending on the result of the first query, the application code decides how to continue
-
If the application decide to go ahead, it makes a write to the database and commit the transaction.
The effect of this write changes the precondition of the decide of step 2.
-
-
In the doctor on call shift, the row being modified in step 3 was one of the rows returned in step 1 , so we could make the transaction safe and void write skew by rocking the rows in step1 (
SELECT FOR UPDATE); others examples are little different, they check the absence of some rows for matching come condition, and the write adds a row matching the same condition. SoSELECT FOR UPDATEnot working here since no rows returned in the step1 -
Phantom: The write of a transaction changes the result of a search query in another transaction. Snapshot isolation avoids phantom in readonly queries. But not in read write cases.
Materializing conflict
- If there is no object where we can attach the locks, we can artificially introduce a lock object into the database .
- In the meeting room example, you could imagine create a table, each row is a room with its available time(the combination of the room and time slot)
- Transaction can add lock on the particular combination of the table above
- This approach is called materializing conflicts , because it takes a phantom and turns it into a lock conflict on a concrete set of rows that exist in the database. -> hard and error prone, and ugly because application needs to handle the concurrence control -> serialization is prefer if possible
Serialization
- Strongest level of isolation
- It guaranteed even transactions executed in parallel, the result is like they are in serial -> thus transactions behave correctly.-> database prevents all race conditions
Actual serial Execution
In order to make the most of the single thread, transitions need to be structured differently from traditional form.
Encapsulating transactions in stored procedures
-
If a database transaction needs to wait for input from a user, the database needs to support huge number of concurrent transaction, most of them idle.
-
So most OLTP databases keep the transaction short by avoiding interactively waiting for a suer within a transaction.
- A transaction is committed with in the same HTTP request.
-
No human, but the transactions have continue to be executed in an interactive client/server style, one statement a time.
- An application makes a query, reads the result, perhaps makes other query denoting on the result of the first query. ... the queries and results are sent back and firth between the application code, -> times are spent on the network communication
- If you allow single transaction, the perfroamce would be bad.
- So in this kind of databases, it';s necessary to process multiple transactions
-
System with single thread serial transition processing don't allow multi-statement translations -> the application must submit the entire transaction code to the database a head of time -> stored procedure
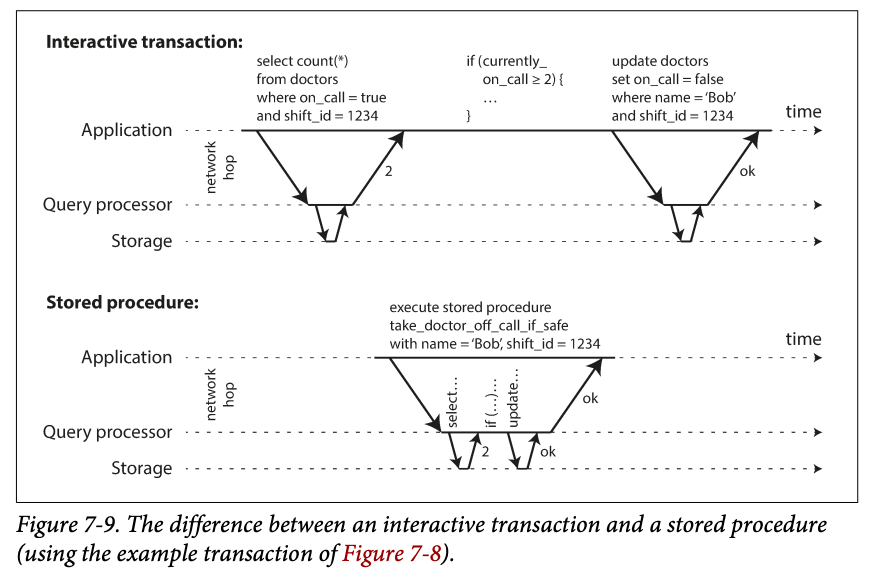
Pros and Cons of stored procedures
- Cons:
- Each database vendor has their own languages for stored procedure so no general purpose programing languages libraries
- Code in the database is hard to manage : debug, monitor, test ...
- Database is more performance sensitive : bad stored procedure cause more several problems.
- Pros:
- Modern implementations of stored procedures start use existing general perpose programming languages
- All in memory, performance is good.
Partitioning
- Single thread can be a bottleneck for the write heavy application
- In multi core machine, partition data so that each transaction only read and write single partition -> increase throughput
- For transaction need to access multiple partitions, the database must coordinate the transactions across all the partitions that it touches. -> lock needed for serialization
- Multiple partition has overheads so they are slow than single partition
- Whether can be single partition depends on the structure of data, if k-v data, it's easy, but with multiple secondary indexes, it's like to require partition coordination.
Summary of serial execution
- Serialization with certain constraints :
- Transactions needs to be small and fast
- Use case limits to : active dataset can fit in memory
- Write thought put must be low to be handle in single CPU or transactions needed to be partitioned without coordination
- Cross partition transactions are possible but there is a hard limit for the can used
Two-Phase Locking(2PL)
- Several transactions are allowed to concurrently read the same object as long as nobody is writing to it. But as long as anyone want's to write :
- If truncations A has read an objet and B wants to write, B must waits until A is commits or abort, in case of B is changing the object behind A
- If A has written an object and B wants to read that obj, B must wait until A commits or aborts before it can continue.
- 2PL not only block other writers but also readers. Compared with snapshot isolation who: read never blocks writes and write never blocks read.
Implementation of 2PL
- The blocking of readers and writers is implemented by having a lock on each object in the database. -> the lock can be shared or exclusive mode.
- If a transaction wants to read an object, it must first acquire the lock shared mode.
- Several transactions are allowed to hold the lock in shared mode simultaneously but if another transaction has an exclusive lock on the object, these transactions must wait.
- If a transaction wants to write an object, it must first acquire the lock exclusive mode.
- No other transactions are allowed to hold the lock at the same time (both mode)
- If a transaction first reads and then writes, it may upgrade its shared lock to an exclusive lock.
- This works the same as getting a exclusive lock directly
- After a transaction has acquired the lock, it must continue hold the lock until commit or abort.
- Two phrase : acquire and release lock
- If a transaction wants to read an object, it must first acquire the lock shared mode.
- Deadlock : two transactions are waiting for each other to release their locks.
- Database has process to detect and kill one
- Killed one needs to be retried by application
Performance of 2PL
- Bad performance: not only due to lock acquiring but the reduced concurrency.
- Database running 2PL has unstable latency -> one transaction need to wait for the other, and the one running has non predictable commit time(by human).
- Waste of effort: transactions killed due to deadlock will retry
Predicate locks
-
Locks on all objects that match some search condition
-
sql SELECT * FROM bookings WHERE room_id = 123 AND end_time > '2018-01-01 12:00' AND start_time < '2018-01-01 13:00';- If A transaction wants to read objects matching some condition, like in that SELECT query , it must acquire are shared-mode predicate lock on the conditions of the query. If another B has an exclusive lock on any object matching those conditions, A must wait until B reales its lock before it's allowed to make its query.
- If A wants to insert, update or delete any obj, it must first check whether the old or the new value matches any existing predicate lock. -> if there is a lock holding by B, then A must wait until B has committed or aborted before it can continue
-
The key idea is the predicate locks apply even the object don't exist in the database, but which might be added in the future(phantom)
Index-range locks
- If there are locks by active transactions, checking for matching locks becomes time consuming
- For this reason, many database implementing 2PL actually implement index-range locking
- Simplify the predicate locks by greater its mating set. -> this is safe , original range are included
- Index range locks are not precise as the predicate locks but they have better performance.
- But if there is no suitable index where a range lock can be attached, the database can fall back to a shared lock on the entire table -> safe but bad
Serializable Snapshot Isolation(SSI)
Pessimistic vs optimistic concurrency control
- Pessimistic concurrency control : assume things can be wrong, 2PL is pessimistic concurrency control , so better to stop and wait
- Optimistic concurrency control : transactions continue if something potentially dangerous happens, hoping everything will turn out right. -> check when transactions want to commit, allow those who executed serializably .
- Pros and cons
- Cons: performance is bad when many transaction access the same object and there might be many transactions to abort. -> make the performance at its max throughput worse
- Pros: if there is enough space and contention between transactions is not that high, it tends to perform better.
- Serialization snapshot isolation : in top of snapshot isolation, SSI adds an algorithm for detection serialization conflict among writes and determining which transactions to abort
Decisions based on an outdated premise
- Decision are based on an outdated premise(fact are true at the beginning)
- Database needs to detect situations of outdated premise. Apporaches :
- Detecting read of stale MVCC
- Detection write affect prior reads
Detecting stale MVCC reads
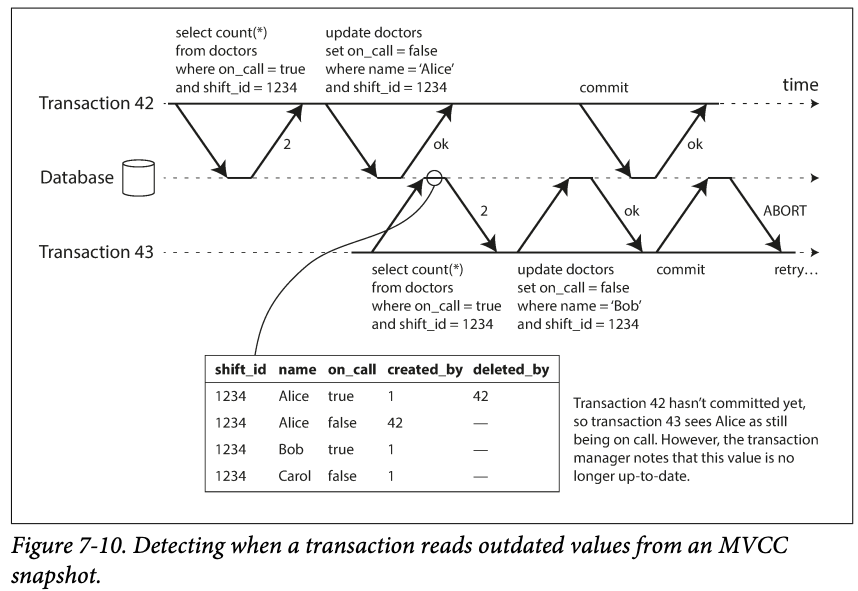
- When transaction43 wants to commit, it ignore the commit of transaction42, which is means translation 43 is based on an outdated premise.
- So when we want to commit a transaction, we detect if there is any ignored write have been committed.
- Why wait until commit instead of immediately detection of there is a uncommitted wire ->
- This write might be aborted
- The transaction might be a read
- So SSI prevents long running reads from unnecessary aborts
- Why wait until commit instead of immediately detection of there is a uncommitted wire ->
Detecting writes that affect prior reads
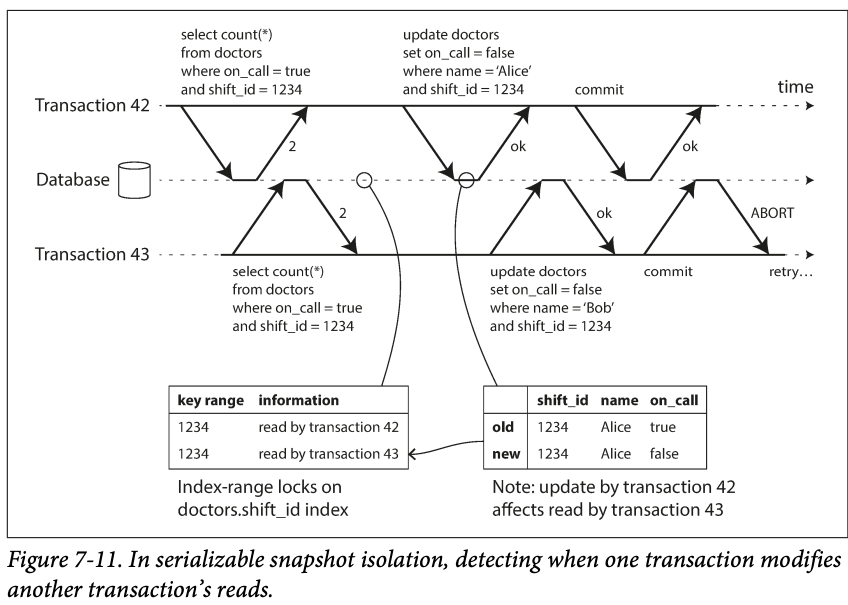
- It's like the index-range lock , except that SSI locks don't block other transactions
- If there is an index on shift_id, the database can use the index entry 1234 to record the fact that transactions 42 and 43 read this data. (If there is no index, table wise lock will be used)
- This information only needs t one kept for a while until the transactions is finished and all concurrent transactions have finished.
- When transaction 43 wants to commit if found the data it relies on has been changed , so it's aborted.
- When a transaction wants to write the data, it check if there are other transactions read the data recently -> it's like acquire a write lock on the affected key range.
Performance of serializable snapshot isolation
- Less tracking of transactions is faster but more transactions can be abort
- Compared to the 2PL, SSI doesn't block a transaction -> latency are predictable -> good for read heavy workloads
- Compared with serial execution, SSI is not limited to the singe CPI core.
- The rate of aborts significantly affects the overall performance of SSI.
- Long run read and write transaction has more conflict maybe -> SSI requires the read-write transactions be fairly short. (Long run read may be ok)
- It's less sensitive to slow transaction than 2PL serial execution