Chapter 8 The Troubles with Distributed Systems
Faults and Partial Failures
- In single machine, Good software /systems are either fully functional for entirely broker, but not something in between. -> we don't want the faulty result which cause useless work and confusing
- The nondeterminism an possibility of partial failure is what makes distributed system hard to work with -> some times it works well but sometime not, you sometime event don't know the failure due to the nondeterministic network failure
Cloud Computing and Supercomputing
- Large scale systems
- One end is the field of high-performance computing(HPC)-> large amount of CPU do computationally intensive tasks
- The other extreme is cloud computing, works with multi-tenant datacenter, commodity computers connect with IP network, elastic resource allocation, and metered billing
- Traditional enterprise datacenter lie somewhere between these extremes.
- Diffrent system handle faults in a different way
- Supercomputers raise single node failuer to the system failure and fix it
- We focus on the different part
- Many systems are online system -> availability is needed
- Supercomputers node are more reliable compared with commodity machines
- Large data centers networks are based on IP and Ethernet, arranged in Clostopologies to provide high bisection bandwidth while supercomputers use some special topology
- The bigger the system, the possibility of node failure higher so consist giving up is bad
- Fault tolerance is useful
- Geographically distributed deployment communication goes over internet which is slow compared with local networks . Supercomputers assume they are close to each other.
- Fault tolerance and partial failure : build reliable system with unreliable components
Unreliable Networks
-
We in the book talking about shared nothing system -> communicated with asynchronous packet network -> the message/packet are not guaranteed to delivered on time or even delivered
- Request could be lost -> someone unplugged a network cable
- Request is waiting in a queue and delivers after -> congestion control
- Remote node may have failed (power down)
- Remote node may have temporarily stopped responding (GC or .. )
- The remote node processed you message but response delayed
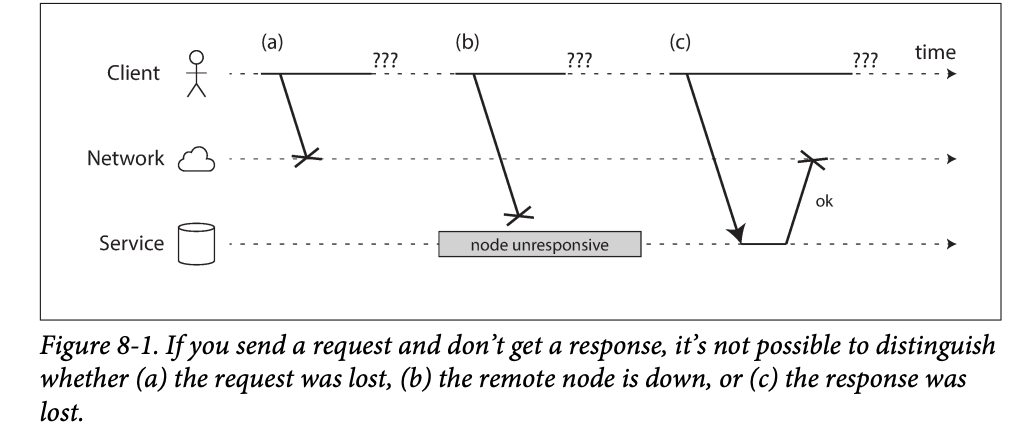
-
You don't know a response is lost or delayed so we use timeout
-
However, you don't know remote node processed you request
Network Facts in Practice
- Network issues are common
- Handling network problem doesn't necessarily mean tolerating them , you can thrown an error is your network is normally reliable.
Detecting Faults
- Many system automatically detect faulty nodes
- Load balancer don't sent request to dead node
- In single leader replication, new leader can be elected when a leader fails
- The uncertainty of the network makes it hard to know what's wrong
- You can reach a machine where the node should be running, by sending a FIN packet in reply, -> however, if the node crashed which it's handling the message, you don't know how many it processed
- If a node process is crash by the OS is running, a script can notify other nodes about the crash so others can taker over quickly without having to wait for a timeout.
- You may connect to the data center management layer if you are not connect via internet
- A router may or may not know the destination is failed -> depends on the router feature
- You cannot rely on the feedback from client -> even if TCP ack a packet is delivered, the node can crash while processing
- In general, you assume you get no response, you retry in the application level and wait for timeout and declare the node dead.
Timeout and Unbounded delays
- Determine timeout is hard
- Too should may kill some node working on heavy task
- Too long will waste time
- Delaracing a node is dead is problematic: it;s still alive and performing soem task, some other node takes over -> the task may be perform twice
- Take over to another node the responsibility has overheads -> if the system is overload, this makes things worse -> if the node is response slow due to the system overload, doing the transfer makes things worse and may let it down.
- Unbounded delays: async network has no guarantees on delivery and processing
Network congestion and queuing
- Queueing when
- Several nodes send packets simultaneously
- Destination node are CPU busy
- In an virtual environment, a running OS is often pause for sometime when another VM use a CPU core -> during which it cannot process any data
- TCP perform flow control -> queuing at sender
- TCP retransmitted when it thinks packet timeout and lost -> this consumes times like like queuing
- In a multi-tenant datacenter, resources are shared(network links and bandwidth , CPU) , as there is no control of resource allocation-> there might be delay due to a heavy resource consumer
- Timeout can be chosen experimentally: measure the distribution of network round trip times and determine the expected delay. The taking into account other characteristics
- Even better -> measure reins times and their variability(jitter), and automatically adjust timeout according to observed response time distribution. TCP retransmission works similarly. This is sued in Akka and Cassandra.
Synchronous vs asynchronous networks
- The data pass through use fixed allocated space(bandwidth), so there is no queuing -> so the delay is fixed -> bounded delay
Can we not simply make network delays predictable
- TCP will transmission any size of data using as much as available bandwidth. So it's different from the circuit
- Datacenter network and the internet were packet-switch networks -> to handle bursty traffic (the size of packet varies)
- If you want to use circuit you need to predict the bandwidth -> this may cause the transmission slow -> packet switch can use the bandwidths efficiently
- You can regard variable delays as a the consequence of dynamic partitioning. -> it's a trade off (time and space)
Unreliable Clocks
- In distribute systems, time is tricky because communication is not instantaneous -> it takes time for messages to travel across the network from machine to another.
- This make things hard to determine the order when involving multiple machines.
- Machines has their own clocks but not definitely the same , so synchronization may be possible . -> NTP network time protocol -> allows the computer clock to be adjusted according to the time reported by a group of servers. -> the servers get their time form more accurate time source like GPS.
Monatomic vs Time-of-Day clocks
Two kind of clocks of different purpose
Time-of-Day Clocks
- It returns the date and time according some calendar, such as
System.currentTimeMillis() - It's usually synchronized with NTP-> time on a machine is the same as others since they have the same truth of source
Monotonic clocks
- It's suitable for measuring a duration , such as timeout or a service response time.
- You can check the value of the monotonic clock at one time point, do something and check the value again, the difference tells you how much time elapsed between the two checks. -> the absolute value of the clock is meaningless (it might be the number of nanoseconds after the PC starts)
- In multiple CPU cores, there might be different timer for each CPU. OS will help composite the discrepancy and try to present a monotonic clock
- NTP may just the frequency at which the monotonic clock moves forward if it detects that the computers locally quartz is moving faster or slower than the server.
Clock Synchronization and Accuracy
- Hardware clocks and NTO can change:
- Clocks drifts due to temperature
- If the local clock differs too much from NTP server, it will refuse sync or forcible be synced. -> cause application rely on the time confused
- Firewall may accidentally firewall NTP server
- NTP sync relies on the network bandwidth
- NTP servers can be wrongly configured and inaccurate
- Leap seconds result in a minute 59 or 61 seconds -> causing trouble to some system that didn't handle this issue
- In a virtual machine, it syncs time from CPU, but it has suddenly pause (due to the CPU switch), this will cause the clock on the VM jumped suddenly
- Some devices time cannot be trust if you have no full control of the device -> some time and date are deliberately configured wrong.
- Higher accuracy are needed in some scenarios like high frequency trading , and can be achieved by GPS receives , the precision time protocol and careful deployment and monitoring
Relying on Synchronized Clocks
- The incorrect clocks easily go unnoticed and the system issues may be subtle
- Some monitoring may needed
Timestamps for ordering events
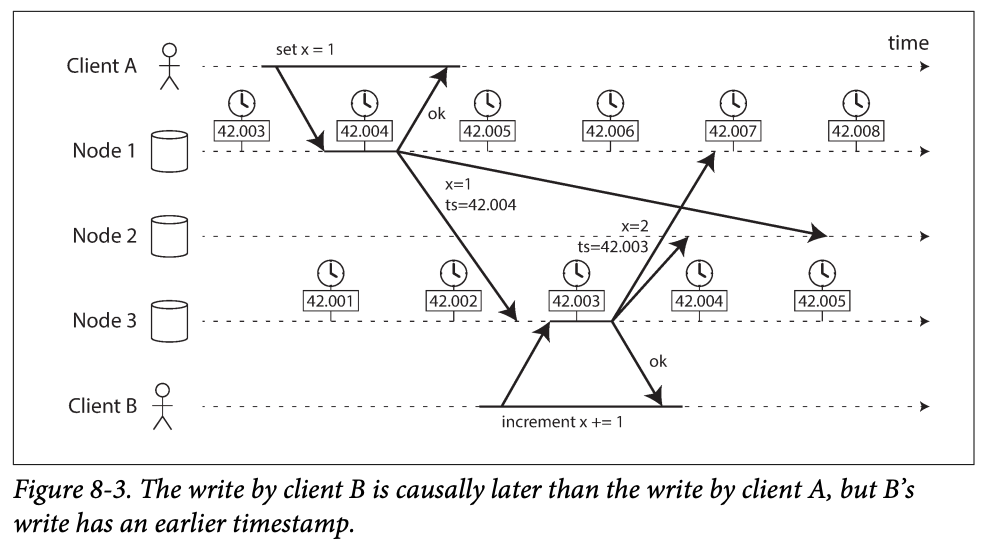
- The write by client B is causally later than the write by A, but B's write has ab earlier timestamp -> node 2 thinks x = 1 is the more rennet value -> B's change will be lost
- LWW : last write wins are designed for resolve this . And it's used in multi-leader and leaderless database such as Cassandra and Riak.
- Some implementations generate timestamps on the client rather than server. But this doesn't change the fundamental problems with LWW:
- Database write can be lost (due to clock)
- LWW cannot distinguish between write that occurred sequentially in quick secession
- Two clients generated write with same timestamp
- It important to be aware of that the definition of "recent" depends on the local time-of-day clock and it might be inaccurate
- NTP sync has its own limit -> networks delays
- Logical clocks are based on incrementing counters rather than quartz crystal, are a safer alternative.
Clock readings have a confidence interval
- The clock reading should be considered as a range of a time , with a confident internal -> the time read from NTP server has delay and drift.
- However, the uncertainty is not reported by many manufactures
Synchronized clocks for global snapshots
- In distributed system of implementing the snapshot isolation, we need database has a global monotonically increasing transactions ID -> this ID needs to reflect causality : if transaction B read a value that was written by A, then B must have a higher truncation ID than A. -> hard and can be bottleneck
- In order to ensure the transaction timestamps reflect causality, spanner deliberately waits for the length of the confidence interval before committing a read-write transaction -> it ensures that ant transition that many read the data is at a sufficiently later time, so their confidence internal don't overlap -> internal needs to be as small as possible -> google deploy GPS receiver in each datacenter
Process Pauses
-
How does a single leader based replication know it's a leader?
pseudocode while (true) { request = getIncomingRequest(); // Ensure that the lease always has at least 10 seconds remaining if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000) { lease = lease.renew(); } if (lease.isValid()) { process(request); } } -
This logic :
- It relies on synchronized locks : the expiry time on the lease is set by a different machine , and its being compared with local clock.
- Even if we change the logic to use only local monotonic clock, there is another problem : the code assume it's fast between check expire and the code and the time it processed the request -> no one tells the thread that another node takes over -> this can really happen when
- GC
- VM suspended
- Device suspend (user close the lid of the laptop)
- OS context switch or hypervisor switch to a different VM
- Sycnrvhnous disk IO and thread waits
- In a unix system , a SIGSTOP
- All these is like making multi-thread code on a single machine but in single machine, treads shard memory and have ways to avoid this: mutex, semaphores. Atomic counters ,...
- In a distributed system, a node can and needs to be stop without interfering others .
Response time guarantees
- Realtime is not real time, it defines the time guaranteed timing
- Making system real time relies on programing language, tools, and libs restriction
- So most server side applications accept repose pause and time instability
Imitating the impact of garbage collection
- Do GC as plan task and aware other nodes. -> others will know and don't sent request to this node.
- Use GC in a short lived objects and restart process periodically -> also planned
Knowledge, Truth and Lies
The Truth Is Defined by the Majority
- Quorum : voting among the node :
- Absolute majority or more than half the nodes.
The leader and the lock
-
Frenqeuuntly a system needs there is only one of something:
- In node is allowed to be the leader for a database partition to avoid split brain
- One transaction or client is allows to hold the lock for a particular resource or objet, to avoid concurrently writing to it and corrupting it.
- Only one user is allowed to register a username to identify a user.
-
The chosen one : be careful , when quorum thinks it's no longer the one, it's abandoned even if it considers itself as the one.
-
You want to ensure a file can only be access by a user to avoid corruption ->
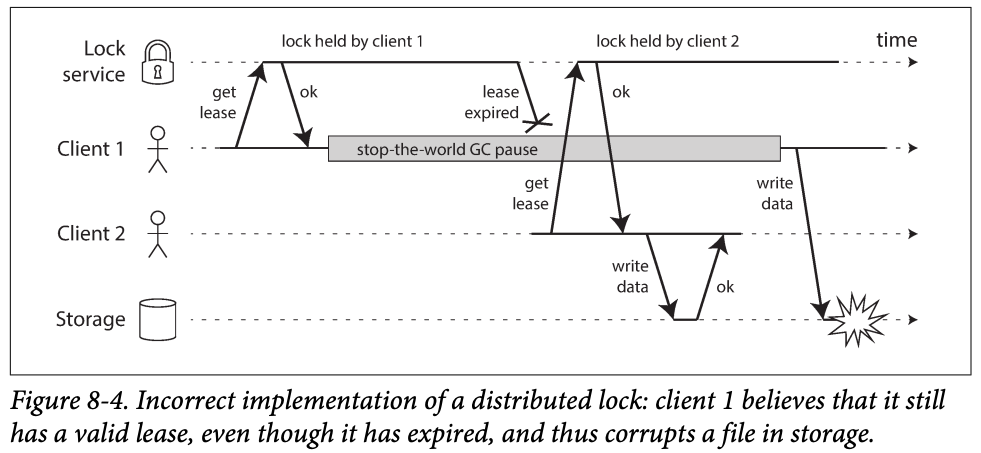
- If a client hold the lease is paused for too long, its lease expires .
- Another client can object a lease for the same file, and start writing to the file.
- When the pause client comes back , it believes (incorrectly) it stills has a valid lease and processed to also write to the file -> writes clash corrupt the file
Fencing tokens
-
To ensure the client 1 not to disrupt the rest of the system -> fencing
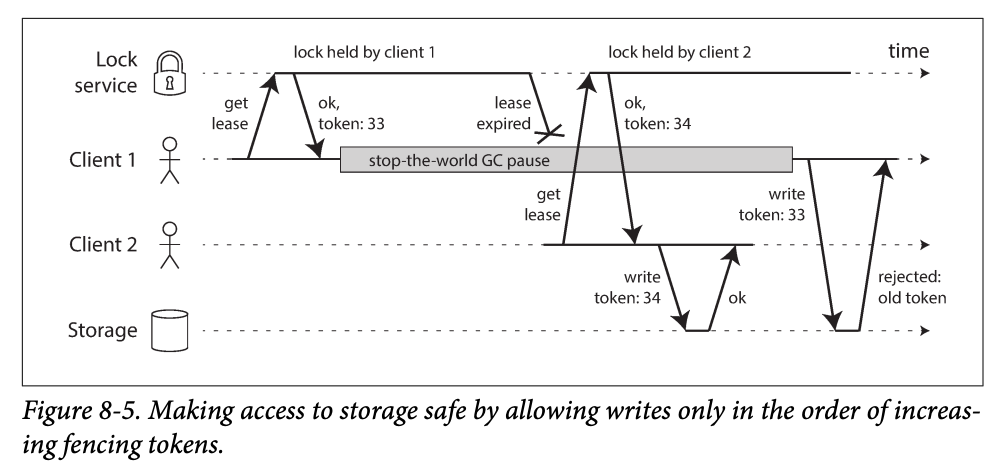
-
Every time the lock grants a lock or lease , it also returns a fencing token, which is a number increasing every time a lock is granted -> then the write to the storage needs to be with the token -> the storage remember the token and can find the expire token
-
This mechanism requires resource checkin the token -> it's wise to not assuming the client is good.
Byzantine Faults
-
What if a client send a fake token that bypassing the fencing?
-
Byzantine fault: a node declare it receives message while in actual it didn't
Byzantine fault tolerant: a system continue to work when some nodes are dishonest
-
We can assume in this book you have full control of the system -> we don't apply byzantine prevent algo in the suer input -> server can do this auth
-
Byzantine algo are more important in the system there is no center
-
Byzantine fault tolerance algo requires most nodes works well so if all nodes are gone or attacked, Byzantine fault tolerance algo does not work here.
Weak forms of lying
- Even system nodes are honest, it's worth to add machinism to prevent lies
- Packets are damaged due to many reasons -> checksum
- User input filter needs to be added in a public service
- NTP can be configured with multiple server address -> make it robust
System Model and Reality
- System models for timing issues
- Synchronous : you have bounded network delay, bounded process pause and bounded clock error
- Partial synchronous : system behave like synchronous models most of time, but sometimes exceeds bounded delay, pause or clock error -> common in real world .
- Asynchronous : system doesn't allow any timing assumptions
- System models for node failures
- Crash-stop faults : crash and down and never come back
- Crash recovery faults : crash and may return , may have stable storage to help recovery
- Byzantine faults: nodes can don anything (lies )
Correctness of an algorithm
- Properties to be clarify to define the correctiveness of an algorithm
- Uniqueness : no two requests for a fencing token return the same value
- Monotonic sequence : if request x returned token tx, and request y returns token tx, and x completed before y began, then tx , ty
- Availability: a node that requests a fencing token and doesn't crash eventually receive a response
Safety and liveness
-
What if all nodes delay becomes infinite long ? We can do nothing. So we have two types of properties
-
Uniqueness and monotonic sequence are safety properties and availability is liveness
-
Safety means nothing bad happens
-
Liveness : good things happens - > properties with "eventually"
In my view it's like safety properties defines you illness, and you can have illness but you cannot work well or correctly due to the effect, liveness is like your life, you finally recover or stay alive.
Mapping system models to the real world
- In real world there are many things that break the assumption and let the algorithm or theories doesn't work
- But in abstract, models help out simplify and focus on the key problem to analysis.