Chapter9 Consistency and Consensus
- We need to build systems that is fault tolerant -> can be with fault but still alive
- The best way of building fault tolerant system is to find some general purpose abstraction with useful guarantees , implement once and let the system rely on those grantees.
- Consensus : all nodes agree on something.
- e.g. in single leader replication , all nodes need the consensus that : there should be only one leader in the system
Consistency Guarantees
- In replication, data reach to different node at different time -> you may read different data at a time point from different nodes
- Eventual consistency: but they finally become the same -> better call : convergence
- This is a weak guarantee -> the eventual -> how long does it take for all nodes to have a consistent value?
- We talk about stronger guarantees in the chapter -> they have price: lower performance or less fault tolerance
- Distributed consistency model and hierarchy of transaction isolation levels
- They are similar and with some overlap but cannot be matched
- Transaction isolation is about avoiding race conditions due to concurrently executing transactions
- Distributed consistency is about coordinating the state of replicas in the face of delayed and faults
- Topics :
- Linearizability and examine the pros and cons
- Ordering events , particularly around causality and total ordering
- How to atomically committed a distributed transaction -> to the solutions for the consensus problem
Linearizability
- Make the system appear as if there were only one copy of data , and all operation on it are atomic
- A recency guarantee : it must see the data it just write
What Makes a System Linearizable ?
-
See an example first :
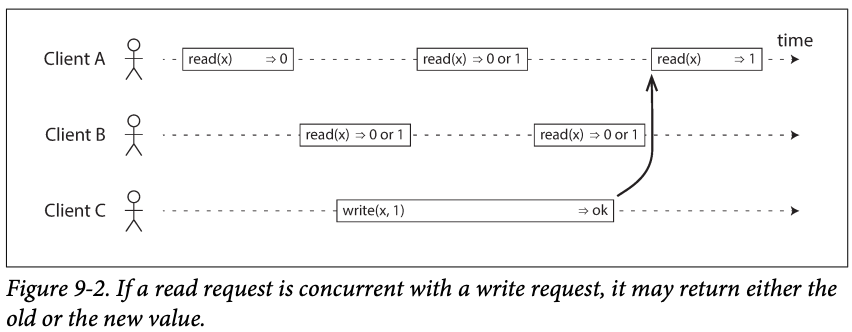
-
In the above graph,
- The first read of A read x before write x = 1, so it's definitely 0;
- The last read of A read x after write x = 1, so it's definitely 1;
- B's read has overlap with C's write so we don't know whether or not the write has taken effect as the time when the read is processed - >they are concurrent.
-
This is not linearizability
-
This is what we want for fully linearizability :
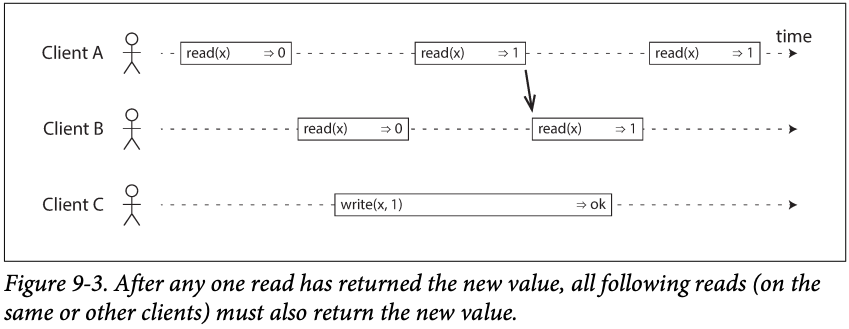
-
Once the x = 1 is read, all its following read must return 1 even the write hasn't complete.
-
Another example with compare and set

Compare and set means a write compare what it knows the original value , if successes the write new value
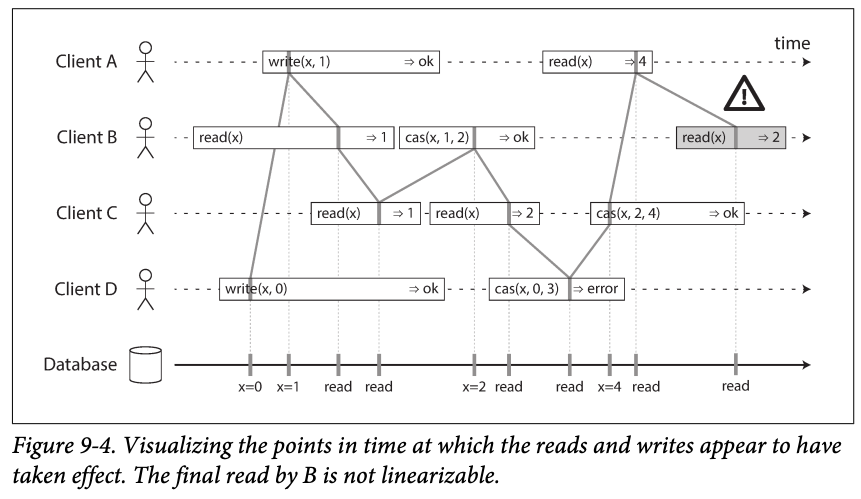
- The time line is important, each operation has a time point to read or flip the value (write the value in db)
- D, B.s read and A's write are not returned as they started order, this is ok since there might be delay of processing
- B's read return 1, while A's write isn't finish , this is ok, the actual flip in A is before B/s read -> this only means the ok response is delayed.
- B, D are concurrent so D's
casfailed due to old value is not 0 (it's 2) - B's final read is failed due to A returns 4 before (the 4 s set by C's
cas), so older value cannot be returned in the linearizable system
-
Linearizable vs serializable
- Seiralizalibity is an isolation property of transitions , where every transaction may read and write multiple objects -> it guarantee transactions in concurrent behave like in serial
- Linearizable : recency guarantee on reads and writes of a register (an individual object)
- Actual serial execution or implementation of serializability based on 2PL are typically linearizable
- Serializable snapshot isolation is not linearizable: it makes read from a consistent snapshot to avoid lock between readers and writers -> it doest include most recent writes
Relying on Linearizability
Application areas
Locking and leader election
- In a single leader election, a lock is used to ensure there is only one node being elected and avoid split brain.
- It must be linearizable -> we use coordination service -> ZooKeeper -> linearizable storage service for coordination tasks
- Distributed locking is also used. -> Oracle Real Application Clusters(RAC) uses a lock per disk page , with multiple nodes sharing access to the same disk storage system.
Constraints and uniqueness guarantees
- You need linearizability to enforce the constraint when the data is written.
- It's like a compare and set, all the nodes must have agreements on the value has a up to date value.
- Like bank transfer balance, seat booking, username registration
- In practice, the constant can be loosely -> if flight seats overbooked, we can move customer to a different flight.
- Hard uniqueness contains requires linearizability , other kinds of constraints, like foreign keys can be without it.
Cross-channel timing dependencies
-
Channel -> you have a stale query and new result needs a new channel
-
You have a website where users can upload a photo, a background process resize the photos to lower resolution for faster download(thumbnails)
-
The image resizes needs to be explicitly instructed to performa a resizing job.
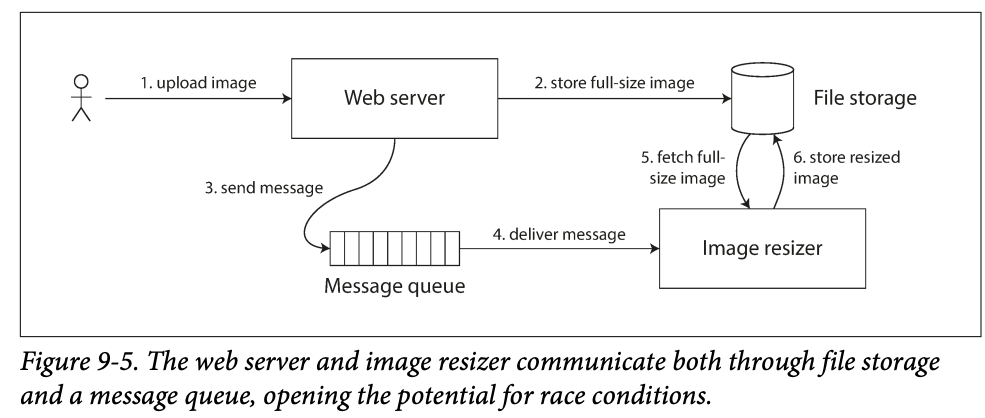
-
If the file storage service is not linearizable, there is a risk of race condition: the message queen might be faster than the internal replication inside the storage service
-
Two different channels -> file storage and message queue
-
Implementing Linearizable Systems
- Single leader replication -> potential linearizability : if the you can read from leader , then it can be linearizable, however, if a node is not a leader while it thinks it's leader, then read to it might violate the linearizability
- With async replication, failover may even lose committed writes , violating both durability and linearizability
- Consensus algorithm (linearizability) -> Zookeeper and etcd works like this
- Multi-leader replication (not linearizable) : they concurrently process writes in many nodes and asynchronous replicate them to other nodes. -> the can produce conflicting writes -> no single copy of data
- Leaderless replication (probably node linearizable):
- LWW conflict resolution based on time-of-day clocks in Cassandra are almost certainly nonlinearizability -> clock timestamps cannot be guaranteed to be consistent with actual event ordering due to clock skew
Linearizability and quorums
-
Strict quorum may have lineaerizable in a Dynamo0style model -> why may -> network delays
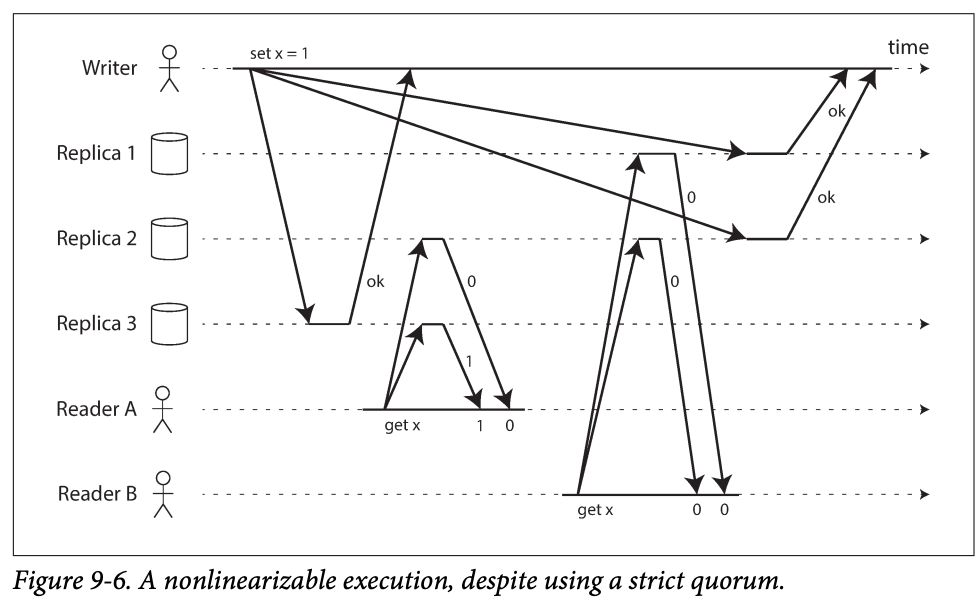
- A writer client is updating x to 1 by sending the write to all three replicas(n=3, w=3), concurrently, A reads from a quorum of two nodes (r=2), and sees the new value 1 on one of the node. Also concurrently, B read forms the other two nodes and get back old value 0 from both.
- The quorum condition met(w + r > n), but this is not linearizability -> b's request starts after A but returns old value
-
It can be linearizable with performance reducing: a reader must performa a read repair synchronously , before returning the result to the application , and a writer must read the latest state of a quorum of nodes before sending it's writes.
- Riak doesn't perform synchronous read repair
- Cassandra does wait for read repair but lose linearizability if there are many write to the same key.
The Cost of Linearizability
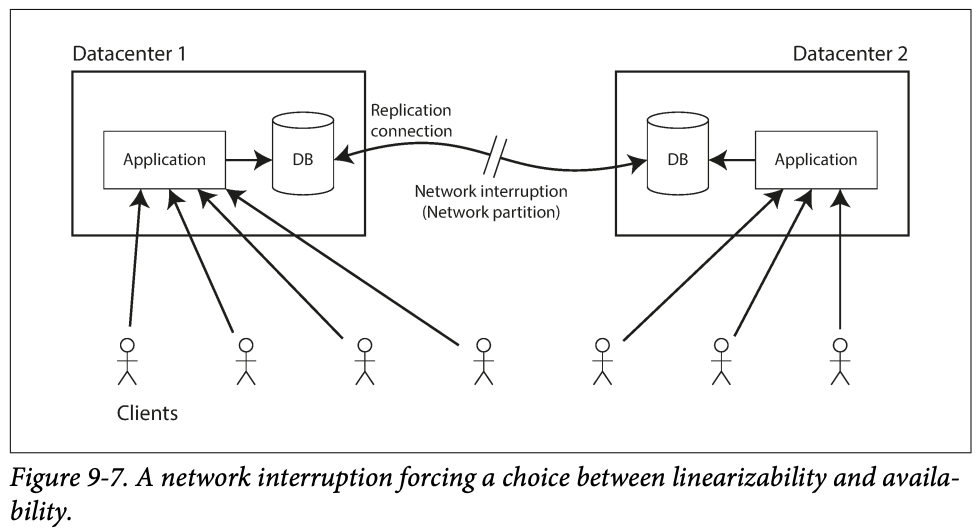
- If the network interrupted between two data center
- In a single leader -> if read from DC that has no leader, it has stale old value
- If read from leader DC, then the other DC are unavailable to keep the linearizability
- In a multi-leader replication
- The sync cannot be done, but each DC can work -> they can change data async when network is back
The CAP theorem
- If your application requires linearizability, and some replicas are disconnected from the other replicas due to a network problem, then some replicas cannot process request while they are disconnected : they must either wait until the network problem is fixed r return an error (unavailable)
- If you app doesn't require linearizbaility, then it can be written in a way that each replicas can process request independently, even if it's disconnected from other replicas. in this case, the application can remain available in the face of a network problem , but its behaviors is not linearizable
- This is CAP
Linearizability and network delays
- Linearizbaility are not common in reality
- RAM in Multicore cpu they are not since they have their own memory cache and storage buffer -> memory access first goes to the cache by default, and ant changes are async written out to main memory. (Access cache for performance )
- The we have several copies of data -> in memory , in caches -> and they are async updated -> no linearizability
- This is ok we don't expect any single CPU can work independently - >we pursue performance rather than fault tolerance
Ordering Guarantees
- In single leader replication, the single leader needs to ensure the order of write to avoid conflict in multiple leader
- Serializability is about to ensure transactions behave like executed in sequential order
- Use of timestamp and clock is a way of trying to keep order
Ordering and Causality
- Orders prevent causality
- e.g.
- Causality dependency : people see the question before the answer
- In multi-leader replication, leaders may receive some updates to rows not existing. -> causality : rows must be created before updated
- Happened before is another causality : A happened before B means b may know or depend on A's existing
- In snapshot isolation for transactions, -> transaction read from consistent snapshot -> consistent : -> causality consistent : if it reads an answer, it must can read an question for the answer
- Write skew : the on call shift issue -> SSI serialization snapshot isolation tracks causal dependencies between transaction
- ...
- Causality consistent: a system obeys the ordering imposed by causality
The causal order is not a total order
- Linearizability has total order -> strict timeline , one happens after the other, no concurrency
- Causality: two operations are concurrent if neither happens before the other . -> it sometimes happen
Linerizability is stronger than causal consistency
- Linearizabiliy prevent causality -> the strict timeline cures that things are in good causality
- But linearizability has price: performance and availability
- Middle land: causality consistent without incurring the linearizability , and also keep the performance
Capturing causal dependencies
- To maintain causality consistency , you need to know the happen-before relationship
- This is a partial order: if you have one happened before relationship in one replica, you must have it in all replica
- Version vectors used across the whole databases to track the happen before relationship
- Similar to the serializable snapshot isolation
Sequence Number Ordering
- Practical way to order events: seance number or timestamp (logic clock)
- We relies on that if A casually happened before B, then A occurs before B in the total order(or has lower sequence number)
- Concurrent operations ordered arbitrarily
- In single leader replication, a counter is assign to each operation monotonically increasing.
Noncausal sequence number generators
- If there is no single leader doing the allocation, in practice , we can :
- Each node generate its own independent set of sequence numbers. With some. Stretegy, you can avoid sequence number conflicts : if you have two node, one can be odd and one can be even
- You can attach a timestamp form a time-of-day clock to each operation,-> no sequential, but if high resolution, can preserve the total order to some high extend
- Like method1, preallocate blocks for each node, A has 1-1000, B has 1001-2000...
- All of these methods has no causality consistency
- Nodes can be fast and slow, if you have a node fast, say 1,3,5,7,9, but the other is 2, you cannot tell the causality
- Timestamp from a physical clock has clock skew
- Block allocator 1001 and number 1 cannot tell the order
Lamport timestamps
- Lamport timestamp:
- Each node has a unique identifier , and each node keeps a counter of the number of operations to has processed
- The Lamport timestamp is a pair of (counter, node ID).
- Two node may have same counter but they have node id so make the timestamp identical.
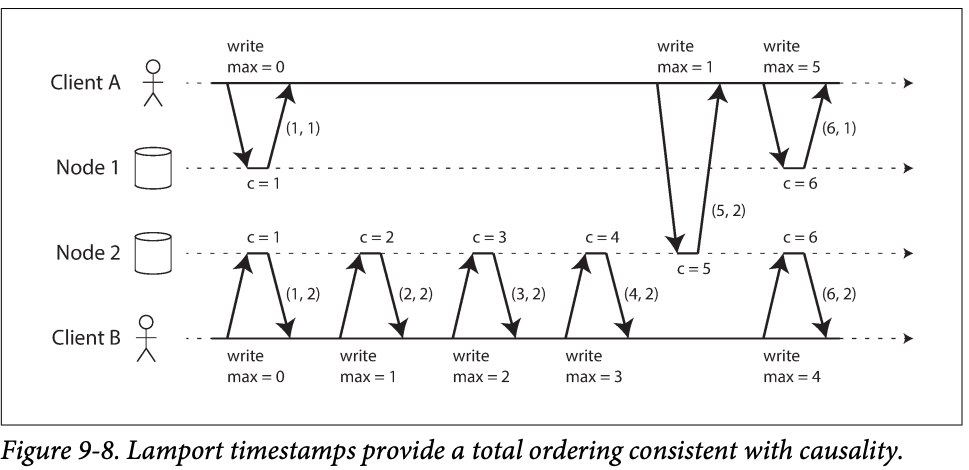
- if you have two timestamp, one with higher counter is the greater timestamp; if the counter values are the same, the one with the greater node ID is the greater timestamp
- The difference between odd/event counter in the last section and Lamport timestamp is that every node and every client keeps track of the max counter value it has seen so far, and includes that max on every request -> when node receives a request/response with a max counter greater than its own counter value, it immediately increases its own counter to that max.
- Difference with version vectors:
- Vv can distinguish whether two operations are concurrent or whether one is causally dependent on the other
- Lamport timestamps always enforce a total order.-> you can't tell concurrent or they are causally dependent
Timestamp ordering is not sufficient
- e.g. to identify a username is identical -> it needs instantly but it need to check other nodes values -> the total order only emerges after you have collect all of the operations
- Not only to have the total ordering of operations , you also need to know when that order is finalized (next section)
Total Order Broadcast
- How to scale the system if the throughput is greater that a single leader can handle ; and how to failover if the leader fails
- It relies on:
- Reliability delivery : no message lost , if a message is delivered to one node, it;s delivered to all nodes
- Totally ordered delivery: messages are delivered to every node in the same order
Using total order broadcast
- State machine replication: each replica process the same writes in the same order -> the remain consistent with each other. - .application of total order broadcast
- Implementing serializable transactions:
- The order is fixed at the time the messages are delivered
- It's like a append-only log, every node can see it and obey the sequence.
Implementing linearizable storage using total order broadcast
- Steps:
- Append a message to the log
- Read the log and wait fro the message you appended to be delivered back
- Check for any messages claiming the username that you want. If the first message for your desired username is your own message you are successful , otherwise you abort the operation.
- The read might be inconsistent -> you read a node that is async update from the log.
- Read the log like the write
- Read from sync replica
- Read the latest log in a linearizable way -> if you have the position
Implementing total order broadcast using linearizable storage
- Steps:
- You have a linearizable register
- for every message you want to send through total order broadcast, you increment-and-get the linearizable integer, and then attach the value you got from the register as a sequence number to the message. You can then send the message to all nodes (resending any lost messages), and the recipients will deliver the messages consecutively by sequence number.