So in last few days, I have a PR that violates the PMD rule which shows like:
Consecutively calls to StringBuffer/StringBuilder .append should reuse the target object. This can improve the performance.
So I google it and find some people also encountered same issue and a cool guy gave a detailed experiment and I'd like to write it down here.
We have two code segment:
public class Main { public String appendInline() { final StringBuilder sb = new StringBuilder().append("some").append(' ').append("string"); return sb.toString(); } public String appendPerLine() { final StringBuilder sb = new StringBuilder(); sb.append("some"); sb.append(' '); sb.append("string"); return sb.toString(); } }
The javap command disassembles one or more class files. Its output depends on the options used. If no options are used, javap prints out the package, protected, and public fields and methods of the classes passed to it. javap prints its output to stdout. For more details and arguments you could find it here.
We compile with javac, javac -Main.javaand check the output with javap -c -s Main.class. -c will give us the bytecode of this java code segment. And I got:
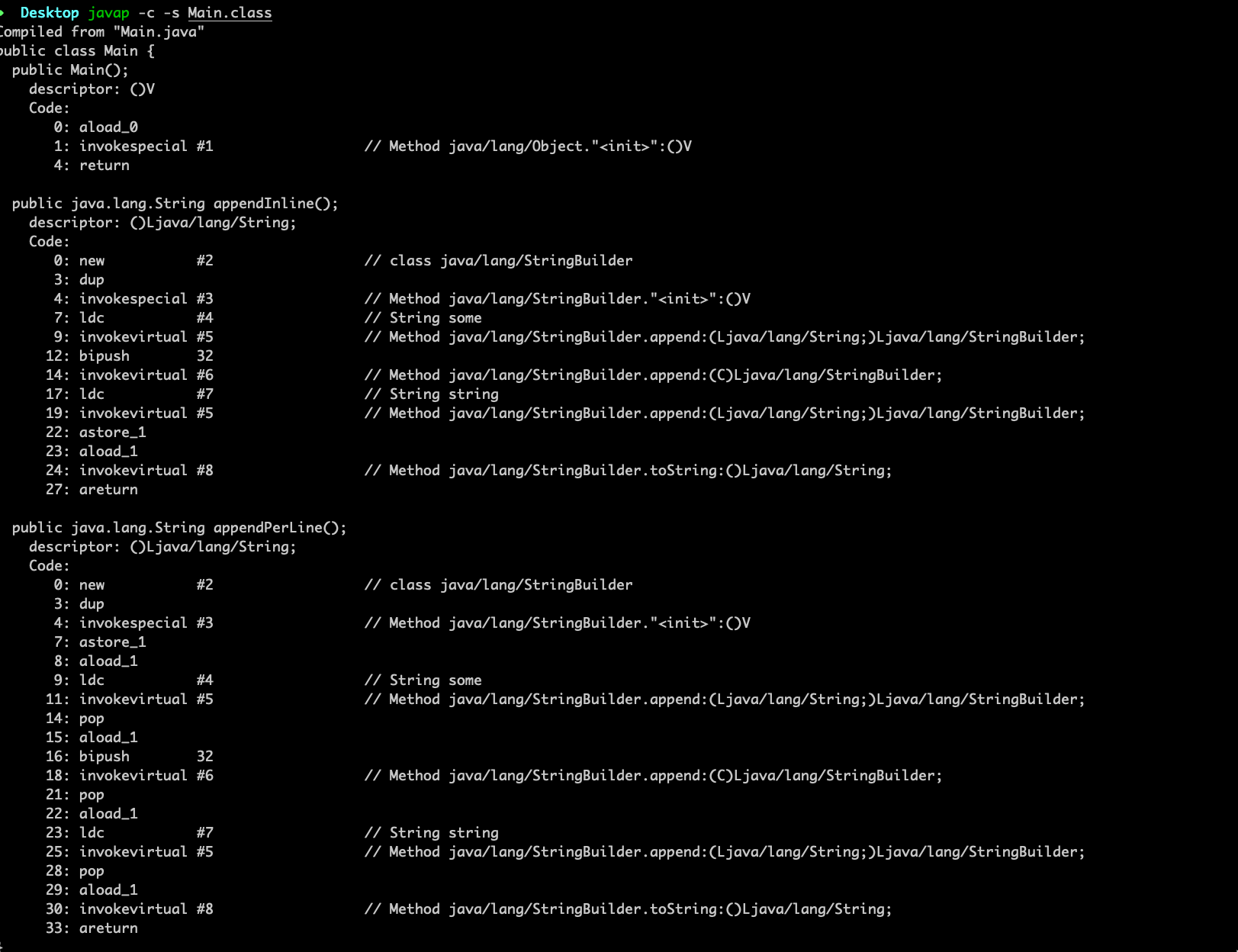
As seem, several extra aload_1, and pop were produced,(this load and pop operate the stringBuilder from the stack).
The second method will produce a large calcite and has greater overhead.
Somebody may claim that the JVM would optimize this after warming up, so we did a experiment using JMH to benchmark this behaviour:
import org.openjdk.jmh.annotations.Benchmark; import org.openjdk.jmh.annotations.Param; import org.openjdk.jmh.annotations.Scope; import org.openjdk.jmh.annotations.State; @State(Scope.Benchmark) public class StringBenchmark { private String from = "Alex"; private String to = "Readers"; private String subject = "Benchmarking with JMH"; @Param({"16"}) private int size; @Benchmark public String testEmailBuilderSimple() { StringBuilder builder = new StringBuilder(size); builder.append("From"); builder.append(from); builder.append("To"); builder.append(to); builder.append("Subject"); builder.append(subject); return builder.toString(); } @Benchmark public String testEmailBufferSimple() { StringBuffer buffer = new StringBuffer(size); buffer.append("From"); buffer.append(from); buffer.append("To"); buffer.append(to); buffer.append("Subject"); buffer.append(subject); return buffer.toString(); } @Benchmark public String testEmailBuilderChain() { return new StringBuilder(size).append("From").append(from).append("To").append(to).append("Subject") .append(subject).toString(); } @Benchmark public String testEmailBufferChain() { return new StringBuffer(size).append("From").append(from).append("To").append(to).append("Subject") .append(subject).toString(); } }
And the results:
Benchmark (size) Mode Cnt Score Error Units StringBenchmark.testEmailBufferChain 16 thrpt 200 22981842.957 ± 238502.907 ops/s StringBenchmark.testEmailBufferSimple 16 thrpt 200 5789967.103 ± 62743.660 ops/s StringBenchmark.testEmailBuilderChain 16 thrpt 200 22984472.260 ± 212243.175 ops/s StringBenchmark.testEmailBuilderSimple 16 thrpt 200 5778824.788 ± 59200.312 ops/s
So, even after warming up, the chained append also produce a ~4x improvement.
Does it even matter? It depends. This is certainly a micro-optimization. If you used a bubble sort in the project and this is not the guy who cause the main performance issue.
Different PMD rules is meaningful to different projects. Some may value performance significantly while others value other rules. Choose the right rules that matter to you.