- What is rate limiter: it's used to control the rate of traffic sent by client or a service.
- In the HTTP world, it limits the number of request allowed to be sent in a specific period. If the request count exceeds the limit, the request will be blocked.
- The benefits:
- Prevent servers from being overloaded. & Prevent resource starvation caused by DDoS(intended or unintended).
- Reduce cost. You do not need to proceed too many request in certain time period.
Step1 - Understand the requirement and establish design scope
-
Type: client vs server? - server side
-
Based on what? API ? IP? Or some properties? - flexible
-
Scale? Large vs startup? - large number
-
Distributed system? - Yes
-
Separate service or in application code? - you could decide
-
Should users be informed? - Yes
-
Requirements
-
Accurately limit excessive requests.
-
Low latency?
Is this a requirement proposed by interviewer or it's come up with by the interviewee?
-
Use as little memory as possible ?
Same question like the above.
-
Distributed. Could be sharded across multiple servers.
-
Exception handling. When user's requests were throttled, drop it silently? Put the into queue? Or return a HTTP code 429 to the client?
-
Fault tolerance. If the rate limiter down, it should not affect normal business logic working.
-
Step2 - Propose high-level design and get buy-in
- Keep things simple at first and user a client-server model.
Where to put it?
-
Client side. Can be forged by malicious users. We do not have control over client implementation.
-
Server side.
-
Implement it as a middleware.
What is a middleware? A software that provides services between applications. "Software glue".
-
It can be put into the API gateway.
- microservice: What is microservice
- API gateway: What is API gateway, it can be used to support rate limiting, SSL termination, authentication, IP whitelisting...
-
How to decide?
- Tech stack in the company
- Algorithms the meet you needs.
- If you have had a microservice and include API gateway, you may add rate limiter to it.
- Build your own take times. If you don't have too much people or time, a third party service is good.
Algorithms for rate limiting
Token bucket algorithm
The token bucket algorithm work as follows:
-
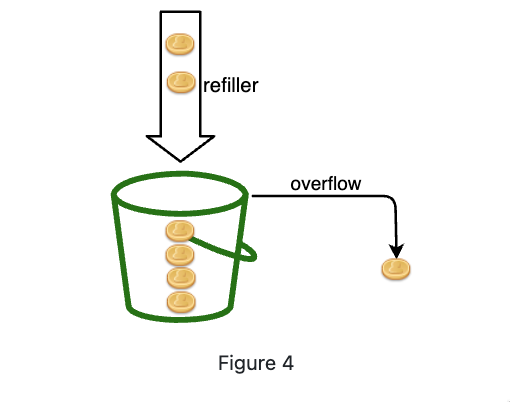
A token bucket is a container that has pre-defined capacity. Tokens are put in the bucket at preset rates periodically. Once the bucket is full, no more tokens are added. As shown in Figure 4, the token bucket capacity is 4. The refiller puts 2 tokens into the bucket every second. Once the bucket is full, extra tokens will overflow.
-
How it works
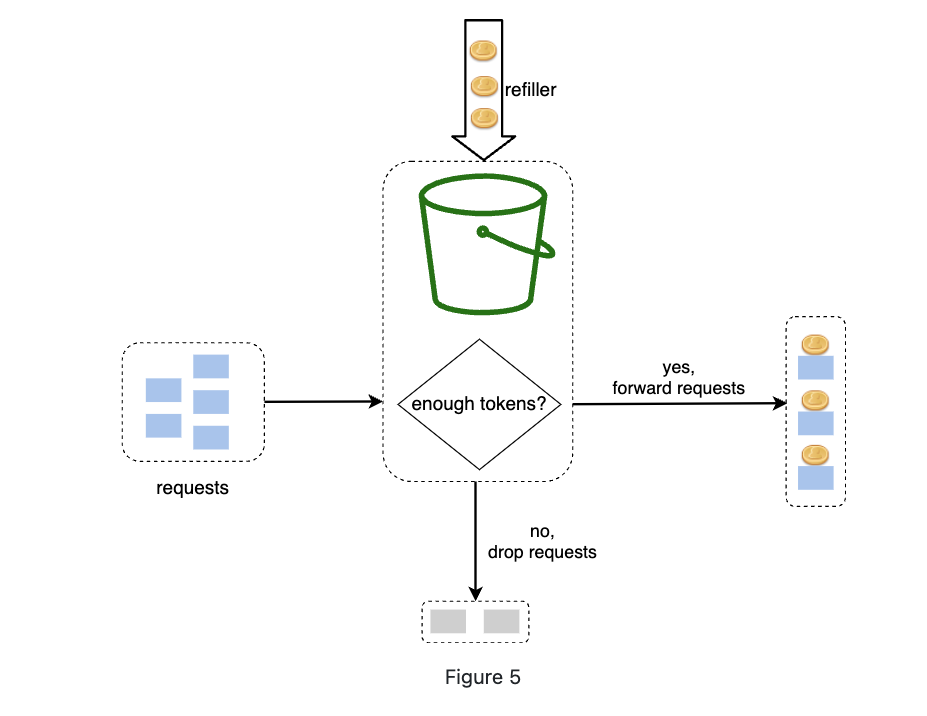
-
How many buckets do we need?
-
It depends.
-
Usually different buckeys for different api endpoints
-
If you are using IP based, each IP should have one bucket
-
If you allow 10000 request per sec, you could have a shared big bucket.
-
-
How many tokens(bucket size) do we need? What should be the refilling rate?
- Maximum rate requests can be processed
- Desired burstiness you could allow
- Traffic patterns. If you are expriencing a spike occasionally, you may want to use a larger size.
- Consequence of exceed the limit.
- Performance impact. Larger size and refill rate may require more server resources.
-
Pros:
- Easy to implement ;
- Memory efficient;
- Token bucket allows a burst of traffic for short periods. A request can go through as long as there are tokens left
- The bucket could be not full so the token can be accumulated. So when a client send data, the token is more than the fixed rate of refill. The reqeust can consume the token and may cause the burst, hwoever, if the request comes too fast and the token was run out, it will be throttled until next refilling.
-
Cons:
- Challenge on tune the parameters.
Leaking bucket algorithm
It is similar to token bucket, except that the bucket turns out to be a queue, with a stable consumer(out rate). It also has two parameters: bucket(queue) size and outflow rate.
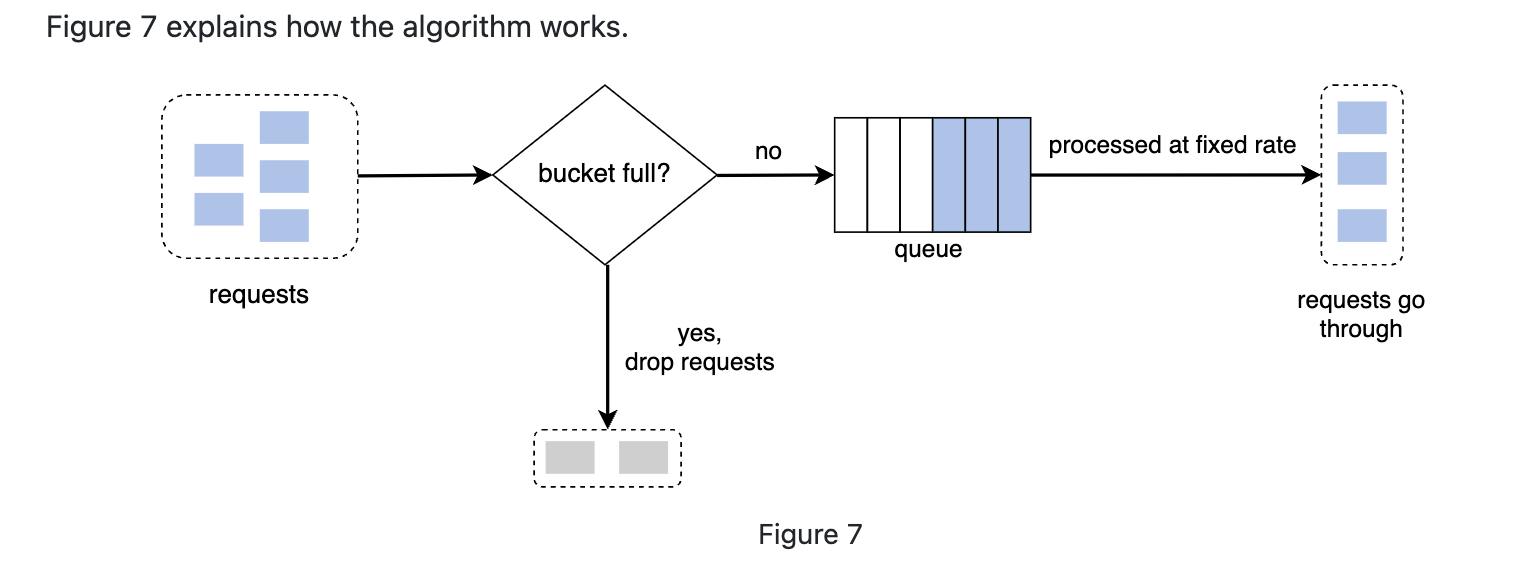
Pros:
- Memory efficient given the limited queue size;
- Suitable for use cases that a stable outflow rate is needed. (Flow and traffic control)
Cons:
- Two parameters, not easy to tune them properly
- A burst of traffic fills up queue with old request and if they are not processed in time, recent request are rate limited. While token bucket allow a burst.
Fixed window counter
-
Fixed window counter algorithm works as follows:
-
The algorithm divides the timeline into fix-sized time windows and assign a counter for each window.
-
Each request increments the counter by one.
-
Once the counter reaches the pre-defined threshold, new requests are dropped until a new time window starts.
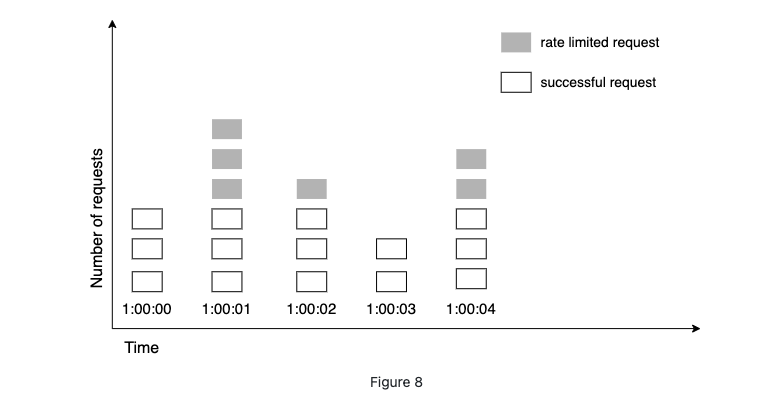
-
-
The problem is that
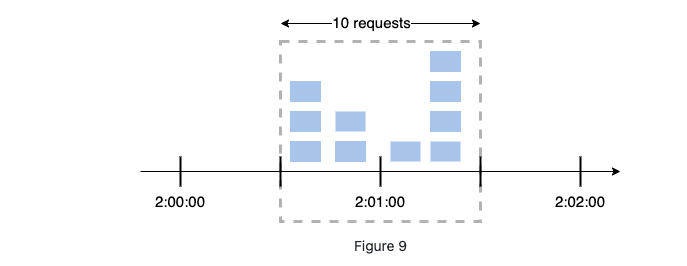
-
Pros:
- Memory efficient
- Easy to understand
- Resetting available quota at the end of a unit time window fits certain use cases.
-
Cons
- Spike in traffic at the edges of a window could cause more request than quota.
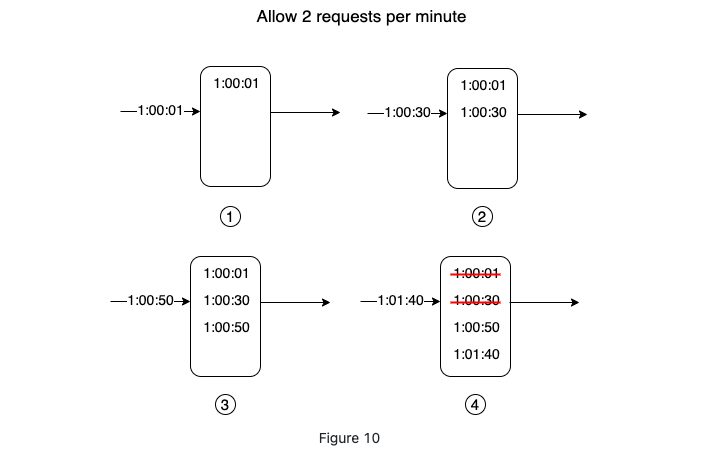
Sliding window log
-
As discussed previously, the fixed window counter algorithm has a major issue: it allows more requests to go through at the edges of a window. The sliding window log algorithm fixes the issue. It works as follows:
-
The algorithm keeps track of request timestamps. Timestamp data is usually kept in cache, such as sorted sets of Redis [8].
-
When a new request comes in, remove all the outdated timestamps. Outdated timestamps are defined as those older than the start of the current time window.
-
Add timestamp of the new request to the log.
-
If the log size is the same or lower than the allowed count, a request is accepted. Otherwise, it is rejected.
-
- Pros
- Very accurate, in any rolling window, the request will not exceeds quota.
- Cons
- Consumes lots of memory because rejected request timestamp is also logged.
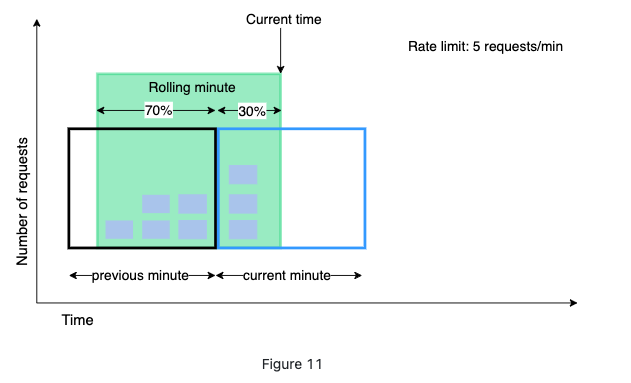
Sliding window counter
-
Hybrid of fixed window counter and sliding window log.
-
-
Assume the rate limiter allows a maximum of 7 requests per minute, and there are 5 requests in the previous minute and 3 in the current minute. For a new request that arrives at a 30% position in the current minute, the number of requests in the rolling window is calculated using the following formula:
- Requests in current window + requests in the previous window * overlap percentage of the rolling window and previous window
- Using this formula, we get 3 + 5 * 0.7% = 6.5 request. Depending on the use case, the number can either be rounded up or down. In our example, it is rounded down to 6.
Since the rate limiter allows a maximum of 7 requests per minute, the current request can go through. However, the limit will be reached after receiving one more request.
-
pros
-
Smoot spike issue of fixed window counter
-
Memory efficient
-
-
Cons
- Proportion will cause an approximation. So it works for not-so-strict look back window. However experiment indicates that the error rate is very slow.
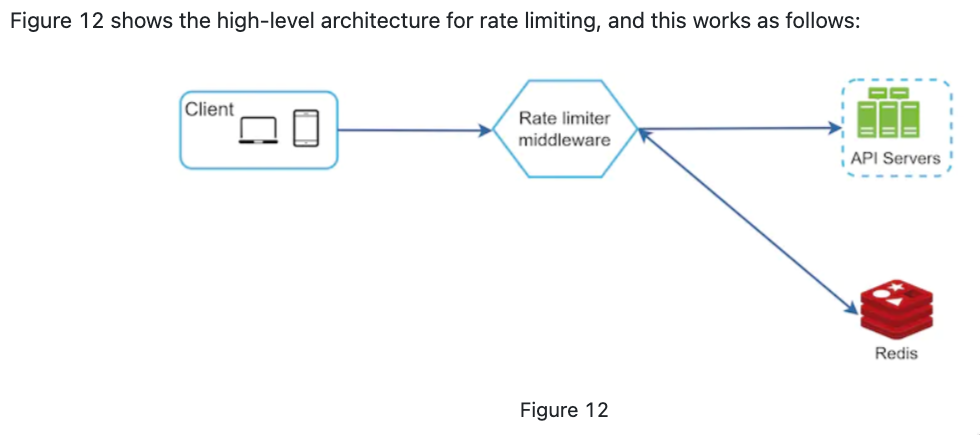
High-level architecture
-
We need a counter for rate limiter in high level.
-
Store counters in disk is slow so we may choose in-memory cache. 1. Fast 2. Support time-based expiration strategy. (e.g. Redis)
Step 3 - Design deep dive
-
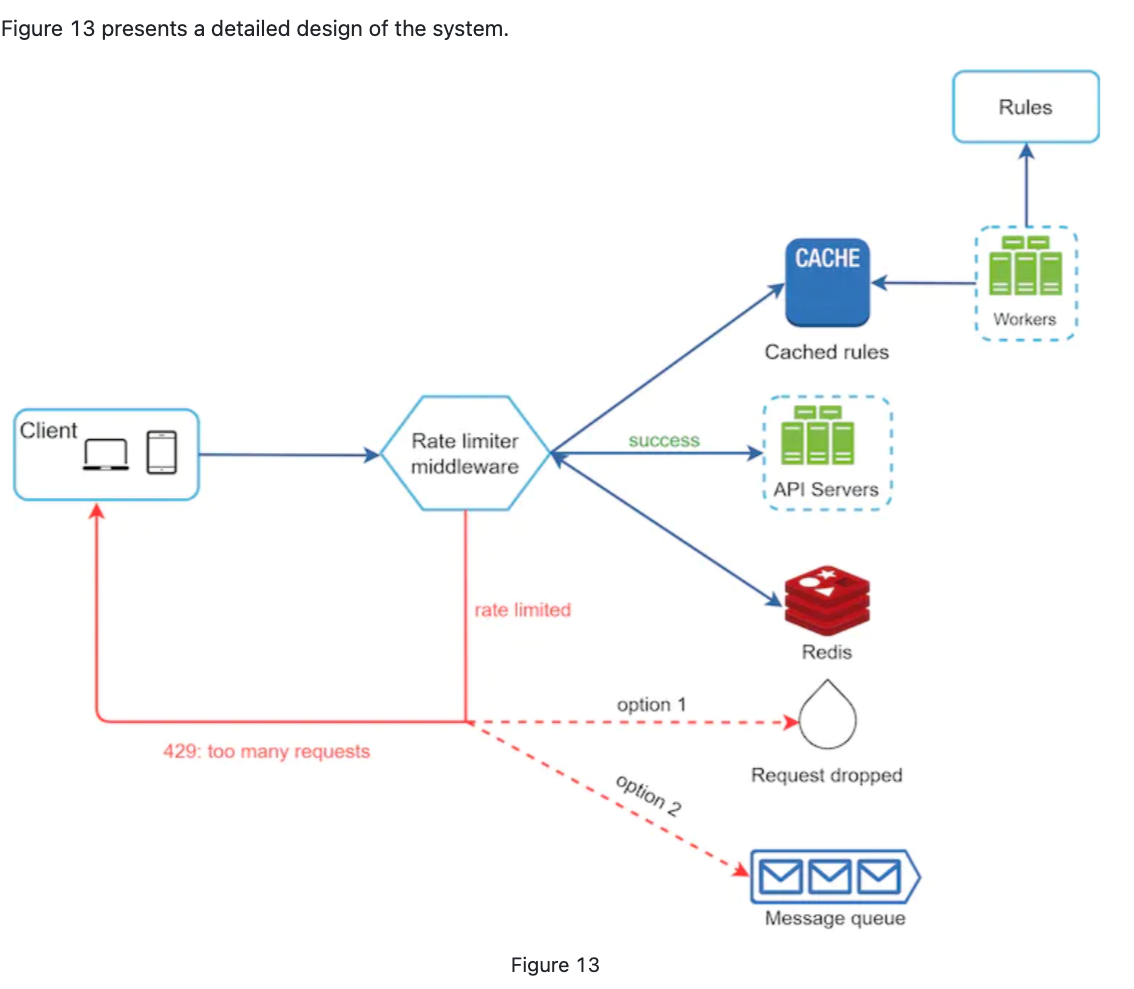
How the rate limiting rules created? Where are they stored?
An example:
domain: messaging descriptors: - key: message_type value: marketing rate_limit: unit: day requests_per_unit: 5In the above example, the system is configured to allow a maximum of 5 marketing messages per day.
-
How to handle limited requests?
- Stored in queue and process later
- Drop
Detailed Design
-
Rate limiter in distributed environment
- Challenges: Race condition and Synchronization issue(consistency)
- Race confidtion
- Ways to solve
- Lock(impact performance and not recommended)
- Lua script
- Sorted sets data structure
- Ways to solve
- Ways to solve synchronization issue:
- Send to same rate limiter (not scalable and fault tolerance)
- Store date in a centralized data center.
-
Performance
-
multi-datacenter set up around all the world.
-
Synchronize data with eventually consistency model
-
-
Monitoring
- Drop count/rate to adjust threshold/or be aware of traffic jam.
Step 4 - Wrap up
-
Algrithoms
- Token bucket
- Leading bucket
- Fix window
- Sliding window log
- Sliding window counter
-
System architecture, rate limit in distributed system, performance, monitoring
- Additional quetsions
- Hard vs soft rate limiting
- Rate limiting if different levels(Application vs IP vs others)
- Ways to avoid rate limited
- Use cache to avoid frequent calls
- Understand the limit
- Exception and response to customer so they know what happened and how to recover.
- Retry logic.