System Design Case Study 3 - Design A Key Value Store
This question or case is too broad at first, to design this problem, we must have a basic overview of distributed system and know what counts and what the trade offs are... Or you even do not know what to ask and which aspects to think about...
What's more, this case study is trying discuss every thing it could while in reality, we could specify the problem. However, as I said before, you need to know all the options(basic knowledge) then you can choose.
Understand the problem and establish design scope
Functionality requirements
- Key value pairs store
- Support get(key)-returns value; and put(key, value) to store new pair.
Non-functional requirements
- The size of the pari is small: less than 10KB
- Store big data(I don't understand what big data is, large volume data or something else)
- High availability: the system can response quickly even during failures;
- High Scalability: the system can be scaled to support large data set;
- Automatic scaling: the addition/deletion of servers should be based on traffic;
- Tunable consistency.
- Low latency.
Key Components
- Data partition: for scalability
- Data replication: for scalibility
- Inconsistency handling: for consistency
- Failure handling
- Write path
- Read path
High Level Design
Single server k-v store
- We could start from single server first.
- To support fast R/W, we store things in the memory
- Although memory has a limit
- Data compression
- Store some infrequently used data in disk
- This also has a limit, and doesn't meet many requirements list above.(failover, scale...)
Distributed k-v store
CAP theorem
-
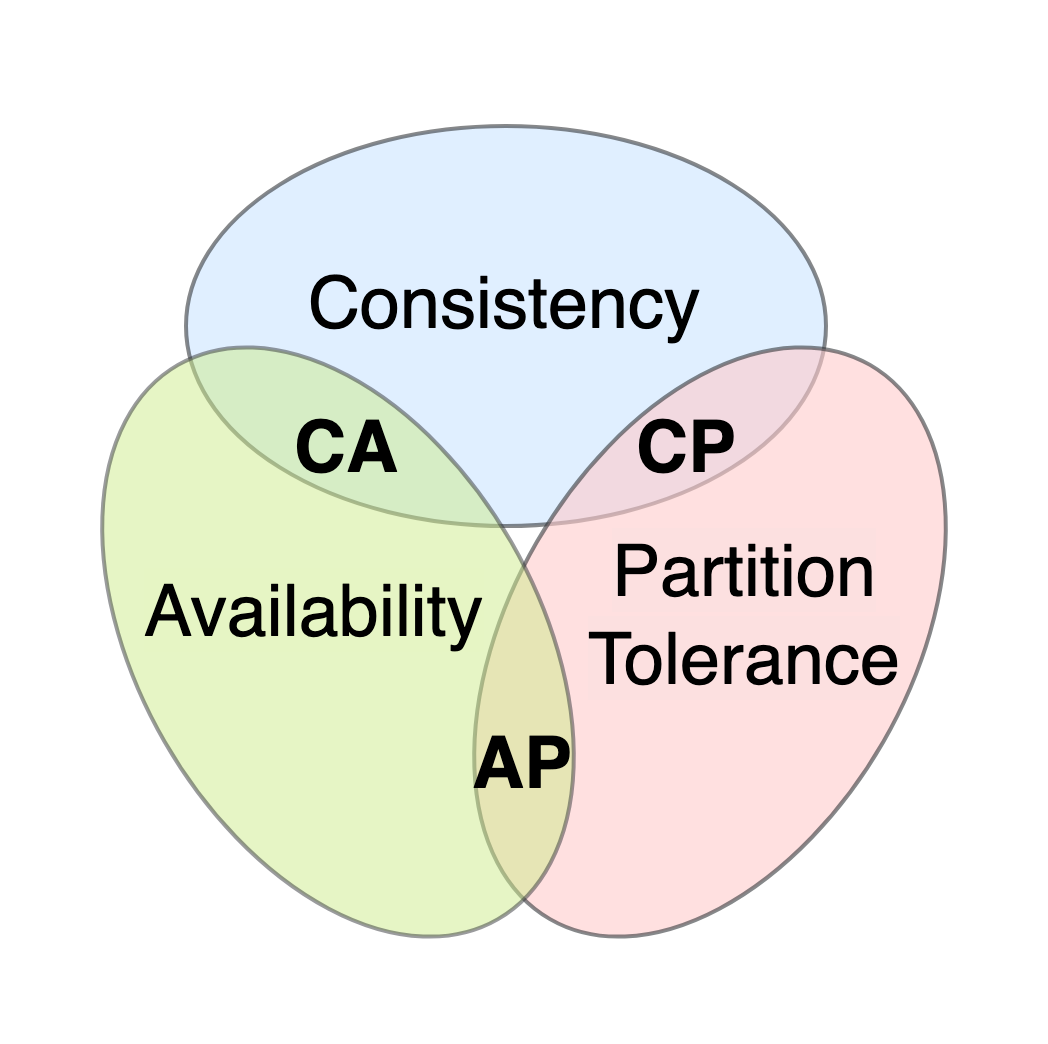
In distributed system, only tow of CAP could be satisfied.
-
C: consistency. All clients see the same data at the same time.
-
A: availability. Any client which requests data get a response event if some nodes are down.
-
P: partition tolerance. System continue to operate despite network partitions.
-
Key-val store are classified to two kinds based on CAP:
- CP: can sacrifice availability. If inconsistency occurs, we must block the service until all the data is consistent.
- AP: can sacrifice consistency for availability. Can tolerate inconsistency and achieve the eventual consistency.
- CA: since network is unavoidable, a distributed system must tolerate network partition. Thus CA key-val store doesn't exists in real world.
Discuss with interviewer which on you guys want to further design.
Detailed discussion or component level design
Data partition
- For large applications, it's not feasible to fit the complete date in a single server;
- To distributed the data evenly and minimize data movement when adding or removing servers, we use consistent hashing.
- Auto scaling: servers could be added and removed automatically depending on the load.
- Heterogeneity: the number of virtual nodes for a server is proportional to the server capacity. For example, servers with higher capacity are assigned with more virtual nodes.
Data Replication
- Data must be replicated to N(configureable) servers asynchronously to achieve availability.
- For higher availability, data replication can be spread to multi-datacenter.
Consistency
-
Quorum consensus can guarantee consistency for both read and write,
**N ** = the number of replicas
W = A write quorum of size W
R = A read quorum of size R
-
Quorum means W pr R operation must receive at least W/R acknowledgement before the operation is considered successful.
-
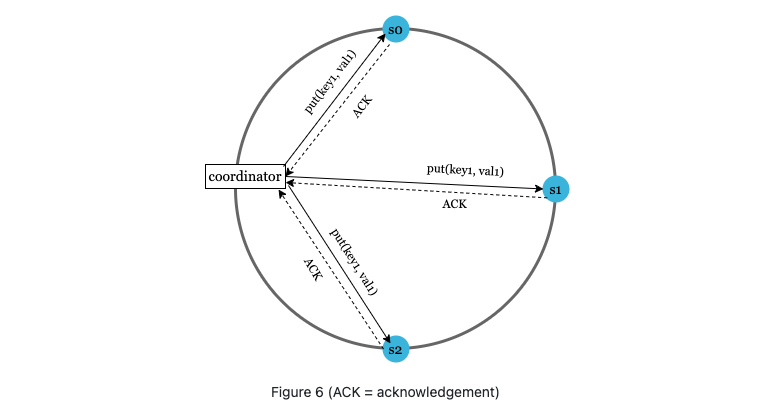
A coordinator acts as a proxy between clients and servers.
-
The configuration of W, R and N is a typical tradeoff between latency and consistency.
- If W = 1 or R = 1, an operation is returned quickly because a coordinator only needs to wait for a response from any of the replicas.
- If W or R > 1, the system offers better consistency; however, the query will be slower because the coordinator must wait for the response from the slowest replica.
- If W + R > N, strong consistency is guaranteed because there must be at least one overlapping node that has the latest data to ensure consistency.
-
How to configure N, W, and R to fit our use cases? Here are some of the possible setups:
- If R = 1 and W = N, the system is optimized for a fast read.
- If W = 1 and R = N, the system is optimized for fast write.
- If W + R > N, strong consistency is guaranteed (Usually N = 3, W = R = 2).
- If W + R <= N, strong consistency is not guaranteed.
Depending on the requirement, we can tune the values of W, R, N to achieve the desired level of consistency.
Consistency models
- Strong consistency: any read returns the latest data. Not ideal for high availability.
- Weak consistency: subsequent read operations may not see the most updated value.
- Eventual consistency: special weak consistency. Given enough time, all the updates are propagated and all replicas are consistent.
Inconsistency resolution: versioning
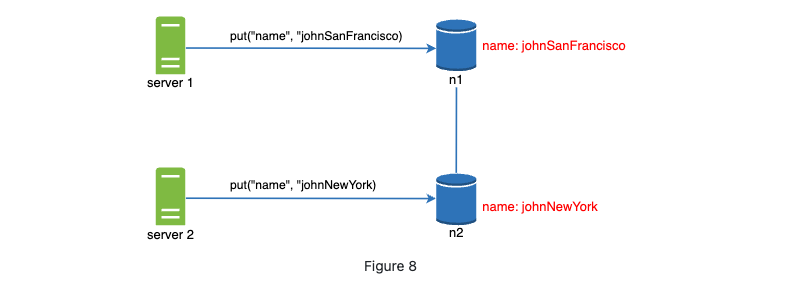
- How inconsistency happen: concurrent writes
-
How to resolve: versioning -> vector clock.
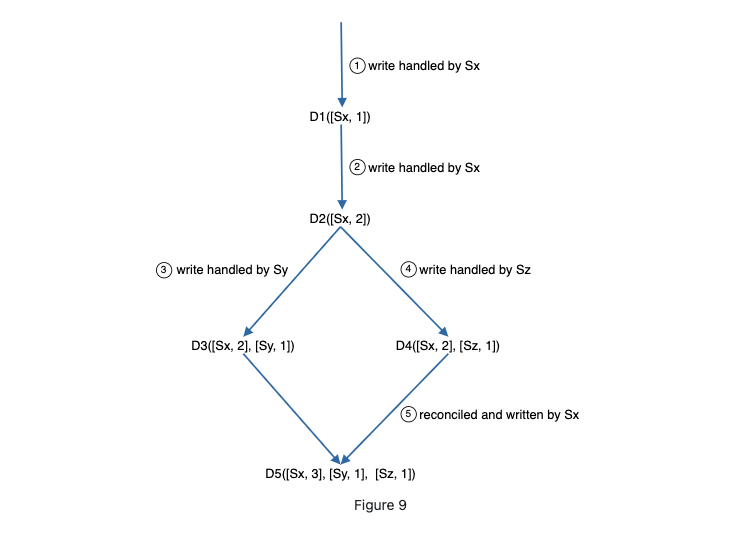
- A client writes a data item D1 to the system, and the write is handled by server Sx, which now has the vector clock D1[(Sx, 1)].
- Another client reads the latest D1, updates it to D2, and writes it back. D2 descends from D1 so it overwrites D1. Assume the write is handled by the same server Sx, which now has vector clock D2([Sx, 2]).
- Another client reads the latest D2, updates it to D3, and writes it back. Assume the write is handled by server Sy, which now has vector clock D3([Sx, 2], [Sy, 1])).
- Another client reads the latest D2, updates it to D4, and writes it back. Assume the write is handled by server Sz, which now has D4([Sx, 2], [Sz, 1])).
- When another client reads D3 and D4, it discovers a conflict, which is caused by data item D2 being modified by both Sy and Sz. The conflict is resolved by the client and updated data is sent to the server. Assume the write is handled by Sx, which now has D5([Sx, 3], [Sy, 1], [Sz, 1]). We will explain how to detect conflict shortly.
-
Downside of this method:
- Add complexity:it needs to implement conflict resolution logic.
- Grows rapidly(but this is ok in real implementation: DynamoDB)
Handling failures
Failure detection
-
it's not enough when one server says another is down.
-
We may use all to all multicasting
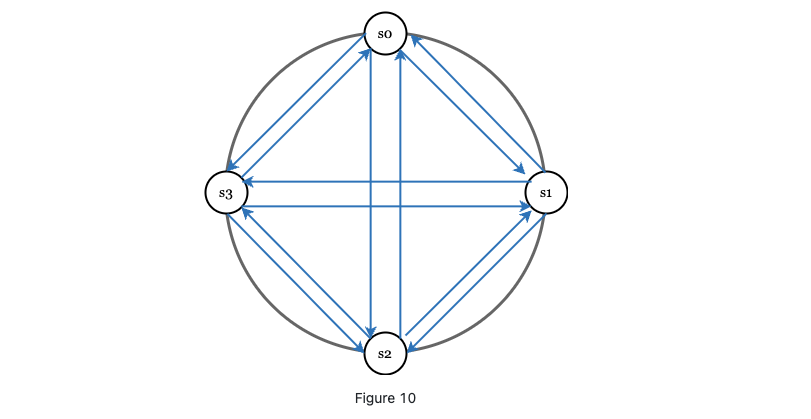
- straightforward but not efficient if there are many servers.
-
Gossip protocol.
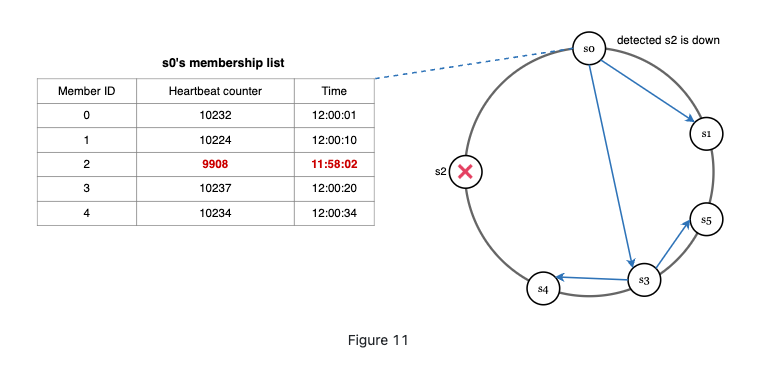
- Each node maintains a node membership list, which contains member IDs and heartbeat counters.
- Each node periodically increments its heartbeat counter.
- Each node periodically sends heartbeats to a set of random nodes, which in turn propagate to another set of nodes.
- Once nodes receive heartbeats, membership list is updated to the latest info.
Failure handling
Temporary down
-
availability: sloppy quorum. We accept write even one of the nodes if not the original quorum.(this is why called sloppy)
-
If a server s2 is down, s3 can be there for a while until s2 is back;
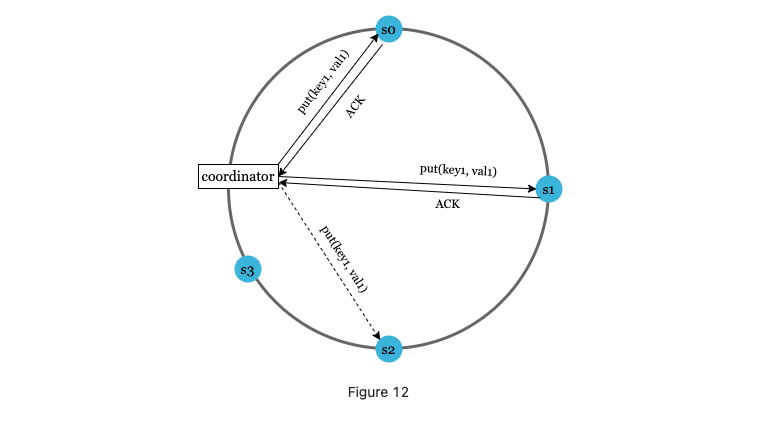
Permanent down
-
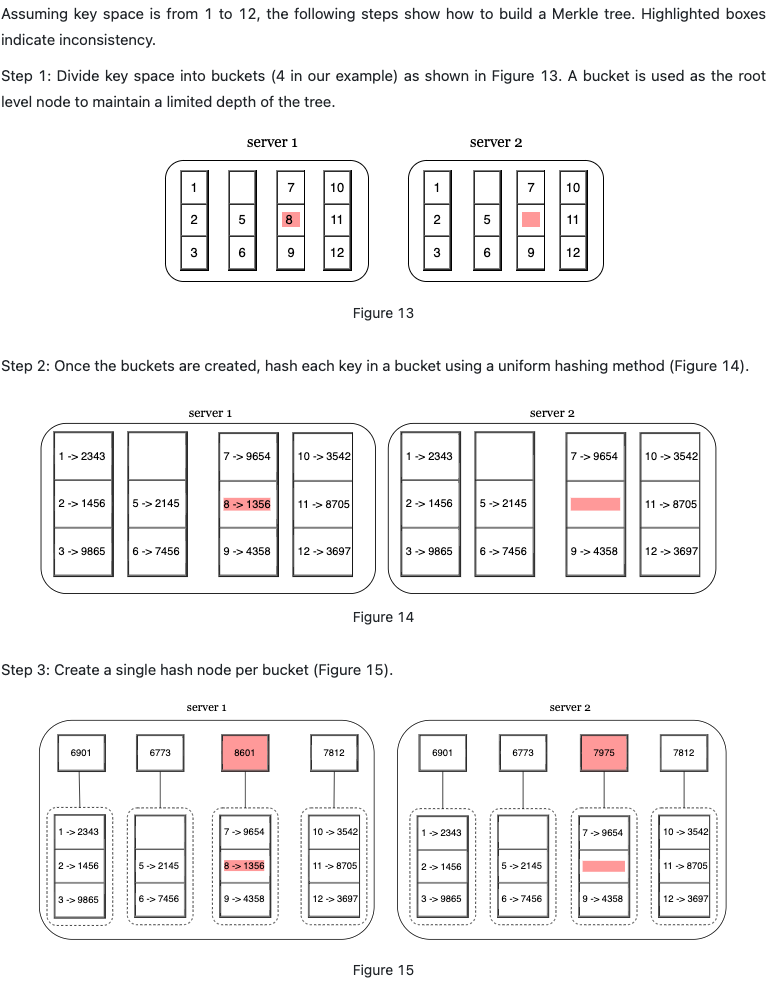
Hinted handoff: comparing each piece of data on replicas and updating each replica to the newest version. A Merkle tree is used for inconsistency detection and minimizing the amount of data transferred.
Transfer data back to the recovered node
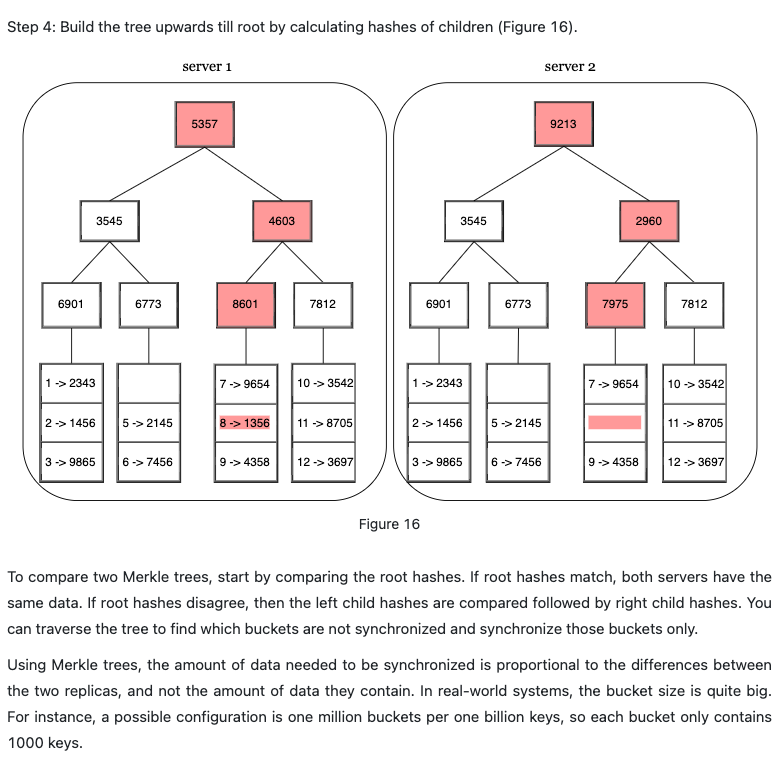
Data center outrage
Multi data center replication
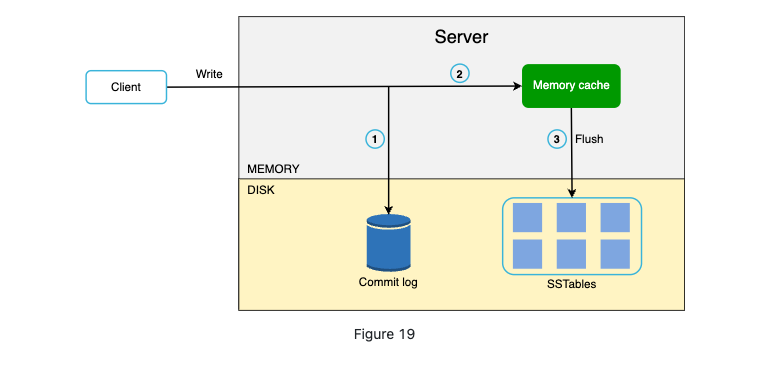
Write Path
- The write request in persisted on a commit log file;
- Data saved in memory cache
- When the cache is full, data is flushed to SSTable on disk
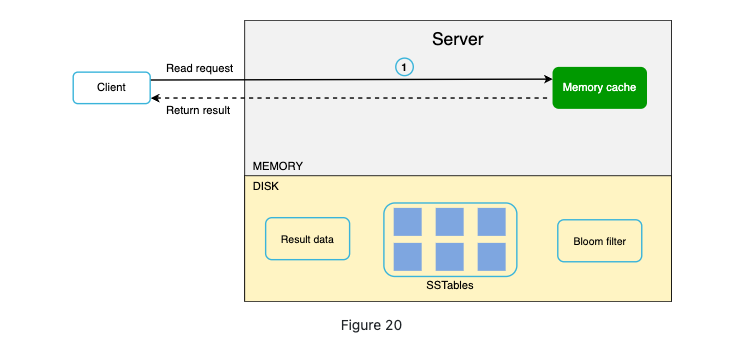
Read Path
-
If memory cache has the data, the data would be returned.
-
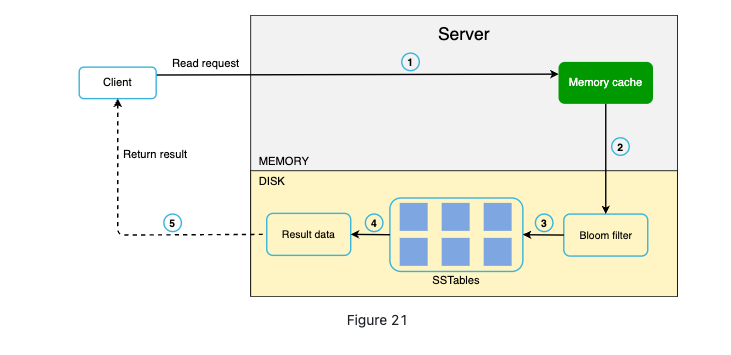
If the data is not in cache, we it will be retrieved from disk. Bloom filter is an efficient way to find which SSTable the key is in.
-
Sorted string table: SSTable, good for fast query and range query;
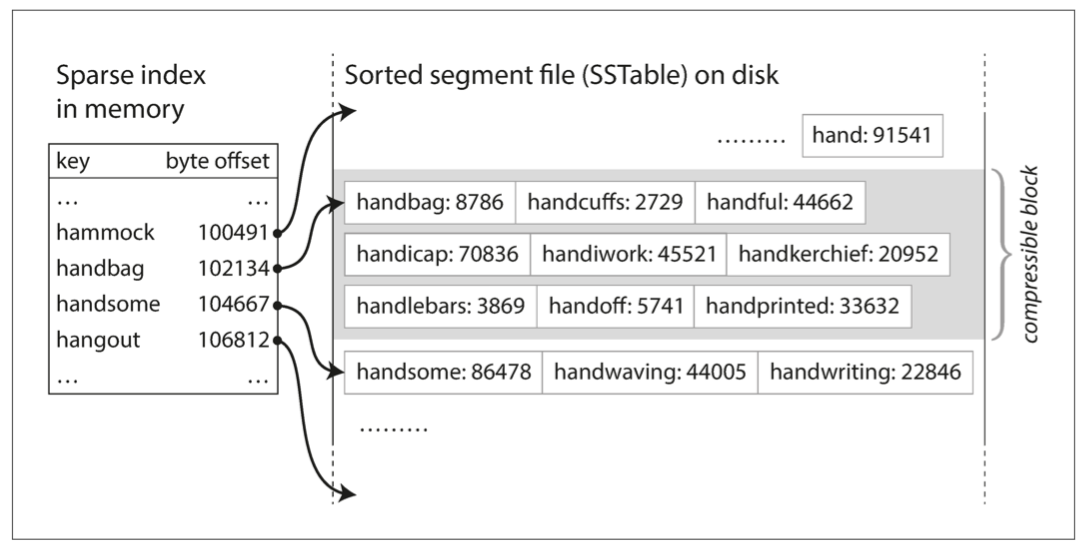
-
Why Bloom filter: due to the SSTable. If you need to read something, you need go to the memory first, and then disk where check from newest to oldest. It can tells you if a key is not here and saves time.
-
SSTable pros: (compared with B-tree):
- Better Write amplification
- Less space needed because of compression
-
Cons:
- Compression may effect write and read
- Write is too fast and compression is slower, disk become full very soon.
-
Architecture
You must wonder why I put the high level design after the component design.
If you check the previous article and notes, you will find you can't do high level design first cause you need to specify each component requirements thus combine to an system here.
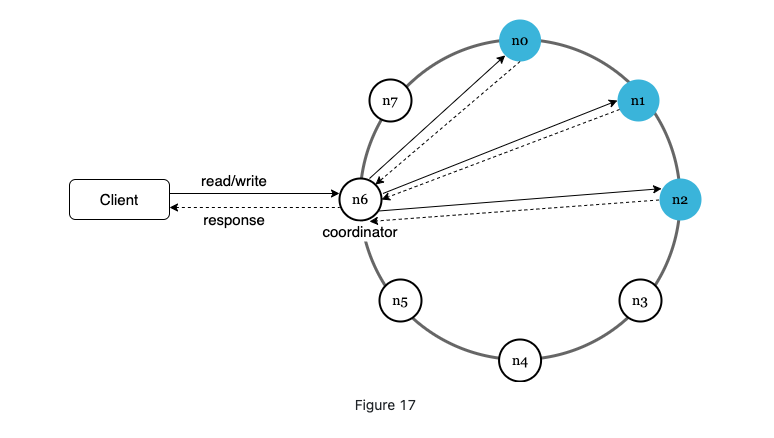
Main features
- Clients communicate withe the storage through simple APIs: get and put;
- A coordinator that acts as a proxy between client and k-v store;
- Nodes are distributed on a ring using consistent hashing;
- Decentralized so adding and removing can be automatic;
- Data is replicated at multiple nodes;
- No single point failure since all the nodes share same responsibility
each node performs many tasks:
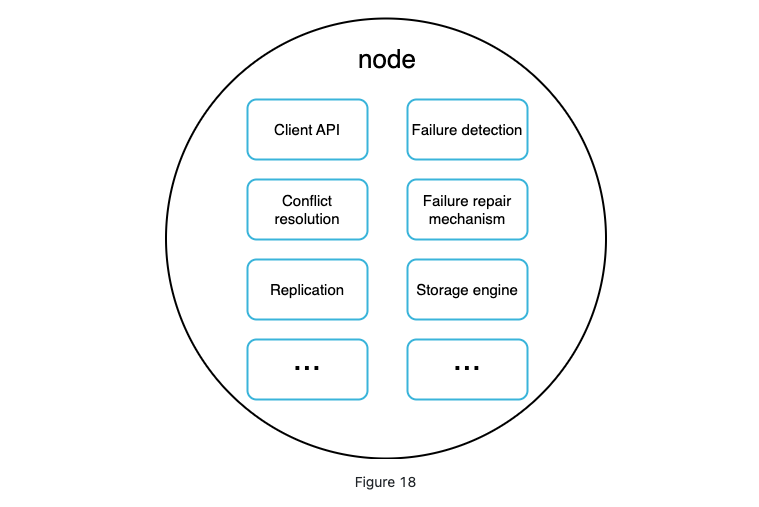
Wrap up
| Goal/Problems | Technique |
|---|---|
| Store big data | Use consistent hashing to spread load across servers |
| High availability reads | Data replication, multi-datacenter setup |
| High availability writes | Versioning and conflict resolution with vector clocks |
| Dataset partition | Consistent hashing |
| Incremental scalability | Consistent hashing(add or remove server would affect less) |
| Heterogeneity | Consistent hashing(do not understand to much) |
| Tunable consistency | Quorum consensus |
| Handling temporary failures | sloppy quorum and hinted handoff |
| Handling permanent failures | Merkle tree |
| Handling data center outage | Cross-datacenter replication |
Reference
[1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/
[2] memcached: https://memcached.org/
[3] Redis: https://redis.io/
[4] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[5] Cassandra: https://cassandra.apache.org/
[6] Bigtable: A Distributed Storage System for Structured Data: https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
[7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree
[8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/
[9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
[10] Bloom filter https://en.wikipedia.org/wiki/Bloom_filter