Firstly, you may come up with the traditional database auto increment id generator, however, there are two challenges, one is single server is no big enough, the other one is generating unique ids across database in a distributed system with minimal delay is challenging.
Step1 Understand the requirement and establish design scope
- What is the characteristics of the IDs? - IDs must be unique and sortable.
- For each new record, does ID increment by 1? - The ID increase by time nut not necessary by 1.
- Do IDs only contains number values? - Yes.
- What is the length requirement? - 64-bit
- What's the scale of the system? The system should be able to generate 10000 IDs per second.
Step2 Propose high level design and get buy in
There are many options could be considered:
- Multi-master replication
- UUID - Universally unique identifier
- Ticket server
- Twitter snowflake approach
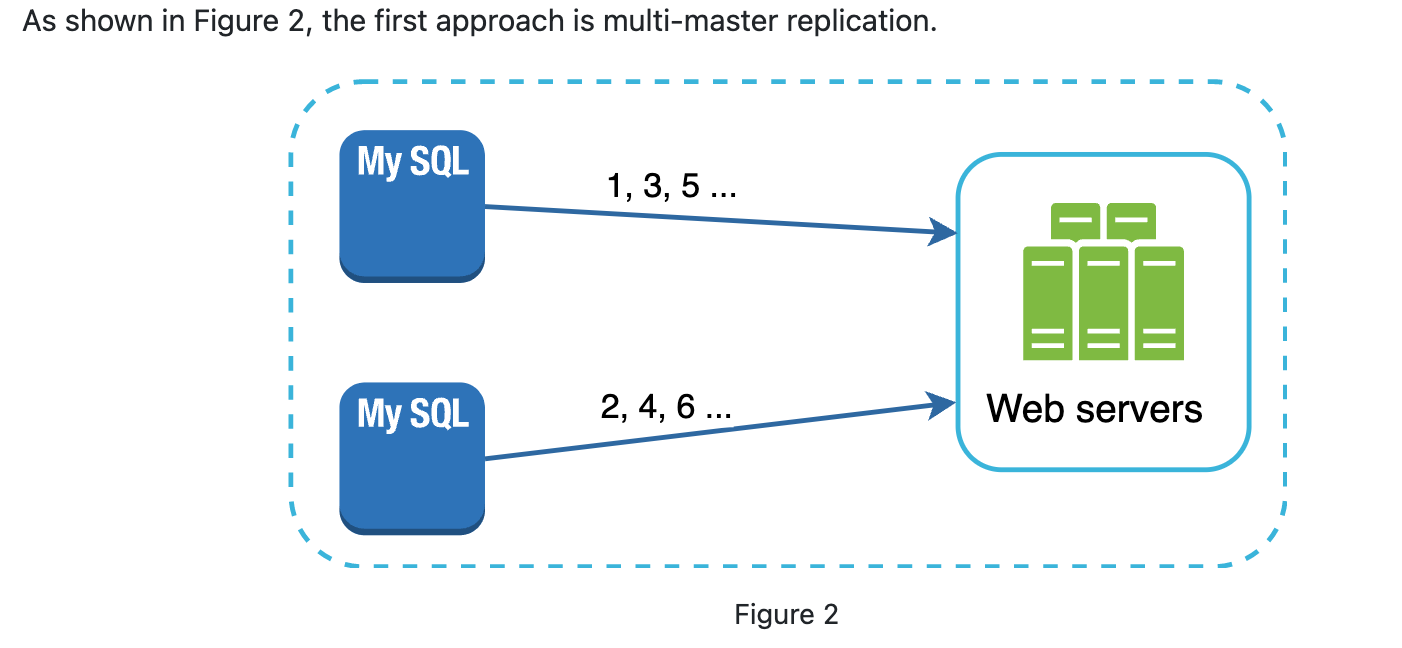
Multi-master replication
- It utilizes the database auto-increment, but instead increment 1, it increases k where k is the number of database.
- Pros: This solves some scale problems because IDs can scale with the increase of number of database server.
- Cons:
- Cannot scale well in multi-datacenter(same issue with single server. Sync up number with minimal delay)
- Do not scale well when adding or removing database server(k changes and how to handle the incrementer in all other database servers?)
- IDs do not go up with time across multiple servers.
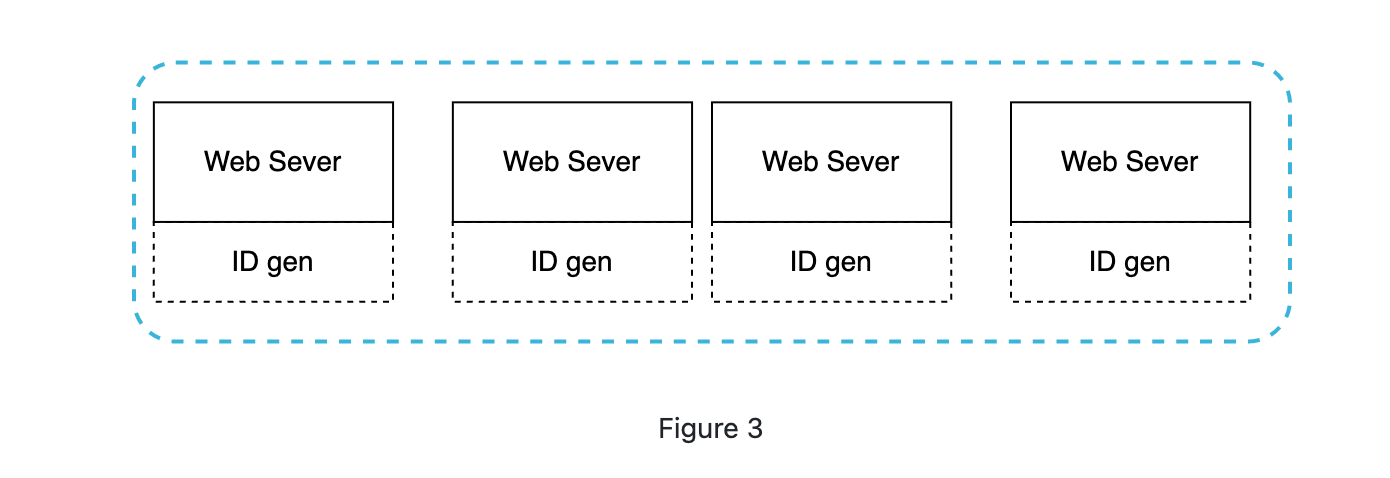
UUID
-
UUID is a 128-bit number used to identify information in computer system. And it has a low probability of collision.
-
Here is an example of UUID: 09c93e62-50b4-468d-bf8a-c07e1040bfb2
-
The system with UUID would look like:
-
Pros:
- Scale well because you do not need to coordinate across servers. Each server will be responsible for ID generation
-
Cons:
- Not numeric IDs
- Not increased with time and sortable.
- Not 64 bit.
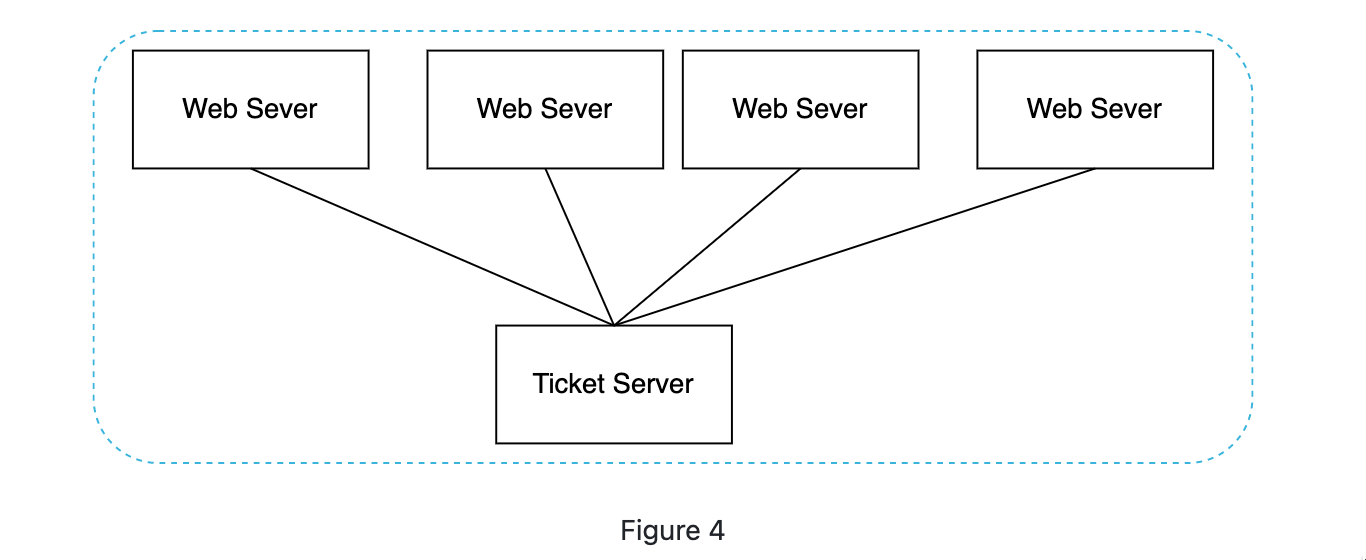
Ticket Master
-
It uses a single database server(centralized) to do the ID incrementation
-
Pros:
- Easy to scale and do not have sync issue.(actually works well on small-medium size applications.)
- Numeric IDs.
-
Cons:
- Not good when single point failure, If Ticket server is down. (And if you want to mitigate this, you introduce multi-ticket server, this will cause another synchronization problem between them)
- Not scale well when scale up since too many web server is communicating with ticket server and put pressure on it.
Twitter snowflake approach
-
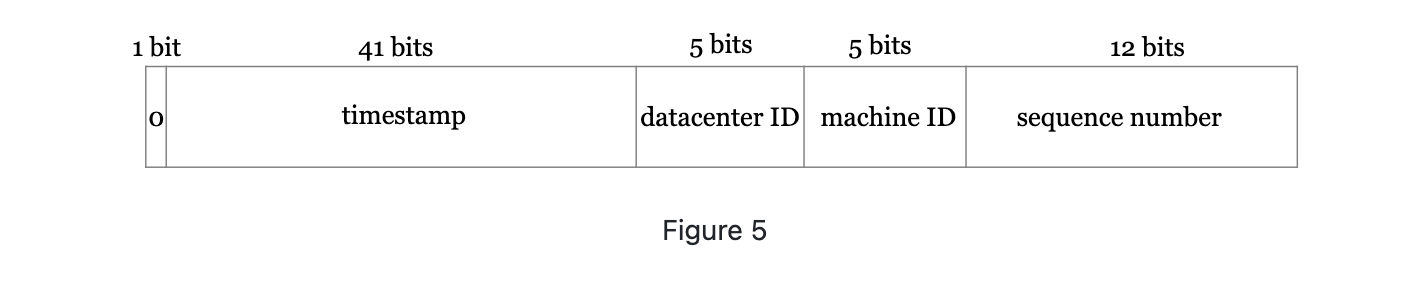
Instead of generating an ID directly, we divide an ID into different sections. Figure 5 shows the layout of a 64-bit ID.
-
Each section:
- Sign bit. 1 bit. It will always be 0. This is reserved for future use. Can potentially distinguish signed and unsigned numbers.
- Timestamp. 41 bits. Milliseconds since epoch or custom epoch.
- Datacenter ID: 5 bits. Which gives us 2^5=32 data centers.
- Machine ID:5 bits. Which gives us 2^5=32 machines per datacenter.
- Sequence number: 12 bits. For every ID generated, the sequence number incremented by 1. This number is set to 0 every millisecond.
Step3 Design Deep Dive
-
Datacenter IDs and machines IDs tends to be fixed at first, every change of them requires carefully review.
-
Timestamp and sequence number is generated when app is running.
-
ID is sortable by time as timestamp goes up.

-
This timestamp gives us 2^41 ~= 69 years. After 69 years, we need a new epoch time or adopt other techniques.
- Sequence number has 12 bits which gives up 2 ^ 12=4096, so in theory, each machine can be allow to generate 4096 IDs per millisecond.
Step4 Wrap up
We discuss several option for unique ID generation.
There are some extra questions if time allowed:
-
Clock synchronization. In our design, we assume all servers have the same clock. When running in multiple cores this might not be true.
- To mitigate this issue, Network Time protocol is the most popular solution.
-
Section length tuning.
- Highly availability. The ID generation is mission-critical so it should be highly available.