Protect Clients from servers
Synchronous and asynchronous clients
Admission control system
Blocking I/O and non-blocking I/O clients
-
Admission control system : system with load shedding and rate limiting -> back exception -> HTTP 429 and 503
-
Client should avoid immediate retry -> retrying with exponential backoff and jitters is better
- Delays give servers to scale out
- Jitters distributes request more evenly
-
What if servers are not elastic and the problem is not transient ?
-
Blocking / non-blocking client (sync and async )
- Blocking:
- if the thread want to send requests to server, it starts new connection or reuse existing connection form the pool of persistent connections and execute I/O operations ->
- thread is blocked waiting for I/O to complete
- New thread for new connection
- Non-blocking
- Application threads don't use connection directly, use a request queue
- A single IO thread dequeue thread from the queue and establish a connection or obtain from the pool.
- Single thread for multiple requests
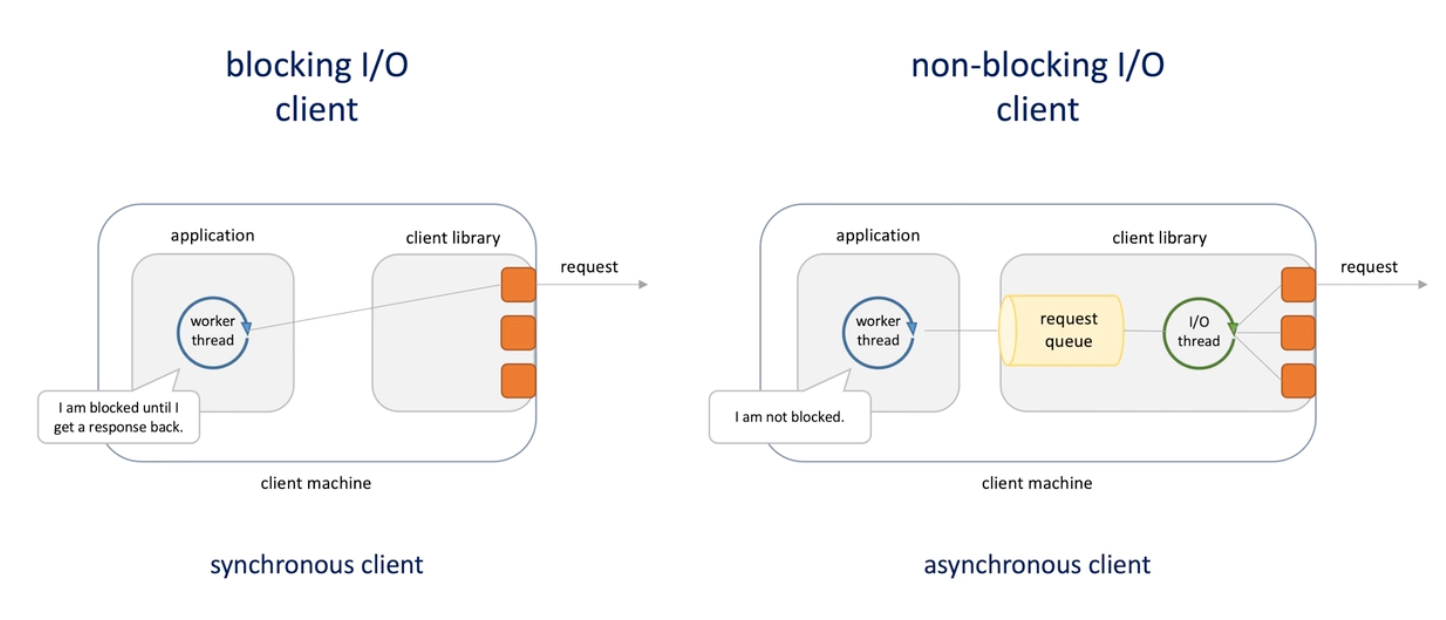
- Blocking:
-
Pros
- Sync : simplicity , easier to write test and debug client-side application; Latencies are lower in case os smaller number of concurrent request
- Async : higher thought in case of large number of concurrent request-> more efficient in handling traffic spikes ; More resilient to server outrages and degraded server performances -> client piling up request in the queue is much cheaper than piling up threads
-
Different : how they handle concurrent thread
-
How many concurrent requests a client can generate ? An example
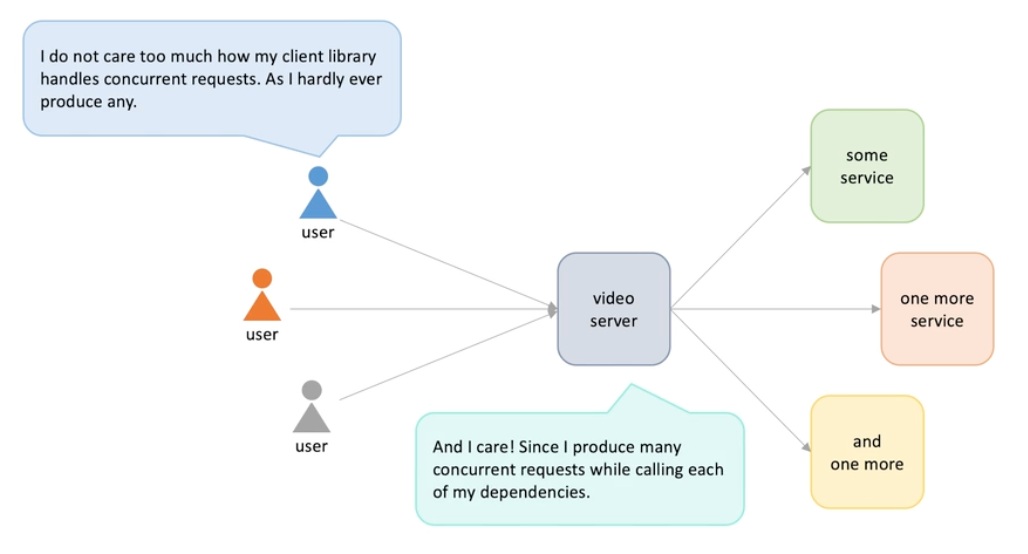
-
Nowadays , industry are shifting to non-blocking -> blocking server -> blocking clients
-
No matte which server model can be suffered from this issue when the inching request exceeds the outgoing traffic and the processing request is accumulating -> exhausting the resources
-
One way to resolve is to stop send request for a while , to allow server to process -> circuit breaker pattern
Circuit breaker
Circuit breaker finite-state machine
Important considerations about the circuit breaker pattern
-
When the client received failed response from server, it counts them and when reach a limit it stops calling the server for a while;
-
There are some open source libs for using -> Resilience4j or Polly -> you specify thress things
- Exception to monitor
- Count of exception(threshold)
- Time to stop sending request (timespan)
-
A state machine that explain the state transition
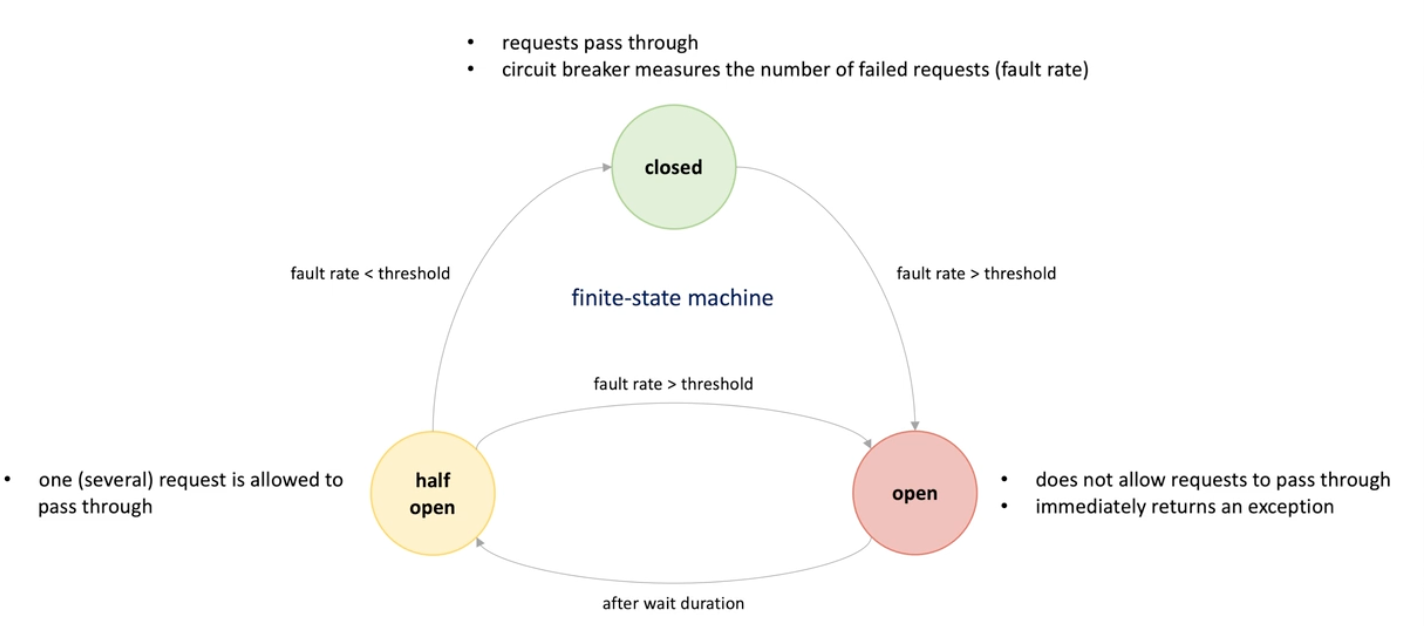
If from in half open, there are some other exception, it remains half open
-
Things to consider
- Timer or health checks to determine when to transition to half open state (an health check endpoint)
- Circuit breaker instance has to be thread safe -> instances are shard -> use lock
- With rejected request -> buffer, failover, fallback, back pressure , cancel ..
Fail-fast design principle
Problems with slow service (chain reactions cascading failures) and ways to solve them
-
Bad service
- Doesn't work (low availability)
- Doesn't know how to stand with faults (not fault tolerant)
- Doesn't know how to quickly recover from failures(not resilient)
- Doesn't always return accurate results(not reliable)
- Lose data from time to time(not durable)
- Doesn't know how to scale quickly(not scalable)
- Returns unpredictable results(supports a weak consistency model)
- Hard to maintain (doesn't follow operational excellence guidelines)
- Poorly tested (low unit/functional/integration/performance test coverage)
- Not secure(violates CIA triad rules)
- ...
-
It's better to fail fast than fail slow. Fail immediately and visibly -> distributed system and OOD
-
e.g.
-
Object initialization: we should throw exception if we can't initiate completely
java public class SomeClass { private final String username; // immutable object public SomeClass(@NotNull String userName) { this.username = userName; } .... }
-
Precondition: Implementing precondition for input parameters in a function:
java public static double sqrt(double value) { Preconditions.checkArgument(value >= 0.0); ... }
-
Configuration validation: set configuration file and read properties from it. Fail fast and don't rely on default values
java public int maxQueueSize() { String peroperty = Config.getProperty("maxQueueSize"); if (property == null) { throw new IllegalStateException("..."); } ... }
-
Request validation : return exception back to client and don't try to set value and continue handling
java private void validateRequestParameter(String param) { if (param == null) { throw new IllegalArgumentException("..."); } ... }
-
-
Slow service kill themselves along with their servers, e.g.
-
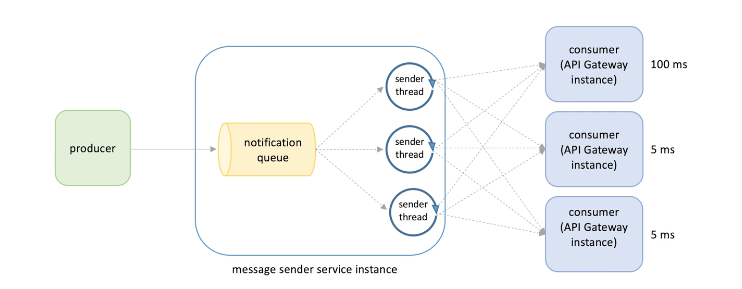
-
When a single consumer start to slow down, all the sender threads will be impacted , then the notifications queue will be consumed slower and thus fill up message, and producers will be slow and will not continue push or pulled(back pressure) messages by the queue.
-
Cascading failure: one component causes the whole system component to fail (different part in a system)
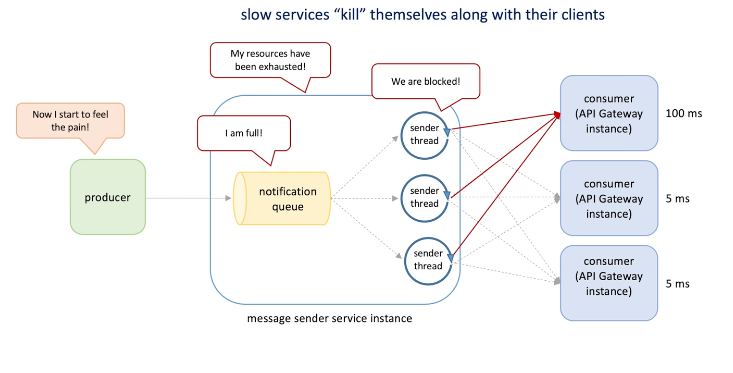
-
Chain reaction Or Server identified the slow consumer and no more send messages to it(like using circuit breakers) -> this will cause more load on the other consumers and slow down them (system type of components)
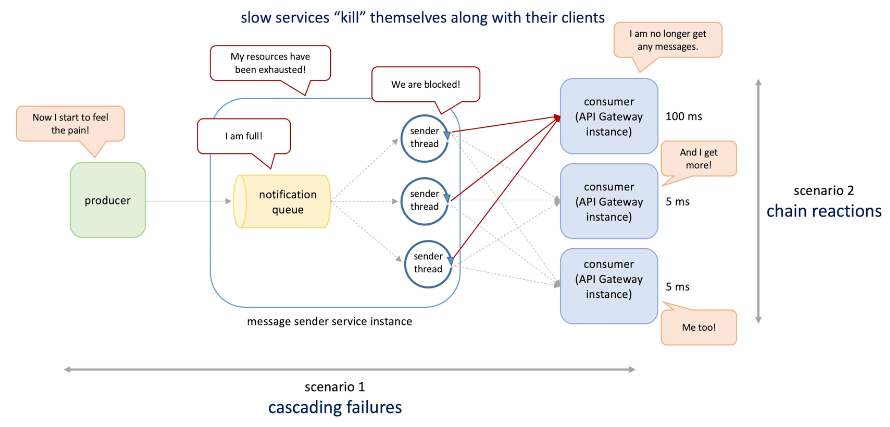
-
For cascade failures, client should protect themselves .-> convert slow queries to fast queries by identify or isolate bad dependencies.
- Timeouts
- Circular breaker
- Health check
- Bulkhead
- Chain reactions : server need to protect themselves
- Load shedding
- Auto scaling (quickly add redundant capacity)
- Monitoring (quickly identify and replace failed servers)
- Chaos engineering
- Bulkhead
-
-
Bulkhead
How to implement
-
Partition resources into groups of limited size and isolated groups , to isolate the impacted of failed parts from others health parts .
-
The example in the above can be -> instead of having a single thread pool -> we have several thread pool for each consumer, each pool has a limited number of threads . One consumer and pool slow down will not impact others .
-
More examples -> this pattern is used in a service that has many dependencies
- We have a order service, and depend by the inventory service and payment service
- We can do three option
- Limit the number of connection to each dependency - easy to implement but we need to trust client won't mess the service
- Set up separate connection pool for each dependency
- Specify thee number of each pool
- Limit the number of concurrent request for each dependency by counting requests
- Count how many simultaneous request are made to each dependency ;
- When reach limit, all requests to that dependency are immediately rejected.
- Limit the number concurrent request by create per-dependency thread pools - highest isolation but expensive and complex
- Create a separate fixed size thread pool for each dependency
- Limit the number of connection to each dependency - easy to implement but we need to trust client won't mess the service
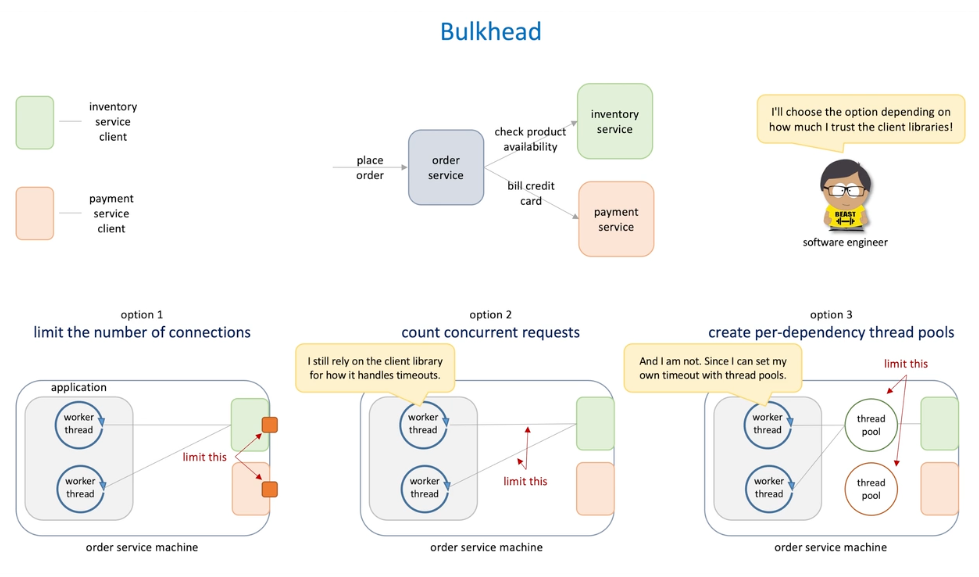
-
Find group limits can be hard -> and theses limits needs to be revised from time to time -> load test
Shuffle sharding
How to implement
- Bad client (make server suffer)
- Create a flood of request (a way more than a typical client )
- Send expensive request (CPU intensive , large damage, heavy response)
- Generate poisonous request (security bugs)
- Load shedding and rate limiting are not enough? The whole system can be organic each part should make effort
- We have 8 servers , divide into 4 groups and serve certain client , -> difference with bulkhead(availability) -> shuffle(scalability)
- Blast radius = number of clients / numbers f shards
- The shuffle is two clients in a group in a serve while they are not in a group in other serves -> this will allow lower impaction on the server -> for example, if 1 is down, 5 is also down in the above chart but when shuffle, when one is down , 7 and 4 is impacted in that server but 4 and 7 can be served in the server 6 and server 8 continually
-
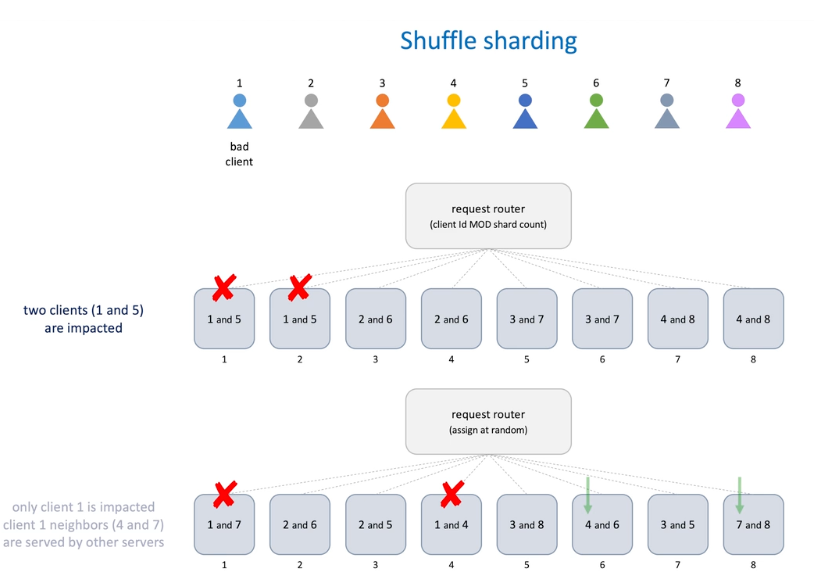
-
Note
- No possibility to isolate everyone to every one -> but chances decrease with less serve impacted.
- Clients need to know how to handle server failures-> timeout and retry failed requests
- Shuffle sharding needs a intelligence rounding component
- Assign clients to shuffle sharding in stateful and stateless manner
- Stateless : when assigning new client, we don't see current assignment
- Stateful: has a storage on the shard and client, choose a shard that minimize the overlap