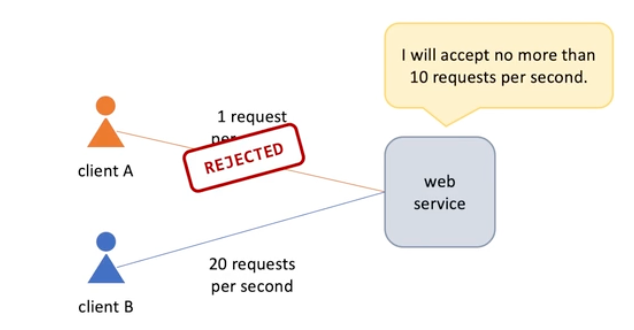
Protect Servers from clients
System Overload
Why it's important to protect a system from overload
Auto scaling
Scaling policies(metric-based, schedule-based, predictive)
-
Overload happens when existing computational resources are not enough to process all the loads;
-
-> add more servers manually?
- Do it often is operationally expensive
- Infrequent changes increase the likelihood of overload
- Leave it excess the needs is is waste of cost
-
We should find ways to do(add and remove) it automatically -> auto scaling
- Improves availability -> system add or remove machines on the unpredictable traffic spikes
- Reduce cost
- Improve performance on mod requests
-
Types /polices
- Metric based : perforce metrics are used to make decisions on whether to scale or not -> scale out when average CPU utilizations is over 80% and scale in when CPU utilization is less than 40%
- CPU utilization
- Memory utilization
- Disk unitilization
- Request count
- Active threads count
- Schedule - based : define a schedule for the autoscaling system to follow: scale out business hour and scale in for non-business hours(nights and weekends)
- Predictive : machine learning models are used to used to predict expected traffic -> scale out when average CPU is expected to increate and scale in for when average CPU is expected to decrease -> use historical data to predict
- Can be used together
- Metric based : perforce metrics are used to make decisions on whether to scale or not -> scale out when average CPU utilizations is over 80% and scale in when CPU utilization is less than 40%
-
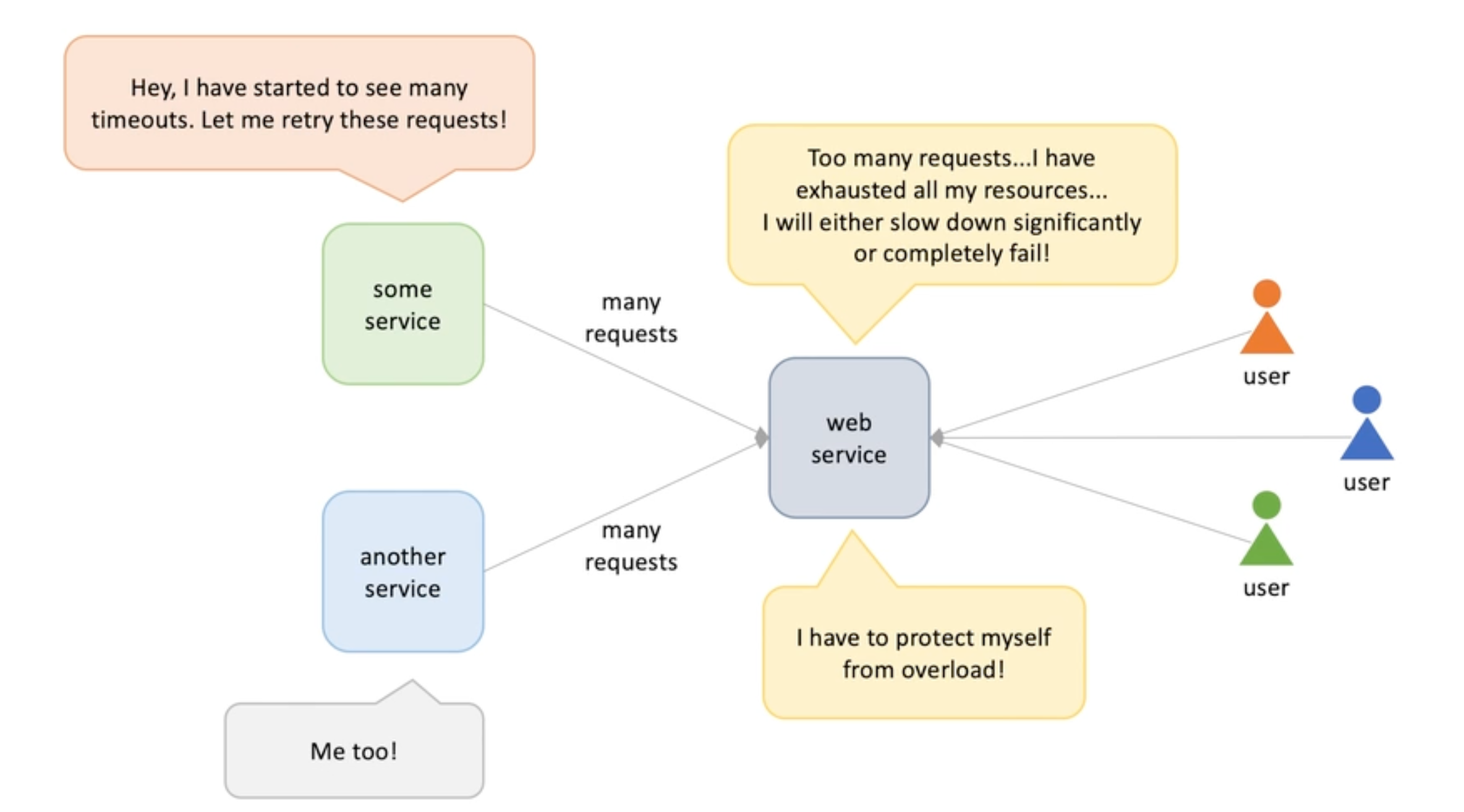
Apply to messaging system
-
Monitor depth of queue, when exceeds limit, we add consumers; when the queue shrinks, we reduce the consumer instances ;
-
This only works for competing consumers model RabbitMQ &SQS
-
Kafka and Kenises has a different way of implement auto scaling -> they are consumer offset -> they scale out by adding partitions
-
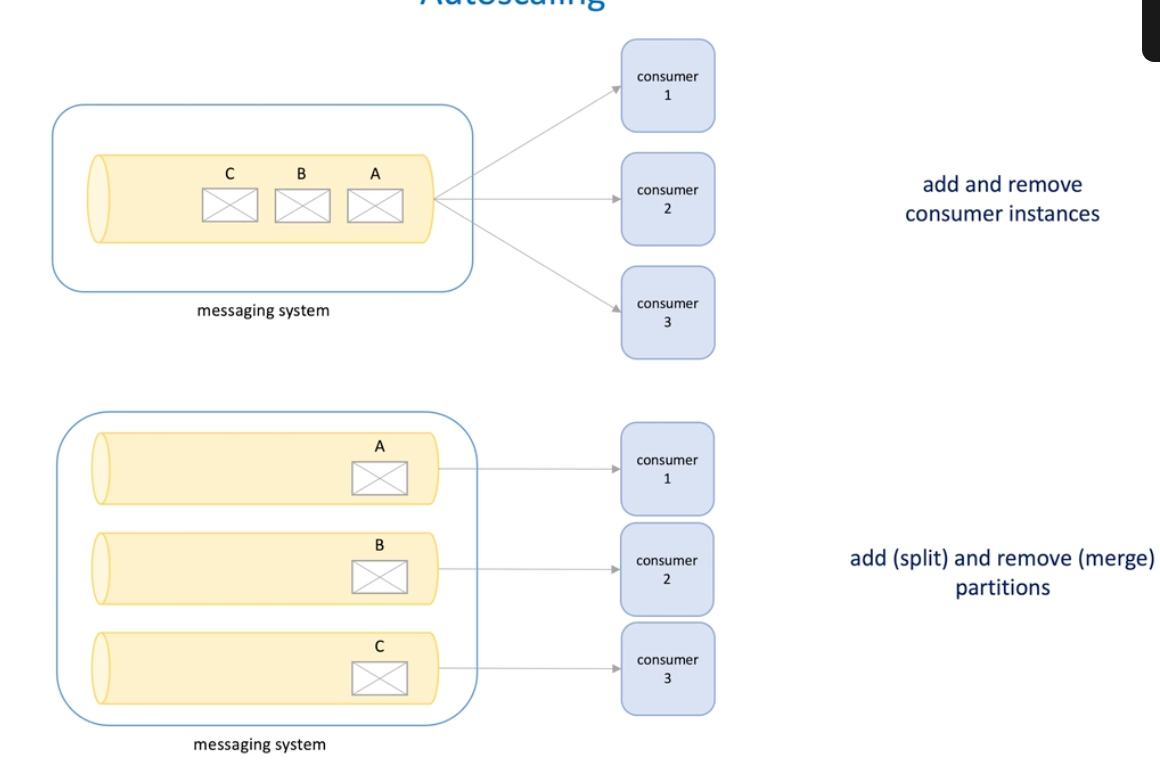
Autoscaling system design
How to deign an autoscaling system
- We have a web service and want to scale out and in based on it's metrics ;
- So we add a monitoring system to the service ;
- On the other hand, we need to configure rules that apply to the service autoscaling -> configuration service
- For the configuration service , we do need a storage ;
- For such rules , we need a coordinator/rule checker to fetch rules, and also fetch the metrics periodically to check if we need to do the scaling
- Here rules may be in a large number and rules can be split into chunks;
- One way to implement this is to elect a leader acting as a coordinator for how to partition rules and how to assign rules partition to workers for processing
- Another way is we split rules into fixed number partition; assign 10 workers to assign one partition to each worker, since there are distributed locks , each machine will get a different partition;
- If so, we can have a message(task) queue and send messages for scaling ;
- Here for the queue message consuming we could have a complete consumer model to increase the performance;
- The we need a consumer , called provisioning service, when the message was consumed, the new machines are added or machines are removed from a particular cluster.
- Provisioning service to find web service to scale -> service discovery problem
Load Shedding
How to implement
Important considerations
- Auto scaling relies on servers themselves effort, but sometimes this is not enough, the auto scaling system cannot scale in time, we need some protections as well.
- Monitoring system needs time to collection metric data
- Provisioning new machines takes time;
- Deploying services and bootstrapping on new machines takes time;
- Load shedding: drop incoming request when some metric reach a threshold. (Until more rooms is available)
- How to determine the threshold (CPU, storage ....) -> running load testing
- How to implementing:
- Thread per connection
- Limit the number of connections -> limit the number of clients
- Limit the number of request -> limit the number of processing threads
- Monitoring system performance and start drop request when reach a limit
- Thread per request with non-blocking io
- Limit the number of connections -> limit the number of clients
- Limit the number of request -> limit the number of processing threads
- Monitoring system performance and start drop request when reach a limit
- Event loop
- Limit the number of connections -> limit the number of clients
- Limit the number of request -> limit the size of processing queue
- Monitoring system performance and start drop request when reach a limit
- Thread per connection
- Tuning the thread pool size is hard, too big will put pressure on the server and too small may cause waste of CPU/memory resources -> load testing
- e.g. messaging system -> RabbitMQ-> consumer prefetch -> help avoid overloading consumer with too many messages
- Consumer side configure a prefetch buffer defines max messages consumer can consume,
- When the buffer is full, meaning the consumer is still processing the messages;
- The broker doesn't push more messages to the consumer
- When the buffer has space, the broker continue push messages
- Similar to TCP control flow
- TCP sender send packages to receiver and waits for ack;
- Ack contains how many buffers receiver is willing to accepts;
- Difference from back pressure : -> clients are involved this precedure
- This mechanism doesn't response the overloading or drop message to the broker -> this is the consumers business and is called load shedding (self defends)
- If consumer response to the broker on overload -> rejection -> back pressure
- Considerations
- Request priority -> healthy request of LB, people over robots
- Request cost : fetch data in the cache vs heave calculations
- Request duration: LIFO-> if the service is busy with processing request, it's better to focus on processing the most recent requests(e.g. A use tried to waiting for the response and refreshed the page in the browser), what's more, the old request may have timed out. -> but how the server know a request is timeout out? > time out hint (with request)
- Using with Autoscaling , avoid load shedding block autoscaling. -> when having both, configure a lower threshold for load auto scaling.
Rate limiting
How to use knowledge grained in the course for solving the problem of rate limiting (step by step)
- Unfair -> noisy neighbors
- How to solve ? -> we need to limit the total number of request coming to the system ; on the other hand we need to ensure each client will not impacted by others (they share total resources)
- Share resources evenly -> split limit to each client -> quota
- Rate limiting(throttling): controls the rate of request send or received on the network. (On per client based )
- How long is the interval / how to account for heterogeneity requests
- Assumption : 1s (configurable) and all request are equals
- Start with single server :
- Where to store the counter : memory or disks -> in-mem cache since the data is short-lived -> unique clientID is the key and request count is the value -> time also need to be stored in the key(let do this first)
- Two problems : concurrency and cache size
- Concurrency is a problem is we use a thread per request model and two different thread try to modify the same cache engine.-> lock or atomic values
- Too many keys -> LRU eviction or time-based expiration or both. -> active expiration is more effective
- Add another server:
- Split the quote and route the request by LB -> how to share the change in the cluster when machines added or removed in a timely manner
- Configuration tools to share and deploy to servers
- Database and pull data periodically
- Gossip protocol
- Issue :
- LB doesn't guarantee the uniform distribution for each client
- If quota is low, some servers will start throttling requests long before the quota is reached.
- LB balances connection and not requested , some persistent connections may be used to transfer more request than others
- LB doesn't guarantee the uniform distribution for each client
- Split the quote and route the request by LB -> how to share the change in the cluster when machines added or removed in a timely manner
- Servers share the number of request they received
- Gossiping
- Service registry or seed nodes advertised by DNS
- Use TCP and UDP
- This doesn't scale well -> communication increase with the server # of the cluster
- Use a shared cache , server report the count to the cache
- What client should do with the throttle request
- Retries
- Fallback
- Expotentional request with Jitter
- Batching