Fundamentals of reliable, scalable, and fast communication
Synchronous vs asynchronous communication
- Synchronous and asynchronous request-response models
- Asynchronous messaging
- For client communicate with server, we have two options
- The client send requests to server directly, or the client send requests to a messaging system
- Request-response model can be in synchronous and asynchronous manner.
- Sync : client waits for the response to come back;
- Async: client does not wait for the response to come back.
- Messaging : the client sent message to the messaging system , and later the messaging system send the message to the server .
- The job of client is done when it send message to the messaging system;
- Request - response
- Pro: easy to implement
- Cons:
- What should the client do when the server is not available?
- What should the client do with the failed requests?
- What should the client do when the server gets slower ?
- What should the server do when there is a spike from clients
- Messaging
- Pros :
- decouple for client and regarding to the cons in the previous section:
- Keep message and send them later
- Resent failed messages
- Add more servers to parallelize processing
- Server keeps draining messagings as its now pace
- Cons: system complexity and operational overhead(moniter, maintain... )
- Pros :
- It depends to choose among them
- The client wants to know the response of the call -> sync request - response;
- The client wants to know the response but don't want to wait - async request- response;
- If the client send requests in parallel , a request-response model may cause latency, a messaging system is more proper if the client doesn't care about when and who and how will process the messages , it only care about submitting messages to the system.
Asynchronous messaging patterns
- Messaging queue model
- Publish/subscribe model
- Completing consumer pattern
- Request/response messaging pattern
- Priority queue pattern
- Claim check pattern
-
Message queuing - only a single consumer gets the message ;
-
Publish / subscribe model : the same message is delivered to all consumers .
-
A example of these two patterns : The videos in the Youtube needs to be transcoding before it dispatch to the different type of client devices like phones, pads and PCs.
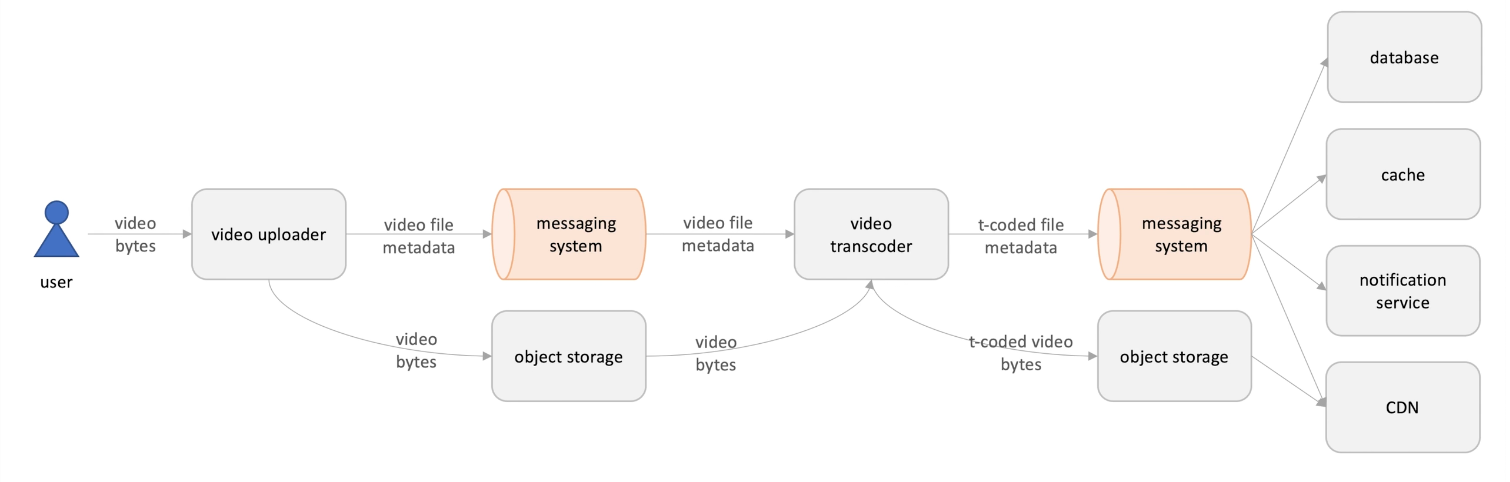
- Users upload videos , the video uploader store the video to a storage,
- then send the metadata of the videos and locations through the messaging system;
- The messaging system send the file metadata to the video transcoder ;
- The transcoder fetch the video bytes from storage and do the transcoding;
- Then store the transcoded files to the storage ;
- Send the metadata to the messaging system;
- The messaging system broadcast the messages to the consumers like :
- Cache to help reads
- Database: to persiste
- Notification service to notify subscriber the updates
- CDN: quick access contents
-
The previous part of this function ( upload and messaging system and transcoder) is a messaging queue model and the second part is a publish /subscribe model since there are multiple consumers .
-
The infrastructure can be extend to other models for different scenario;
-
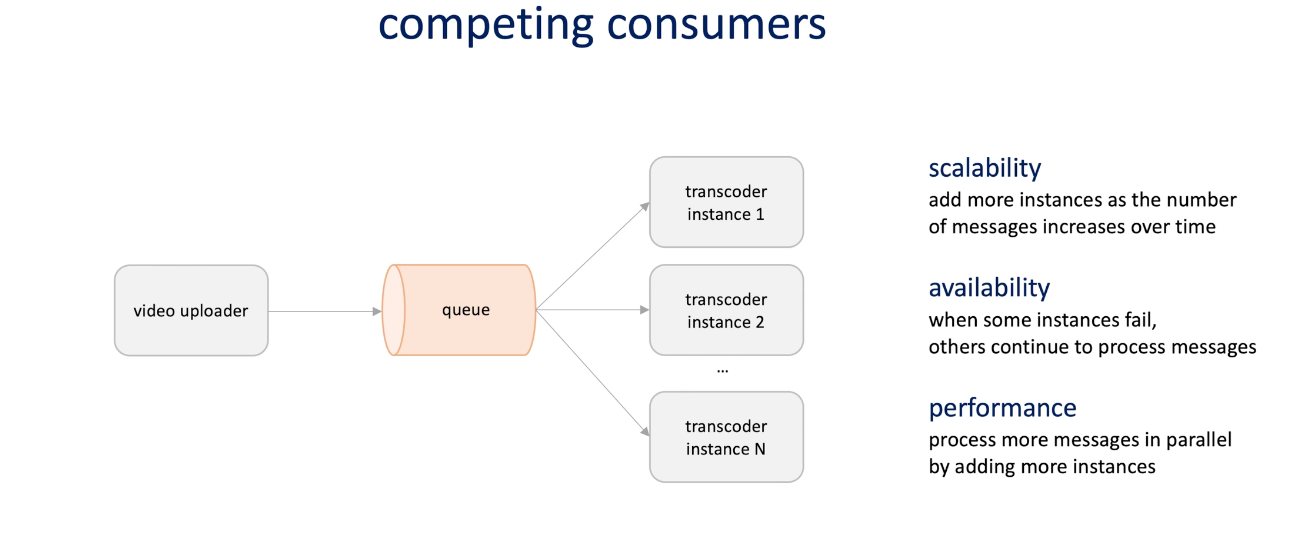
Competing consumers : different transcoder instance can consume messages;
-
This increase the scalability as more instances with the increasing messages number; availability , when some instance fail, others continue to process messages; performance more messages are processed in parallel when adding more instances;
-
Request / response messaging : when the video uploader (sender) wants to get a repose back from the consumer to confirm the job status
-
To implement this, we need to introduce another queue called callback queue. The consumer send the response to the call back queue with info(request id to identify and response message); then the message was send back to the uploader.
-
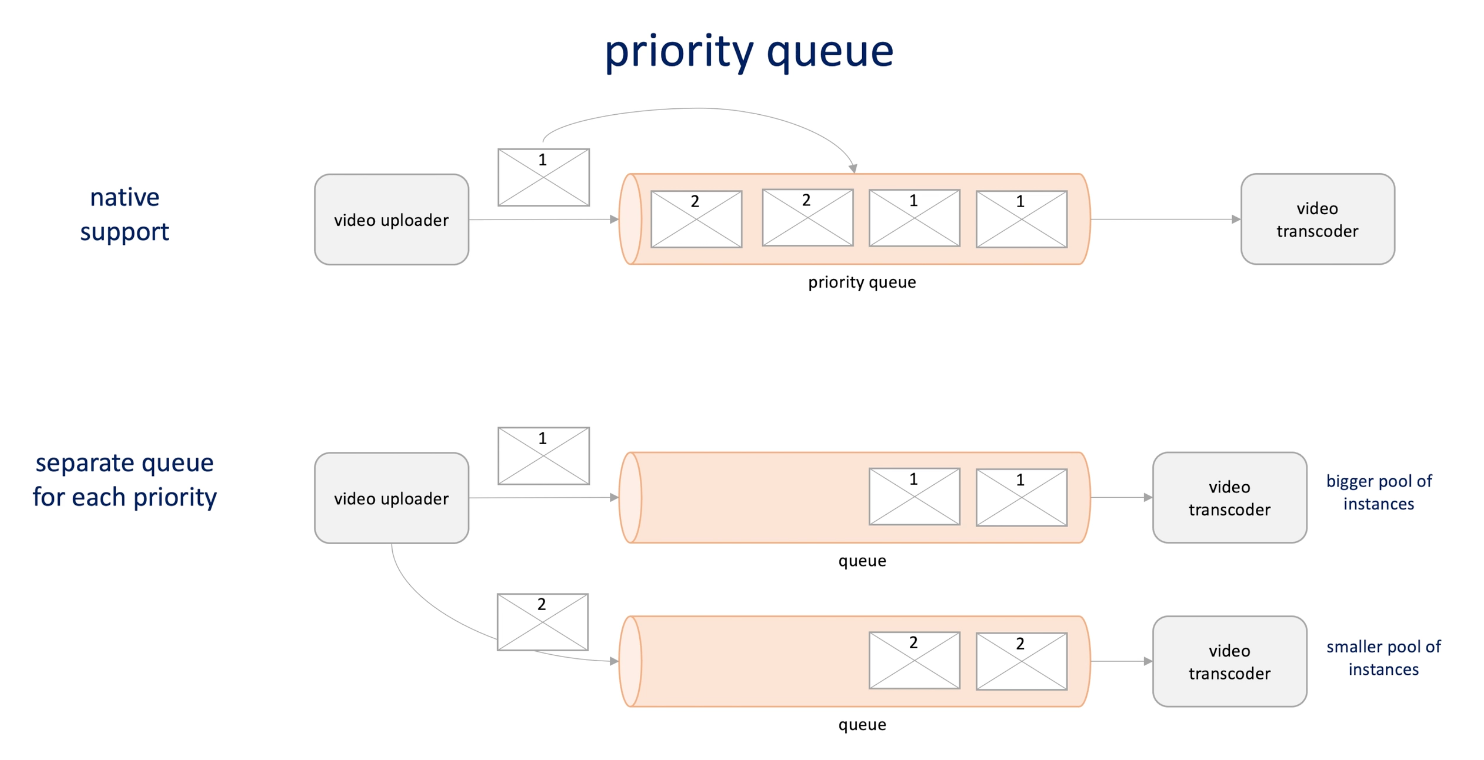
Priority queue : say we want to process videos by their size
- Some queue support priority queue natively
- Some don't so we create queue for each priority , and better consumer machine to consume the high priority message
-
Some queue has message size limit ; even they don't limit message size the large file may cause issue.
-
Claim check : Instead of send the message as itself directly, we store them in the storage and send their metadata in the queue, and when consumers receive the metadata, they fetch the data from the storage. (Big files....)
-
Alternative approach is to split the message in the producer side and merge the chunk in the consumer side.
Network Protocols
| Protocol | TCP | UDP |
|---|---|---|
| Connection Oriented | Unreliable | |
TCP
- Connection Oriented: connection between client and server is established before data can be sent;
- Handshake: 3-step connection establishment process(The client send request to the server, then server send acknowledgment back, send server send one more message back to confirm receive the server acknowledgment)
- Reliable: lost packets are detected and retransmitted;
- Sequence number: allow receivers discard duplicate packets and properly sequence reordered packets;
- Acknowledgment : allow send to determine whether to retransmit lost packets . The sender maintain a timer for each packet, if it expired and before receiving the ack, it will re-transmit the packet.
- Order: guarantee that all bytes received are in the same order at those send. (Sequence number helps that). If the order is not right, TCP buffers the out-of-order data until all data can be properly reordered.
- checksum: data can be lost and corrupted. TCP ensures correctness by using checksums. The sender calculates a short checksum value and sends the this along with the data; the receiver received the packets and calculates the checksum and compare.
- Flow control: limits the rate a send transfers data to receiver. Receiver can notify the sender its buffer allowed. And if receiver fills, it tells sender to stop sending data to allow processing. Protect receiver.
- Congestion control: the rate of dat entering server is controlled. Protect the network.
- TCP prioritize reliability over time.
UDP
- No connection: data transmits message to receiver without verifying the readiness of the state of the receiver.
- Unreliable -> no verification -> Data can be lost.
- No acknowledgment
- No retransmission
- No order
- No flow control
- No congestion control
- So it's application responsibility to control the speed of sending
- Checksum
- Broadcast : send message to all receivers simultaneously ;
- Multicast: send messages to intended receivers;
- Simpler is faster than TCP , it prioritize time over reliability.
- Application: -> Low latency is important while lost of packets can be tolerated
- Video/audio live stream
- Online games
- Auto detection of devices and services on a computer network;
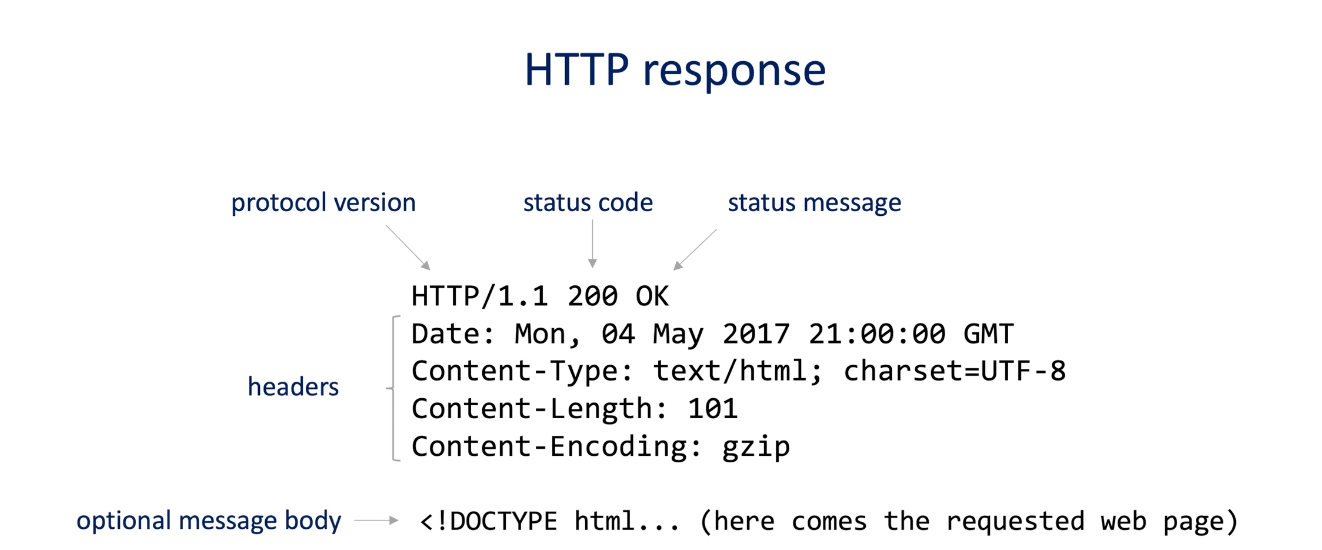
HTTP
-
Request/response : the client send an HTTP request message to the server and the server sends back an HTTP response message.
-
Older HTTP use TCP as an underlying transport protocol.
-
QUIC: HTTP/3 uses QUIC(on top of UDP) (reliable) protocol as a transport; almost equivalent to TCP but much lower latency.
-
Persistent connection: Older HTTP close at one request; newer version , single TCP connection can be reused for more than one request.
-
Multiplexing: multiple requests are sent over the same TCP connection without waiting for response. Without this, we send multiple requests one by one.
- Alternatively we can open multiple connections and send request at the same time, but this has higher cost.
-
Compression: data compressed before data transferred. This decreases latency and increate throughput.
-
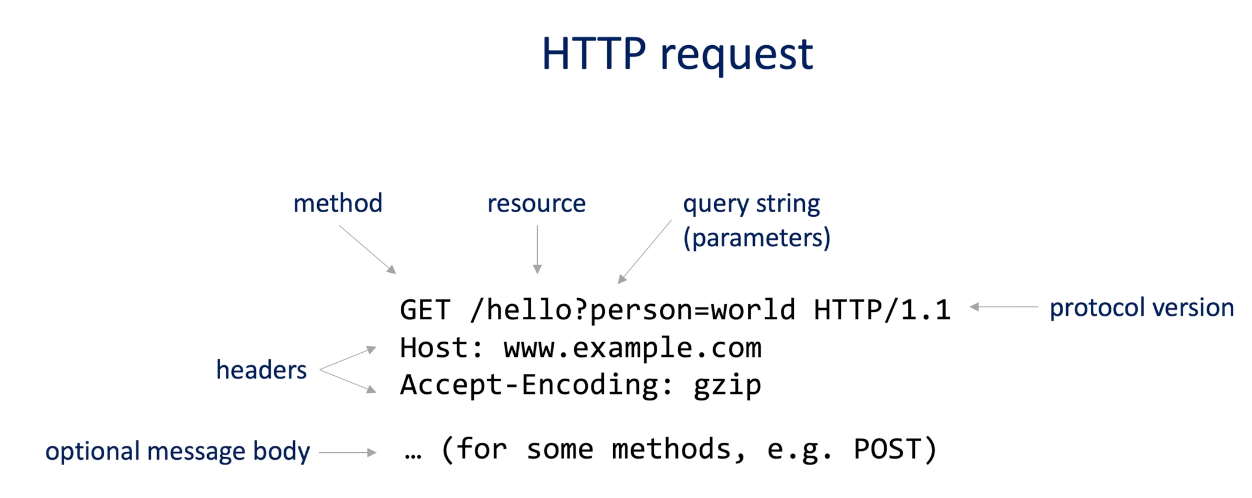
HTTP request
-
HTTP response
Blocking vs non-blocking I/O
- Sockets(blocking and non-blocking) and connections
- Thread per connection model
- Thread per request without non-blocking I/O model
- Event loop model
- Concurrency vs parallelism
-
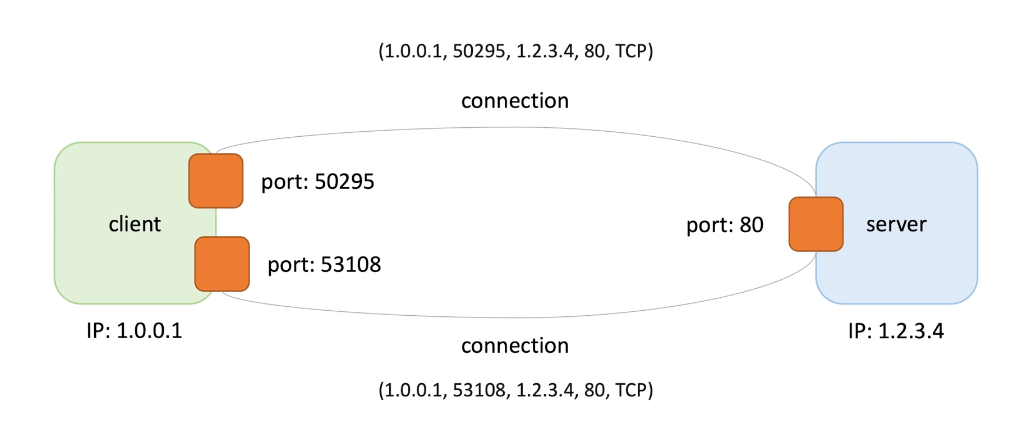
A client and a server communicate with each other using sockets;
-
A socket is a endpoint (IP + port number )
-
Each connection has a socket , each connection can be uniquely identified by its two endpoints(client and server), a socket pair.
(Source IP, source port, dest IP, dest port, protocol)
-
Server has a port, all clients know this, server listen to the sockets and waits for a client to make a connection request.
-
When a client makes a connection request, it specifies the hostname of the machine(IP)
-
The client identify itself by IP and a random port number(assigned by client OS, short lived), called ephemeral port . The ephemeral port. Allows the same client to have multiple connections to the server.
-
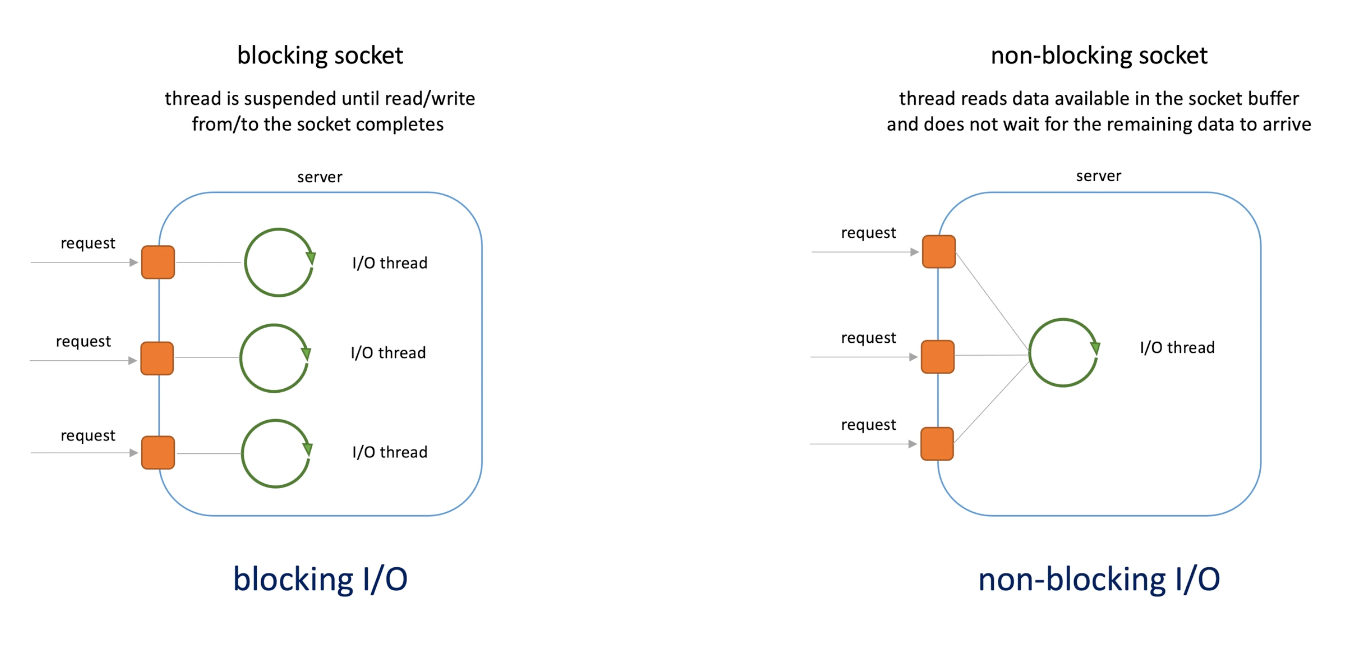
Blocking socket vs non-blocking socket
- Blocking socket: thread is suspended until read/write from/to the socket completes.
- Non-blocking: thread reads available data in the socket buffer and does not wait for the remaining data to arrive. And the do something else until remaining data arrives.
-
Blocking I/O and non-blocking I/O
- Blocking socket, the I/O thread can handle one request and if new request comes, we need a new I/O thread.
- Non blocking socket don't wait, if new request comes, it server the new request, then come back when it's free. Allows server to handle a lot more connections than blocking I/O. Since connections are cheap and threads are not.
- OS knows when to switch to other connections (request).
-
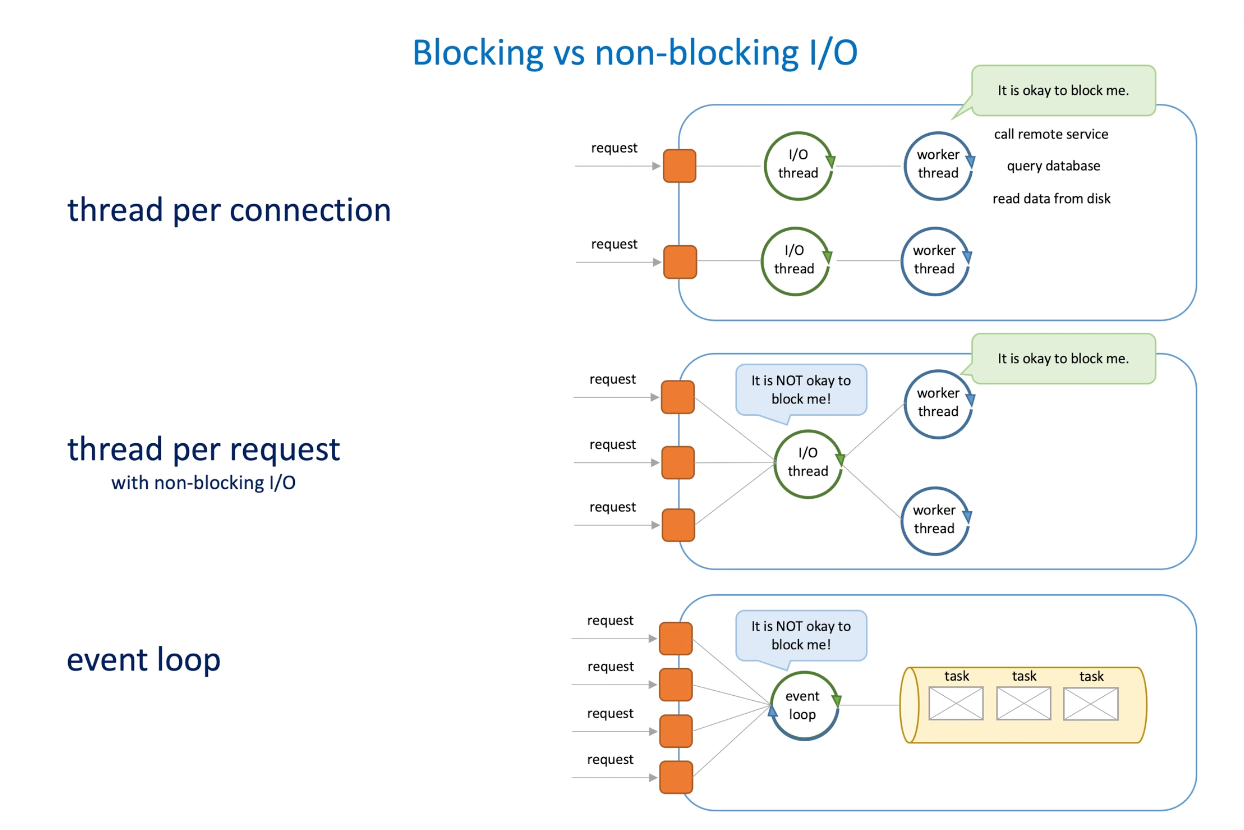
Thread per connection: each connect has its thread , thread(I/O and worker) itself can be block by some I/O(call remote service, query DB, read data from disk...),
-
Thread per request(with non-blocking I/O): single I/O thread read data and store them to dedicated buffers(for each request), when the data is enough to construct an HTTP request, the worker thread then start to processing the request. The I/O thread cannot be blocked since we have only one. The worker can be blocker since it only affect itself.
-
Event loop: no worker thread, the I/O thread itself work as the worker thread. Event loop cannot be blocked.
-
Concurrency vs parallelism
- Concurrency: One cpu work multiple task(thread), at certain time point, it only handle one thread, it do context switch to handle multiple thread in certain period of time. -> event loop.
- parallelism: multiple CPU core: multiple task can be handle simultaneously .
- Why multiple CPU: if a thread has a blocking I/O, we can switch to other CPU to work on other tasks.
- If a task has no blocking I/O, single CPU handle single task is very fast since it has no context switch and thread creation for other task.
-
Event loop create as many event loop threads as many CPU cores on the machine.
-
Pros and Cons
- Thread per connection: used in older HTTP, less scalable and more expensive in terms of resource utilization.(more threads created)
- Thread per request: (Jetty, Nginx, Tomcat): easy to implement, test and debug application(stacktrace for each request/threads). But more threads mean more resources(CPU(context switch), memory) needed, we cannot allow unlimited request so load shedding and rate limiting ...
- Event loop:(Netty, Node.js, Zuul): good for massive amount of active connections(single thread), more resilient to sudden traffic spike(single thread); but this model is hard to implement and debug(stack trace mixed and cannot followed and tracked).
-
Thread per request are good for CPU-bound workloads(compute-intensive, since non-blocking I/O doesn't help on this, nonblocking I/O helps on I/O related issue.)
-
Event loop: I/O bound -> large files.
Data Encoding formats
Textual vs binary formats
Schema sharing options
Backwards compatibility vs forwards compatibility
-
We can start to build the messaging system ; the initial structure is very simple : single server -> broker, take incoming message from producers, store message an send messages to consumers
-
Scalability, durability and availability will be discussed later; start from small;
-
First talk about data encoding formats.
-
Message has two parts :
- metadata(K-V pair): additional information of message: content type, payload size...
- message body(payload): a sequence of bytes.
-
Broker only save and send the message, the producer and consumer must have the same way of parsing the message.
-
Messages content in memory (objects) needs to encoding/serialization to payload(bytes) that can be transferred over the network and stored on disk.
-
Then the payload will be decode/deserialization to the objects that can be processed in producer.
-
Encoding formats
- textural: JSON, XML, CSV..., pro: readable, easier to debug and test ; wildly used by many language and tools ; cons: in verbal, so it has larger size -> slower serialization and deserialization
- Binary : Thrift, Protobuf, Avra; pro: smaller size, faster to serialize and deserialize. Cons: not human readable
-
Schama: due to payload contains key/filed name, it will add additional data transferred, since that are same for each message , we defines schema , which saves spaces.
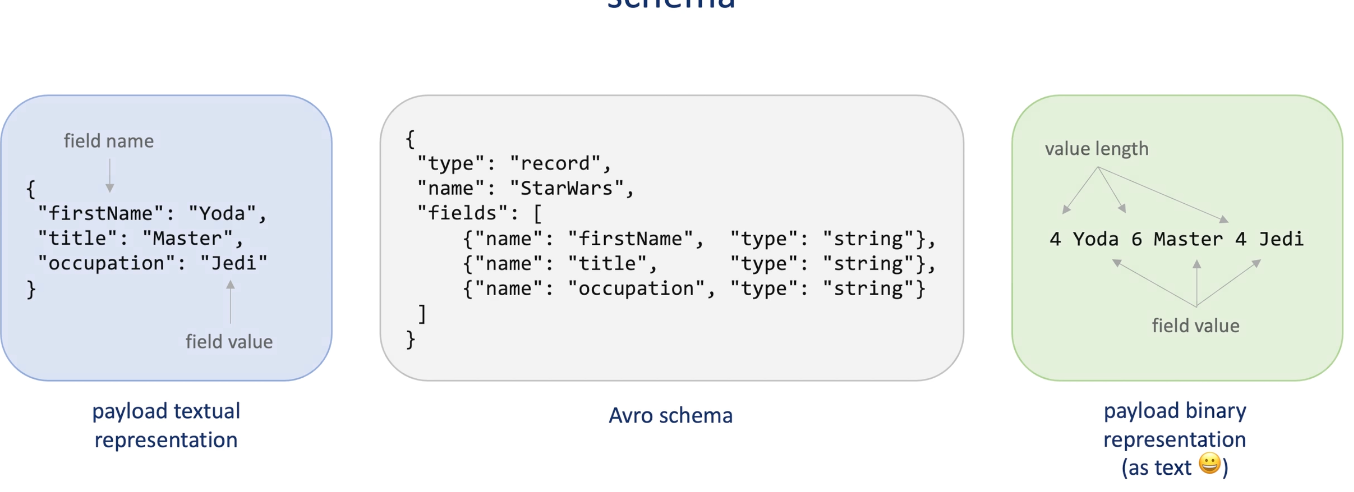
-
The producers and consumers needs to share the schema since they needs to read and writes the same message.
-
Three options of sharing schema:
- Share through code: create a schema, keep the schema, run a code generation tool to produce serialization code and deserialization code. Both producer and consumer use same code generation. Google Protobuf, Facebook Thrift, Amazon Lon.
- Schema registry: put schema into shared storage, message send from producer contains the schema id(in metadata), then consumer get the id and fetch the schema from the shared storage. The scheme should be stored in local cache to reduce the number of I/O request. Avro.
- Send through payload : increase the message size and higher transmission latency, but it has no additional schema registry. And it's easy to reprocess the message afterwards since it contains the schema itself with the message.
-
Schema changes. (Evolution) -> new schema can process old messages -> compatibility.
- Backwards : new code can read old version message.(new scheme can read old schema data)
- Forwards: current code can read newer/future version message(old schema can read new schema data)
-
In distributed system, when we introduce new version messages, we deploy changes out, we typically cannot update producer and consumers all at once, so there will be both old and new versions of data-> these messages needs to be successfully processed.
Message acknowledgement
Safe and unsafe acknowledgement models
- Acknowledgment : when the producer send the message to broker, it wants know if it's successfully sent. (Network loss/broker failed to store)
- Unsafe ack mode: fire and forget(send and done): the producer send the message and don't care about the ack or the confirmation from broker. It's fast compared with safe since it doesn't wait for broker to persist or send back message.
- Safe ack mode: producer await broker ack.
- Safe: received and store in memory or persist in disk or replicated to other machines.
- It depends what's your goals or the trade offs. Throughput vs durability.
- In safe mode, if the message hasn't been acknowledged. It may retry until receive a ack.
- It will set a time, if timeout, then the message send is regarded as failed.
- This pattern is like TCP.
- The retry will cause duplicates messages/undesired consequence -> use a sequence number to reorder.