The importance of queues in distributed system
Queue
Bounded and unbounded queues
Circular buffer and it's applications
- Message can be stored in disk and memory
- Use queue: FIFO
- unbounded queue: use as much memory as it can
- Bounded queue: limited size queue, the size is specified at creation.
- Implementation: data structure support ordering, insert and delete in constant time;
- Linklist : a pointer on the tail and head;
- Arrat : add is easy, but remove will shift all the elements ahead, so the operation is O(n)
- In the array case, the deletion is slow, so we can think of some way to avoid the shifts->(space exchange time)->circular buffer(ring buffer)
- Circular buffer maintains two pointers, read and write, (which specify next node to be read and write); when they reach the end of the array, they are set to 0(move as circle)
- it's full when the head and tail points to the same node. -> we can start overwriting the oldest data or throw an exception.
- Application of ring buffers: -> to ensure hard bound for memory utilization
- Another application is logging -> write a log entry to disk on every call to Logger is slow -> right the log in ring buffer in memory and sync the data into disk in background periodically.
- Another example : Hadoop MapReduce : for the input record, new KV pairs are generated, writing them to HDFS will cause additional replication and IO and may be slow -> so we write the k/v s into a ring buffer and when the buffer is full-> Spilling(copy data from memory buffer to disk)
Full and empty queue problems
Load shedding
Rate limiting
What to do with failed requests
Backpression
Elastic scaling
- Two corner cases for bounded queue : full(arrival rate > retrieve rate) and empty (arrive rate < retrieve rate) queue.
-
Full queue
- Drop incoming message -> load shedding , rate limiting
- Force producer to slow down -> back pressure
- Scale the consumer up to consume fast -> elastic scaling
-
Load shedding
-
For single machine, we the queue is full, the write to queue process start drop the message(with/without tell the producer)
-
In distributed system, the write process in the single machine becomes a monitoring system, it monitors the CPU load/memory utilization/average response latency..., when the CPU utilization is too high(for instance), machines in the cluster will start drop the messages
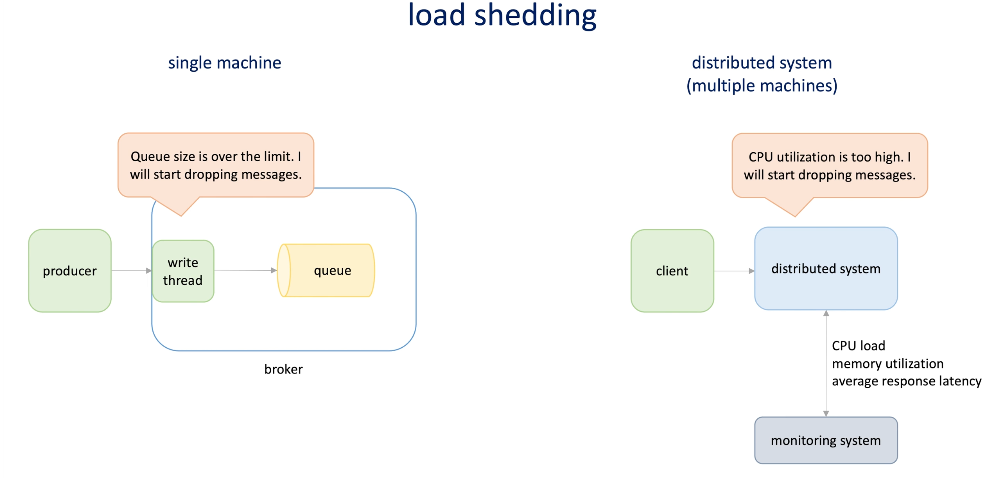
-
-
Rate Limiting: every producer gets a quote limiting how many messages this producer can send to the broker.
-
Single machine: count the # of request in memory
-
Distributed system : external cache saves the rate limiting info.
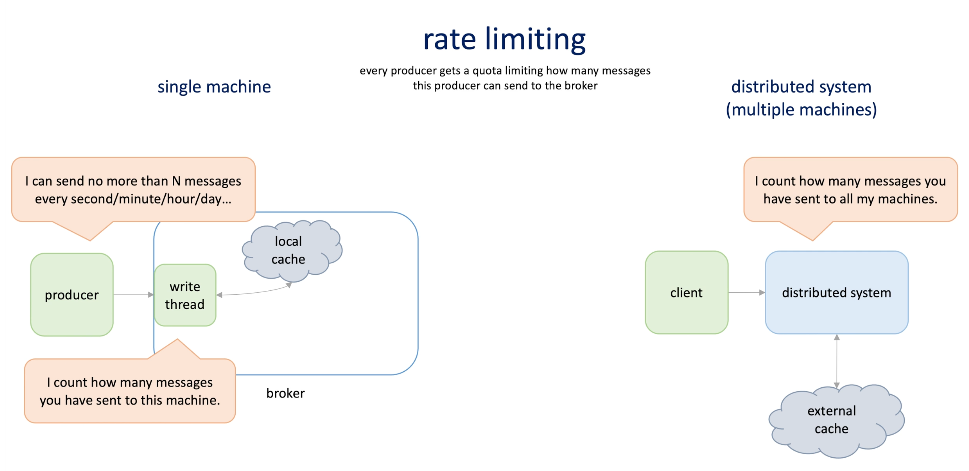
-
-
Broker should tell producer he is busy, the broker can:
- Ignore and do nothing
- Buffer messages(in memory or disk) and send later;
- Propagate the exception further up the stack (sync call in a chain)
- Send messages over the limit to a temp storage(another broker or system);
- Retry immediately -> bad -> cause retry storm
-
If producer not know how to handle this situation (full), then broker can tell the producer to slow down -> Backpressure.
- Single machine : limit the number of processing messages from producer; when all threads are in woking and blocked, the producer cannot send more messages thus back pressured
- Distributed system : load balancer will load balance, but when all full, LB will tell the client that they cannot process more messages -> producer can buffer the message, propagate the info to machines in the cluster, fall back to different system, drop message
-
Elastic scaling
- Single: by introducing a dynamic pool -> Semaphores can help inform
- Distributed: dynamically add more consumers -> competing consumer pattern
-
Empty queue:
- How to read element from queue: scheduled job or for loop -> but when the queen is empty the will keep listening the queue(even if they are empty)
- Configure the loop or schedule job to less often -> help but new problem -> messaging processing latency increase
-
Broker push message when available; -> Websocket
-
Broker block the pull request and waits for messages -> long polling
Start with something simple
Similarities between single machine and distributed system concept
Interview tips
- When you don't know where to start, start from simple ( single machine model)
- Start with outlining key components of the solution, thinking in terms of classed, libs and threads -> this will give you clue which components can be converted to standalone service in distributed world.
- Bottom up
Blocking queue and producer-consumer patterns
Producer-consumer pattern
Wait and notify pattern
Semaphores
Blocking queue applications
-
Blocking queue is a queue that provides blocking put and take methods ; when the queue is full it block put operation and when it's empty it blocks the take operation.
-
Blocking queue can help implement backpressure, long polling , and producer-consumer pattern .
-
Producer-consumer patterns can be implement without blocking queues but it requires concurrent programming techniques.
- Wait and notify, wait pause the execution of a thread while notify wakes up a waiting thread.
- Queue is full, producer calls wait, meanwhile consumer retrieves message from queue; can notify consumer thread
- and when it's empty, consumer calls wait and calls notify when there is a signal from producer thread;
-
Or use semaphores (like a counter) to implement the producer consumers
- What: hold a set of permits , each thread can acquire a permit. If available, reduce one, when the thread release the permit, it increate by one;
- To implement the producer - consumer pattern: two permit. Record the occupied spots and empty spots.
- When a new element is added to the queue, occupied plus one and empty minus one.
-
Application: Notification system,When we have a set of ready to send messages, each message will be sent to one or more subscribers.
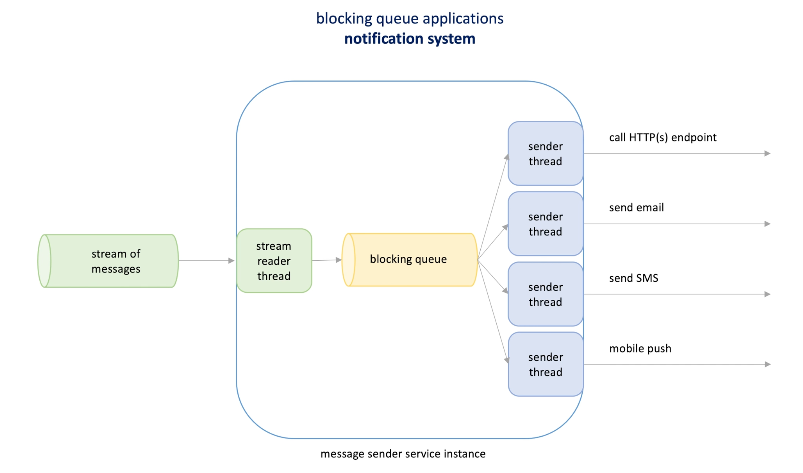
-
Data aggregation service (when we have a stream of events) to count(views in Youtube): aggregate data in memory and sent to a blocking queue.
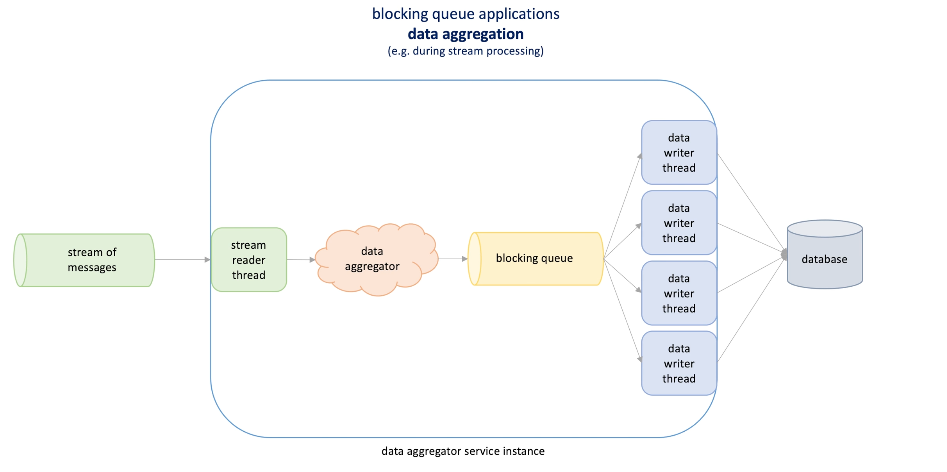
-
Thread pool
Thread pool
Pros and cons of thread pool
CPU-bound and I/O bound tasks
Graceful shutdown
- Thread per request : Process request concurrently -> Increase throughput
- create and stop thread are expensive, when too many request comes, -> OOM
- Even if OOM not happen, CPU may be exhausted -> long running task occupy CPU and some other thread has no CPU time -> thread starvation
- We need manage thread: reuse thread and make sure certain number of thread existing
- Thread pool:
- Increasing performance -> decreasing latency -> fixed number of thread, not too much create and terminate
- Make application stable and predictable
- Simplify coding(don't not to manage thread lifecycle and focus task )
- Define the size of the thread pool is hard(small no use, large OOM/CPU starvation)
- And long running tasks clog the thread pool -> managed by timeouts(failed or re-queue)
- Sizing:
- CPU bound: size = CPU count + 1;(most of the time no all CPU will be used)
- I/O bound : size = CPU count * (1 + wait time/service time);
- In actually : run a load test and see the CPU utilization
- Graceful shutdown:
- Don't allow new thread/message
- Running task are waited to be completed
- (Max wait time are specified to avoid long waiting)
- Cancel the remaining tasks(ensure no task are lost)
- The graceful shutdown algorithm can be applied to many things. Stop receiving new request/task and allow existing jobs finish.
Big compute architecture
Bath computing model
Embarrassingly parallel problems
- Thread pool pattern can be mapped to large scale -> VM pools to perform parallel computation across thousands CPUs.
- This model works well when tasks are homogeneous(they an alike), arrive at the almost the same rate(stream of tasks), independent and small task ;
- But when tasks are heterogeneous ( some tasks consume much more resources), task a coupled or represents batch jobs or task takes long time to run-> batch computing
- Batch computing normally has a job scheduler / definer , send the job to the coordinator, then the coordinator send the job to different VM pools. -> AWS batch /Azure Batch services.
- Big Compute: High performance computing(HPC): -> to salve parallel problems ->
- large volume data processing-> e.g. trading transaction, clickstream events application log files -> analysis that we don't need it to process in realtime
- Build thousands of ML models: e.g. Netflix trains personalize page for each customer .
- Perform computationally intensive operations: e.g. weather forecasting, climate simulation, drop discovery, analysis of genomic sequence.
- MapReduce vs Big Compute