Log
Memory vs Disk
Log segment
Message position(offset)
-
For broker, keeping message in memory makes gets and puts fast; but the memory are limited.
-
When there is spike(producer send more messages), or message is too big or consumers gets slower. -> we need to drop the failed messages or store them somewhere else.
-
If some of the messages are kept in memory, when it crashes or quit, messages are lost.
-
RabbitMQ and ActiveMQ keep messages in both memory and disk, while Kafka store memory solely on disk.
-
Log: (like a queue in memory): a file in the disk and append only; messages have id and append to the file. -> append-only and ordered.
-
Difference between application logs and data logs/journal -> application logs are for human (human readable) while data logs are a sequence of bytes for program to read;
-
Log operations
-
Adding: append to file
-
Deletion: when the message is consumed, we want to release the space, a message will be split into chunk/segment and stores into many files.(so they are smaller and easy/take less time to handle)
-
Retrieval:
-
Naive : iterate segments
-
Better : keep the position of the segments file;
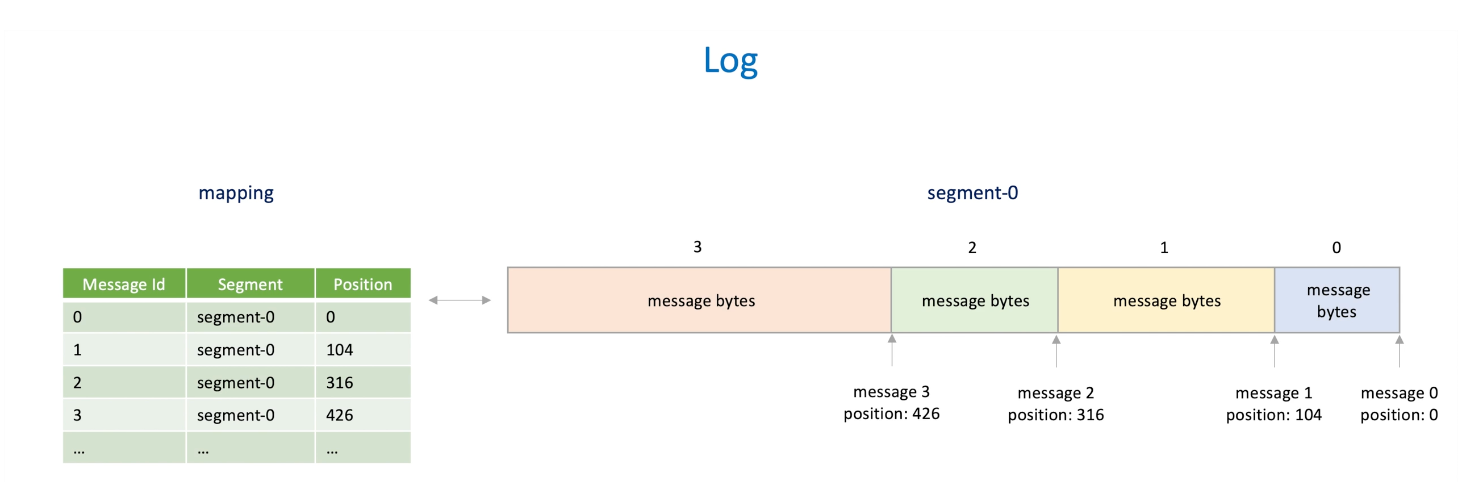
-
Where and how to store this mapping? -> in memory so it's quick to access
-
For how, see below section.
-
-
Index
How to implement an efficient index for a messaging system?
-
Indices in database are similar to the thoughts above;
-
Index: a lookup table that database search engines used to speed up data retrieval.
-
Implementing index in a messaging system :
- One index(hash table) for all segments : (message id, segment id + position)
- Index for each segment: (message id, position) -> allows to load only active used indexes into memory (not all) and make it easy to drop indices along with segments.
-
How to find the message index by message id? -> iterate all segment indices or -> another index table that stores the index info.
-
(This is how Kafka do) e.g. we want retrieve a message with id 2;
- We binary search the id range index and find the segment ;
- Then look up segment by the segment index to find the position of the message;
- Then go to the segment and retrieve the message.
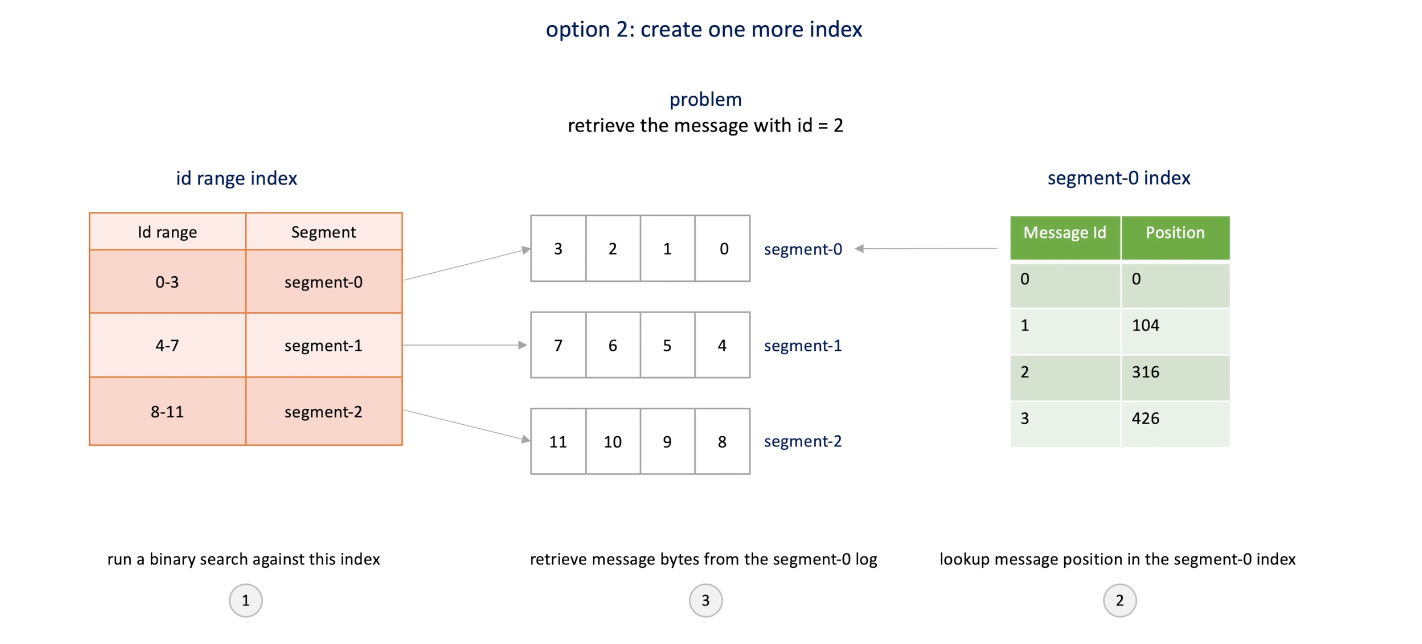
-
Are the indices as vulnerable as before (in memory) -> no
- They can be re-created using original data/logs;
- If option1 is slow or complicated, indices can be stored in disk and retrieved.
Time series data
How to store and retrieve time series data at scale with low latency.
-
Time series data: a sequence of data collected over time intervals.
-
Data needs to collect, view and analyze over time;
- IoT: signals from devices;
- Monitoring : app perf metrics
- Social media: view stream data(views, likes...)
- Stock trading: capture the price change;
-
Two types : measurement get at regular/irregular time intervals
- Regular: system health metrics,
- Irregular: views on Youtube
-
Messages are time series data
-
In a single machine, the memory store the segment indexes and disk stores the segment files
-
Move to distributed system
- Data log file -> S3
- Indexes -> DynamoDB(low latency)
-
When times series data comes, the write service store indexes into in-mem database and store bytes into object storage.
-
we create a new S3 when the objects grows over the limit;
-
When user retrieve particular time range objects, the read service query the index to identify the positions of objects and fetch data from object storage S3.
-
This pattern is useful when design a solution for retrieving and storing time series data at scale and low latency.
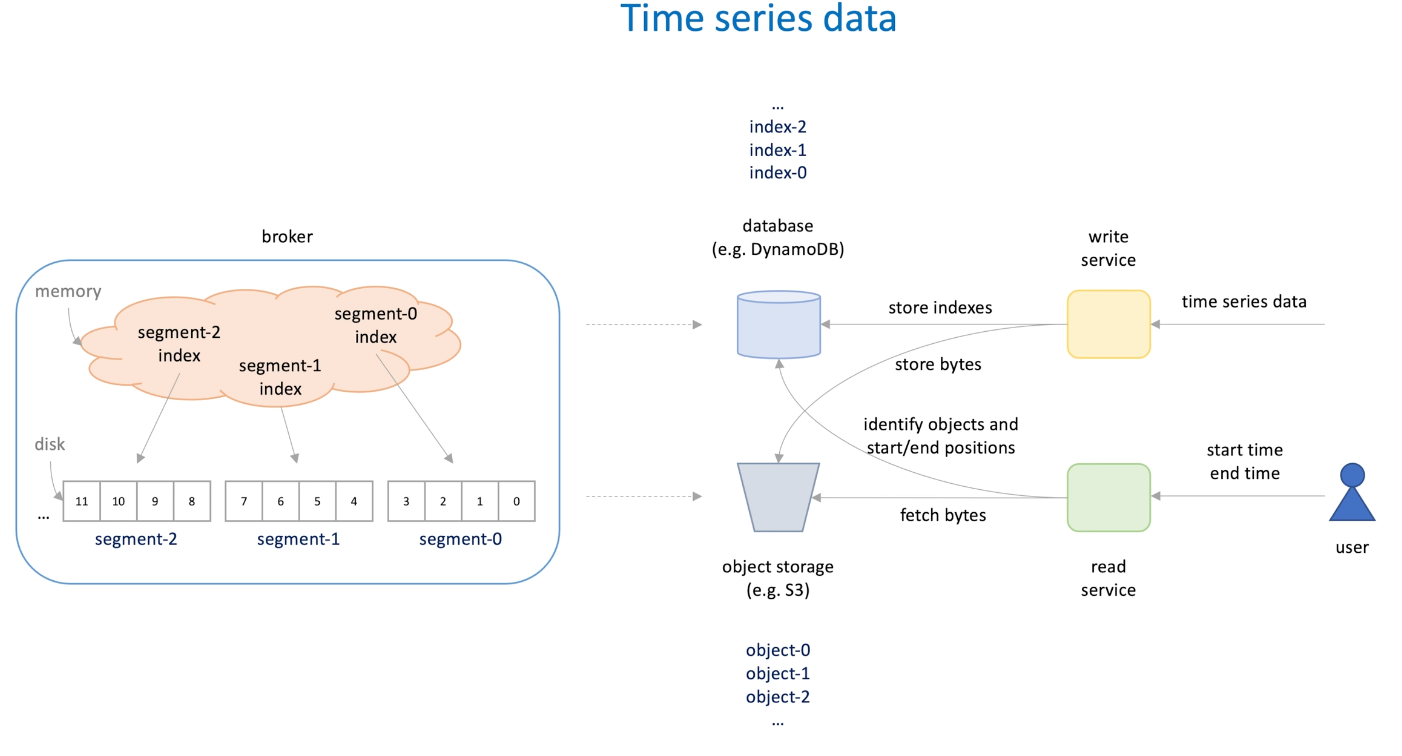
Simple Key-value database
How to build a simple k-v database
Log compaction
- CRUD
- C: append records (key, v, timestamp, len....)
- R: in mem index to accelerate read;
- U: append record->duplicate key->index update position to the latest version;
- D:
- In messaging system, we don't delete segment until all messages in the segment are consumed; -> assume or precondition is the message in the segment will all be deleted eventually(messaging system);
- Here in the db is different: some are deleted, some stays forever, -> so we cannot rely on the all records delete so to delete the segment
- Tombstone : (same key with the record deleted) indicate the record is deleted, when a retrieve request comes, it checks the tombstone, find the record deleted and return nothing.
- Constantly append : Limited disk space ; indexes are too big and stores in the disk(not enough memory for index) -> high latency ; poor support to range query.
- To additive first concern(append only) -> log compaction
- Log companion ensure the newest records are retained and old records with the same key are deleted;
- A background thread ->
- Copy all segments from old to the new one;
- If there tombstone for record, the record is abandoned;(during copying)
- If there are duplicated keys for record, only newest one will be kept.
- Compaction makes segments smaller; and smaller segments can be combined for faster access since less segments has less index -> it's faster
- The default storage engine in Risk, a distributed NoSQL k-v store is based on this idea. ->
- Write: fast because append only and query index in memory .
- Read: single disk seek to retrieve the value.
B-tree index
How db and messaging system use B-tree
-
Hash works well when we can hold all the keys in memory; when the # of keys grows and no memory to hold them ->
-
One approach is split the hash into smaller pieces and store them in the disk; then hold the index of indexes in memory which is smaller comparing to original hash; (binary search for looking up)
-
e.g. if we want to load the record5, here is the process:
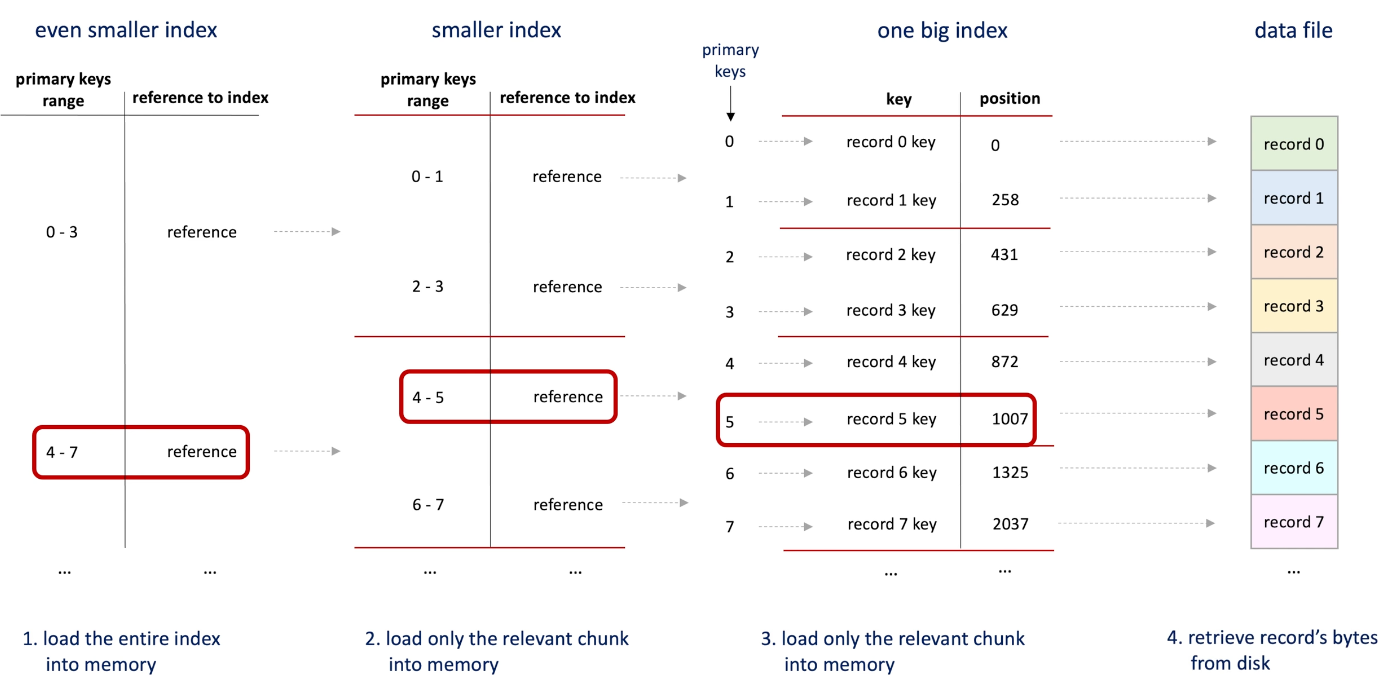
-
B-tree: self balance tree structure
- Widely used in DB and file system
- Self-balanced: means when the nodes are added or deleted, the tree modifies its structure to keep its height low. -> Log(n) operation
-
Pages: basic fixed size blocks in b-tree
-
Leaf pages either contain data or contain reference to data files where data can be retrieved.
-
Non-leaf pages contains keys and reference to the child pages. (Range data)
-
Root: when looking for a page, start with a root.
-
The b-tree is used in almost all relational databases; e.g.

- For the above table we have generated a column key, and it's indexed, so when we are fetching the data by key, we can use the b-tree index to find the data;
- But if we want find the data by some other columns, for example, last name, we don't have index on it so the data will be check in sequence, which is pretty slow;
- To address this, we can add one more index on this column. And all the node keeps the reference to the PK, the search the tree find the last name, then search the first index by the PK, then the get the whole node(all information).
-
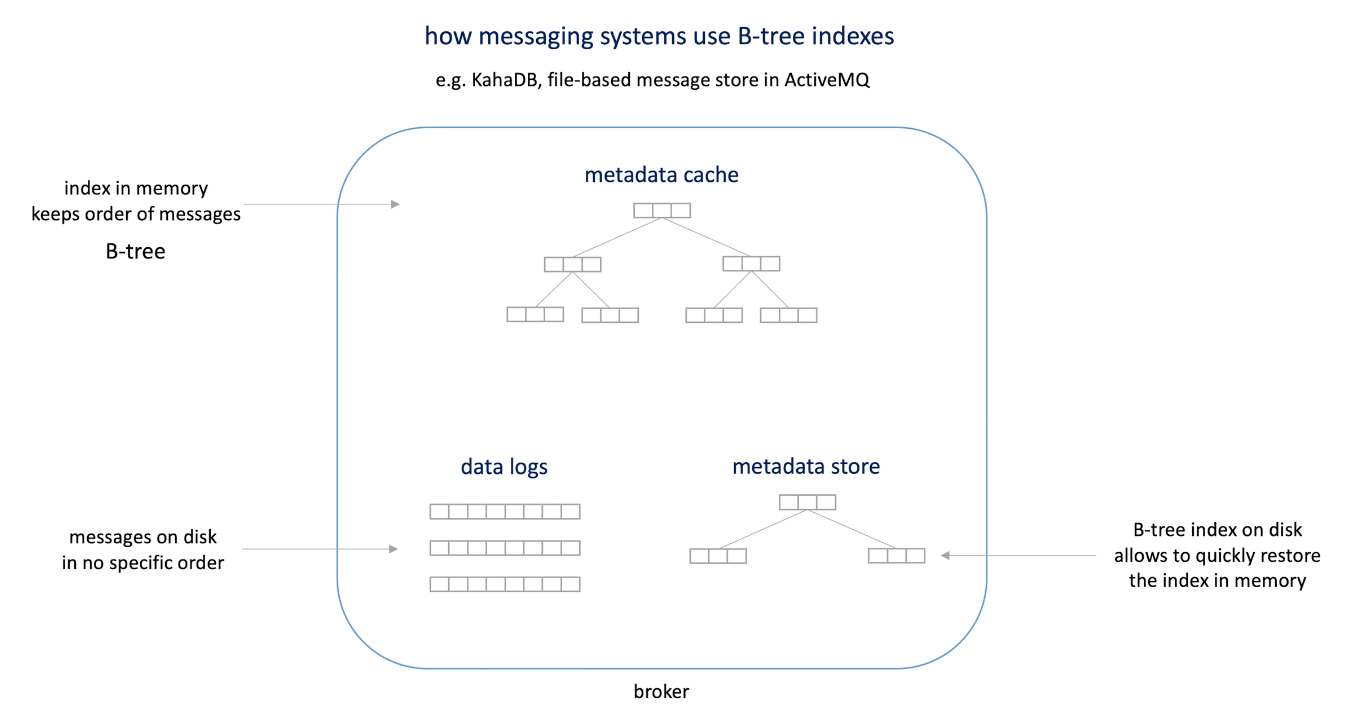
In messaging system, KahaDB, file-based message store in ActiveMQ.
-
Three parts:
- Data logs on diskI(messages)
- Metadata cache in memory as B-tree to accelerate the data query; when message comes in or consumed, the tree will rebalance itself.
- Metadata store to 1. hold the cache that cannot be put in memory due to size limit(pages will be swapped in and out); 2. Help rebuild the metadata cache(instead of iterate over all data logs)
Embedded database
Embedded vs remote database
- Normally when we are referring database, we are talking about remote database, database that runs one a dedicated server. SQL or NoSQL
- Clients make remote call to the server.
- There may be multiple servers -> distributed database
- Remote database -> live outside the application that use them.
- Issues:
- latency -> network, I/O to another server increase the processing time. -> message insertion and retrieve results in a remote call
- Failure mode
- Database is down/or slow
- Traffic burst -> Network partition
- Cache is full -> Flush cache to database immediately
- Cost big database is expensive -> cache ?
- Ineffective in messaging system read and write once
- Embedded database : integrated with the application that uses it.
- They are fine-tuned to be lightweight and resources it uses.
- They are fast and no need to make remote calls
- SQL andNp-SQL
- They support store in-memory, on-disk, and hybrid.
- Usage
- Many distributed system use them as a backend storage engine;
- Mobile devices and IoT devices used ;
- Good fit for a replacement for ad hoc disk files.
- As local cache: data enrichment/real-time analytics, ML
RockDB
Memtable
Write-ahead log
Sorted string table (SSTable)
-
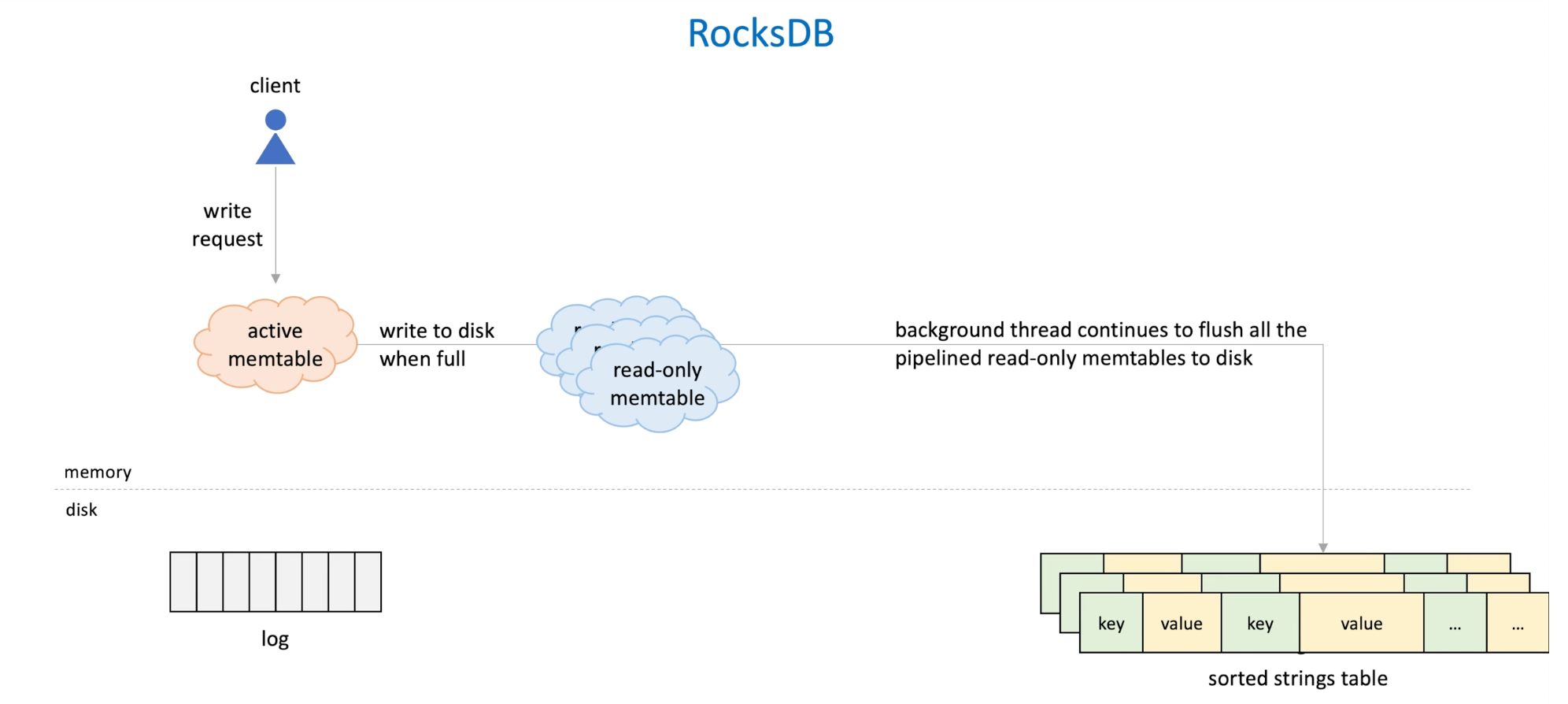
RockDB three basic constructs:
- Memtable:
- in memory buffer that takes incoming writes.
- Default implementation: SkipList(sorted set data structure)-> can be other implementations like self-balancing tree(R-B tree)
- Log file
- WAL(write ahead log): append only that capture writes
- Used to restore memtable after database crash.
- Sorted strings table
- File of k-v Paris sorted by keys
- To persist the data from memtable when memtable is full
- Memtable:
-
Workflow of database
- There is a write request , then data write to the memtable;
- Meanwhile log is appended to the write ahead log in disk;
- When memtable is full, it becomes immutable-> read only;
- then we write the data to the sorted string table -> Memtable has sorted keys(binary tree), by doing in-order traversal, data can be written to SSTable efficiently.
- Meanwhile, a new active memtable is allocated and all writes go to it. When it's full, the same things happens here->the background thread add the meltable to flush pipeline to flush all the memtables to the disk
-
So at any time point, there may be several memtables, one accepting writes and others waiting to be flushed, each of them is associated with a WAL.
-
When memtable are flushed, the log WALs are archived; after sometime, it's purged from disk.
-
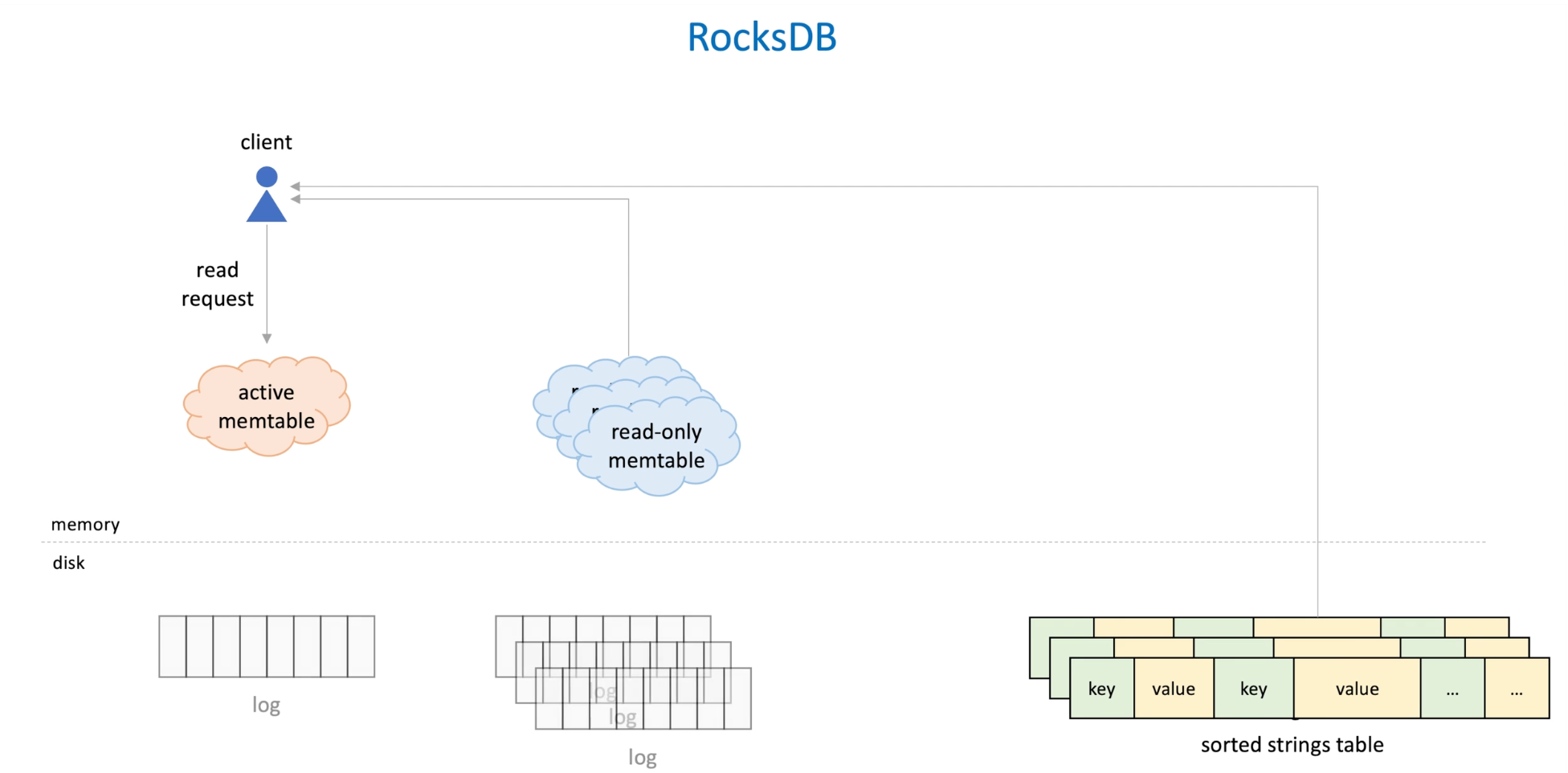
Reads: it goes active memtable, if no desired data, goto read only memtable; if no desired data goto SSTable.
-
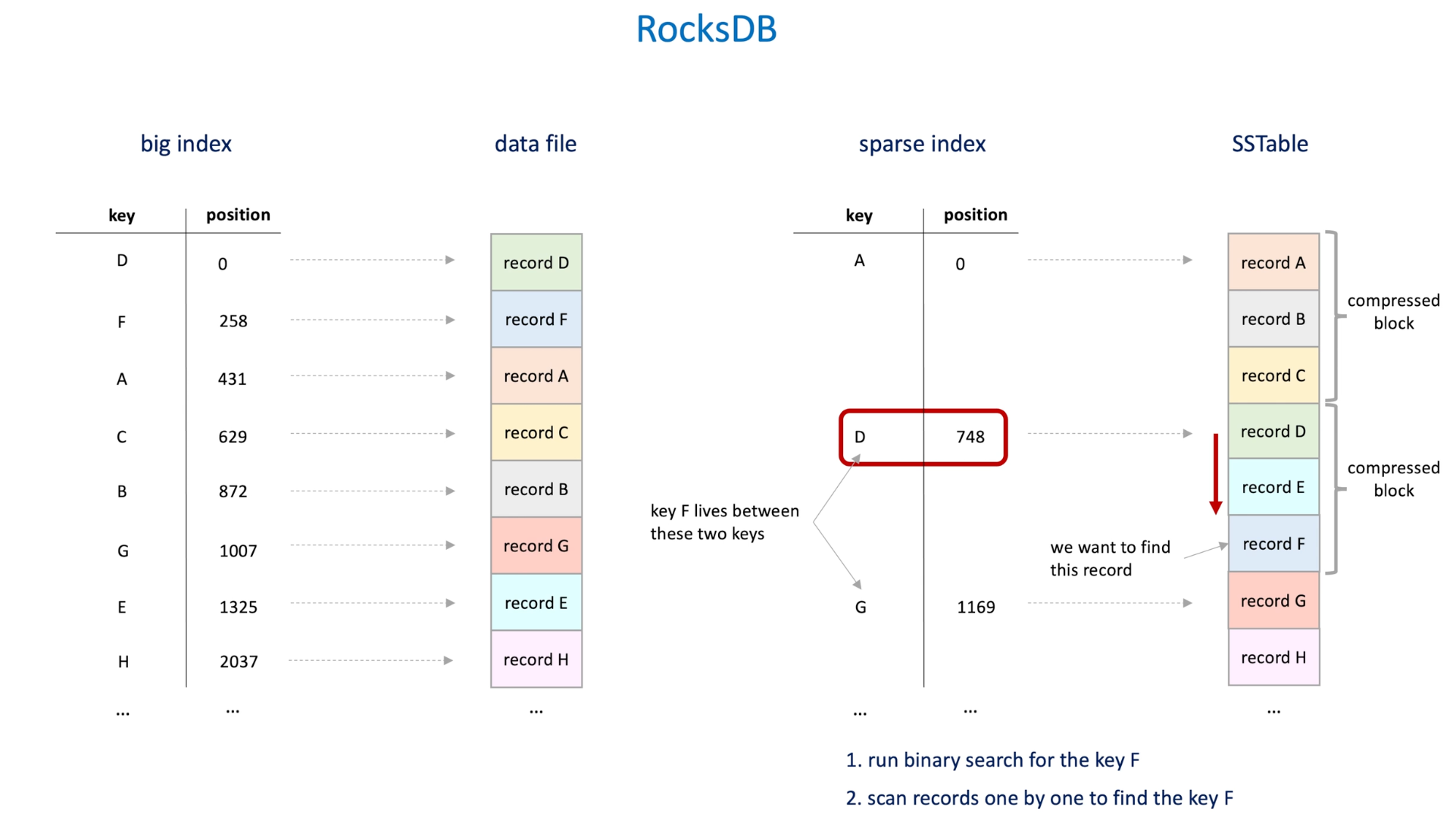
Why database stores keys in sorted order -> speed reads and writes.
- Keys are stored as a range in another level;(subset)
- Block(grouped data) are compressed to minimize the disk scan/IO -> keys point to the start of the block, whole block is read from a disk scan.
-
If key does not exists? -> full scan is slow -> bloom filter -> memory efficient data structure that can quick check if a data exists in database.
-
Memtable can also apply to memtables to reduce CPU when memtable if large
-
SSTables are compacted periodically by background thread -> to reduce delete and duplicate keys -> can be done efficiently since keys are sorted. -> merge sort
LSM-tree vs B-tree
Log-structured merge-tree data structure
Write amplification and read amplification
- The data structure described above is called LSM-tree;
- Google Bigtable ,Hbases, Cassandra, LevelDB, InfluxDB
- b-tree-> MySQL, postgreSQL, CouchDB.
- LSM-tree are fast in writes since writes are buffered in memory and flushed to disk sequentially. B-tree is slow because when there is update or insert, it needs to rebalance the whole tree->multiple writes to the disk.
- write amplification: a single write to database result multiple writes;
- Read amplification: a single read to database result multiple reads;
- B-tree can be quick since it's balanced ; while LSM-tree can be slow if it scans many SSTable.
- But don't judge that LSM-tree is only good for wire heavy and B-tree is good for read heavy database.
- LSM-tree optimization to speed up reads -> bloom filter and in memory cache; and if system mostly queries recently inserted data, such data may still in memory and can be fetched pretty fast.
- Sharding is applicable to increate write throughput for both kinds of trees;
- A distributed cache can increase read throughput and reduce latency.
- There are ways of improving the read and write efficiency so the engine level algorithm becomes less relevant.
- B-trees has more predictable performance since LSM-tree has background threads to do flush and compaction -> may be in trouble and increase latency.
- LSM-trees has compaction that help to avoid disk fragment which increate the disk utilization. B-tree split can exceeds the limit of the space or when the segment is deleted, there will be unused spaces.

Page cache
How to increase disk throughput (batching, zero-copy read)
-
To increase throughput , typically we need to a address two questions
- Too many small I/Os -> batching
- Excessive byte copy -> zero-copy read
-
batching: avoid to write to disk one by one, we buffer a batch of them in memory and send all at once
- Messaging sending to avoid disk I/Os
- Messaging sending to avoid network I/O
-
Where and how to buffer ? -> OS page cache (a disk cache)
-
Page is a fixed-length block of virtual memory. Smallest unit of memory management.
-
When application write data to file, the data is firstly write to the page cache, then stays there until it must be written to the disk :
- Application explicitly request to flush
- OS decides to flush based on its own policy
-
When application reads data, it will load from disk and adds to cache, when read again, it read from cache.
-
All physical memory not directly allocated to applications is typically use by the operating system for page cache.
-
In messaging system, when storing messages
-
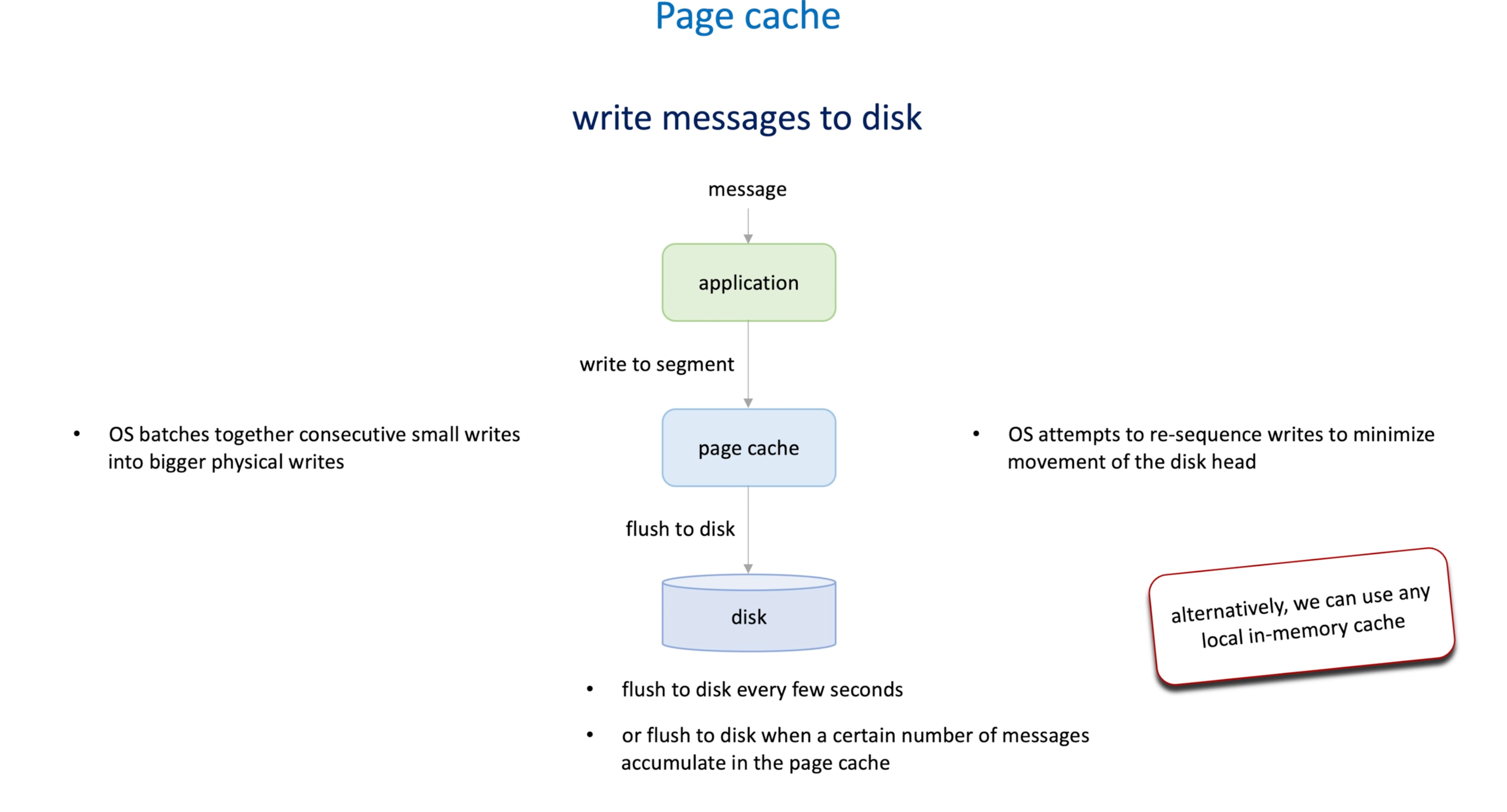
Records are are write to segment ,
-
Then the data write to page cache (OS do some optimization by batching consecutive small write into bigger physical writes, and reorder the writes to minimize the movements of disk head)
-
Then page cache flush to disk after a few seconds or a number of messages accumulated.
-
We can use any local in-mem cache to buffering messages. (Page cache is a alternative cache provided by the OS)
-
-
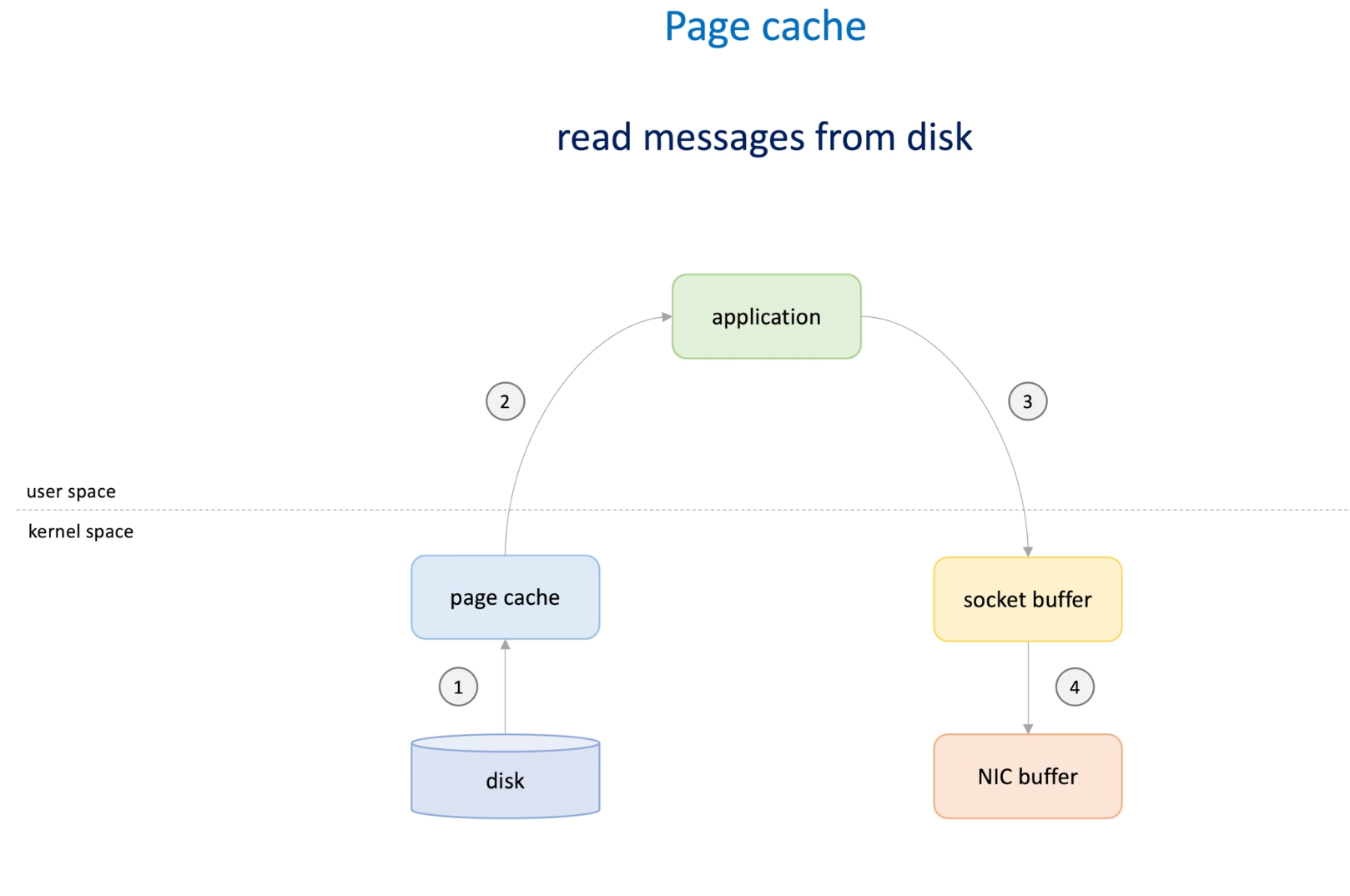
When reading messages from disk :
-
Kennel space and applications space : kernel space for running OS and application space for running application
-
In Linux:
- OS read data from disk to page cache in kernel space;
- Application read data from page to from kernel to user space;
- Application writes data to socket buffer in kernel space;
- OS copy data from socket buffer to the NIC buffer to send the data
-
Data copied four times
-
-
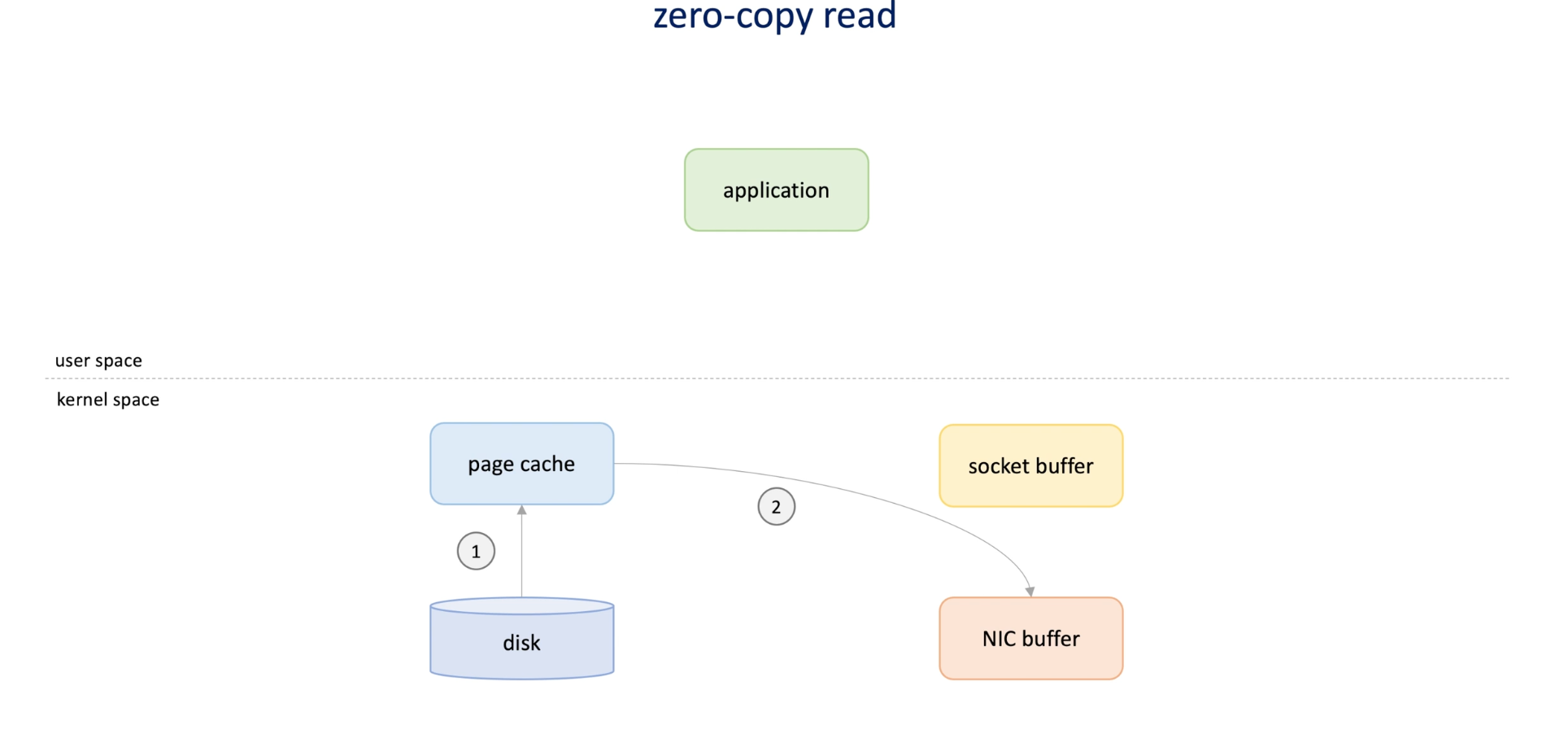
To avoid this -> Zero copy read
-
Zero copy read: disk send data to page cache -> then send to NIC buffer directly. -> fast
-
This happens when we don't need any data manipulation(like filtering messages) in application, otherwise the data must need to be loaded from kernel to application.
-
Risk : broker accepted the message and added it to the page cache , then send ack to the producer. What if flush failed or the page cache crashed? The data is lost while the producer received a successful ack. -> the pain of in-memory buffer -> flush after every write may cause performance issue. -> message replication.
-
Kafka uses this way page cache in write and reads.