Push vs Pull
Pros and cons of push and pull model
- Push: broker pushes messages to the consumer;(broker in charge)
- Pro: Optimized for latency: broker can send out message immediately ;
- Pro: client(consumer) logic is lightweight -> only send message and don't track message status ;
- Pro: load balancing among competing consumers ;
- Con: flow control-> need to send fast or slow depends on the consumption speed;
- Con: due to this flow control, the broker logic is more complex.
- Pull: consumer pull data from broker;(consumer in charge)
- Con: polling a tight loop: consumer needs to check often ;
- Con: client logic is more complex;
- Pro: optimized for throughput -> control consume speed ;
- Pro: better suit for message replay;
- Push model send the message out and may delete it; if we don't delete it and want to keep it for a while; -> challenge is : track the next message position for every consumer;
- Pull mode for each consumer to track the last message processed; -> send to broker when request(pull) next messages; -> if there is a bug and fixed in 24 hours later, consumers may rewind the position 24 hour back and replay all messages one more time.
- Pull based model is better for replay, but push also can do it though.
Host Discovery
How to design a DNS-like system
How DNS works
Anycast network routing method.
-
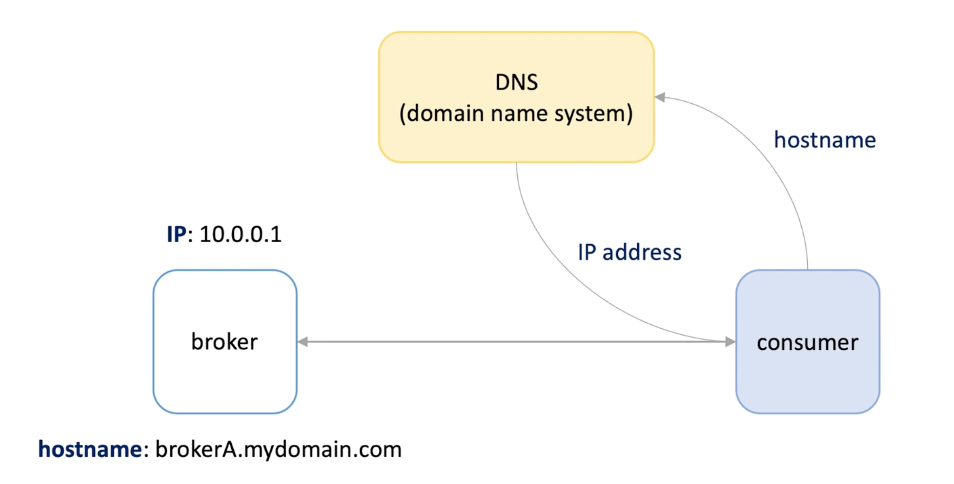
Consumer and broker needs to find each other.
-
Lets start with a single machine situation: ->
-
Broker has a host name and ip,
-
Consumer start up and look for ip address by host name in DNS
-
-
DNS: like a phone , maintain a list of hostname and translate to IP address , large amount
-
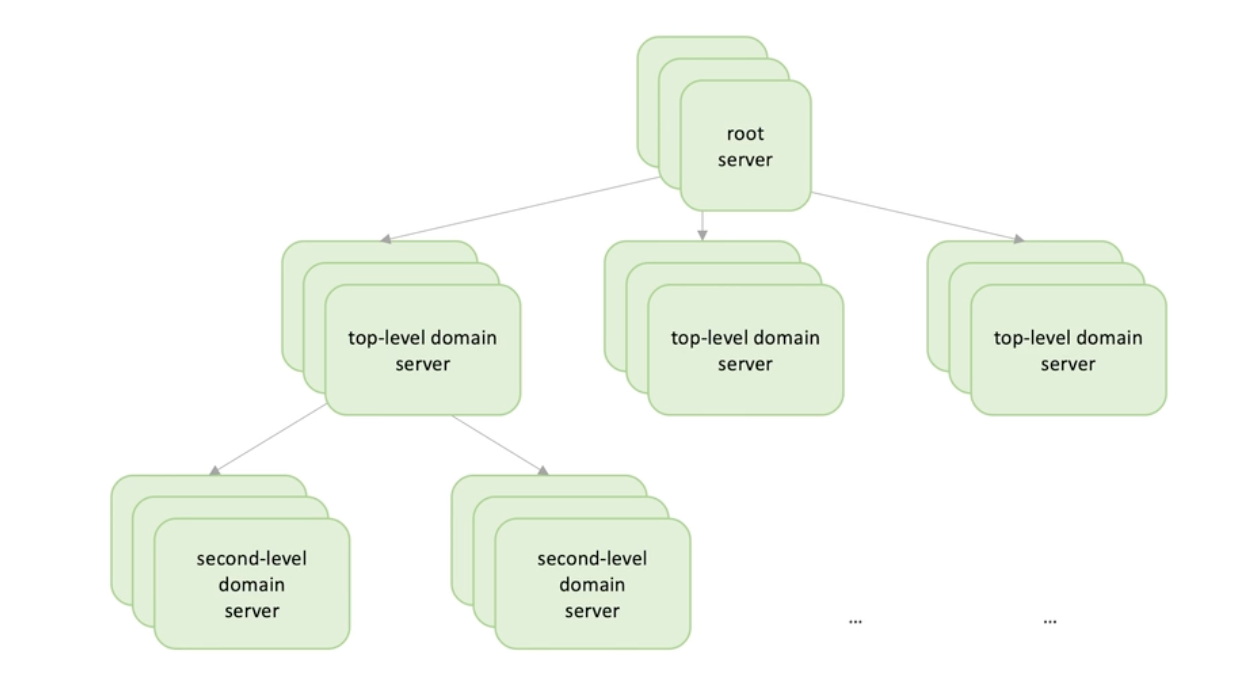
One server cannot hold many data-> data chunked -> to accelerate lookup -> b-tree in storage.
- How to chunk(split) -> range or domain (com, org, info...)
-
But if every request goes from the root server and do a level look up query, this would be bottleneck and single point failure
- Single point failure -> redundancy -> each node is actually a set of servers.
- Performance -> use cache
-
Actual workflow
- Consumer looking for ip of broker;
- Consumer talk to local cache in the OS, if found return the IP, else
- Not found -> talk to ISP
- IPS check its cache, if found return the IP , else
- Not found -> talk to top level servers -? TLD DNS server -....-> final level ;
- Authoritative DNS server return the ip and TTL to ISP DNS resolver(server)
- Then return those messages to the consumer
-
Basic knowledge
- Hundreds of root name servers spread all over the world
- Root servers are divided into 13 sets;
- 12 orgs operates each set of servers;
- Every root severs has there IPs and every ISO DNS serves knows list of 13 root servers
- Any cast routing is used to distribute request across root servers based on load and proximity("distance")
- Caching used different places to off-load the root servers (browser, OS, iSP resolvers)
-
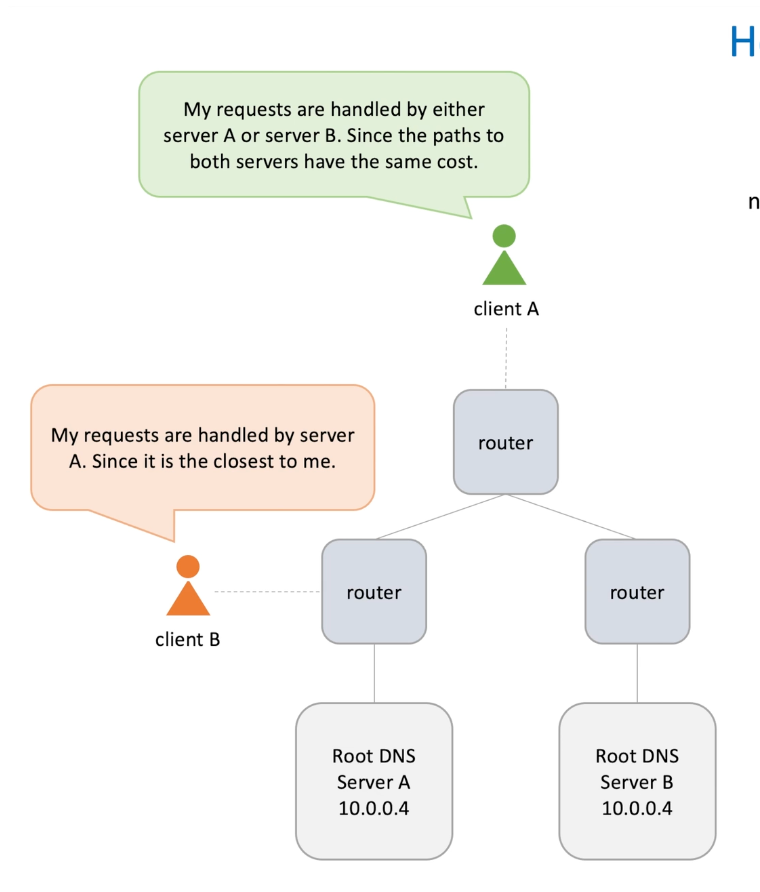
Anycast: network routing method
-
Typically a machine has an IP address ;
-
Anycast allows multiple host have the same IP address within a network
-
Routers in a network will select a single host in a group based on least-expensive routing strategy.
-
-
Pros
- Anycast provide high availability -> single machine down, others still work
- Anycast -> load balancing
- Widely used in DNS and CDN
- Help mitigate DDoS -> route request among serves
-
DNS records types
name type Value foo.example.com A 192.0.1.18 bar.example.com CNAME foo.example.com exaple.com TXT "some text"
Service Discovery
Server-side and client side discovery patterns
Service registry and its applications
-
In micro services, when all instances of service A wants to identify all instance and port of service B, how to find them?
-
Server side discovery : use reverse proxy or load balancer, they know all the information of service B, service A send request to load balance and it will forward the request to an available service B instance.
-
Client side discovery: service registry, service B sends all its instance info to the registry and instance in service A fetch the info from registry, then send request to service B;
-
Although DNS is like the service side discovery and can be used, it's not the best :
- Big cluster servers are added and removed quickly. Some may be unavailable ;
- DNS with its propagation delays and cache doesn't suit for big and dynamic clusters
-
Service registry in detail:
- Several server talk to each other(HTTP/TCP)
- Service instance needs to send heartbeat to registry
- If no heartbeat, it will be unretisgter
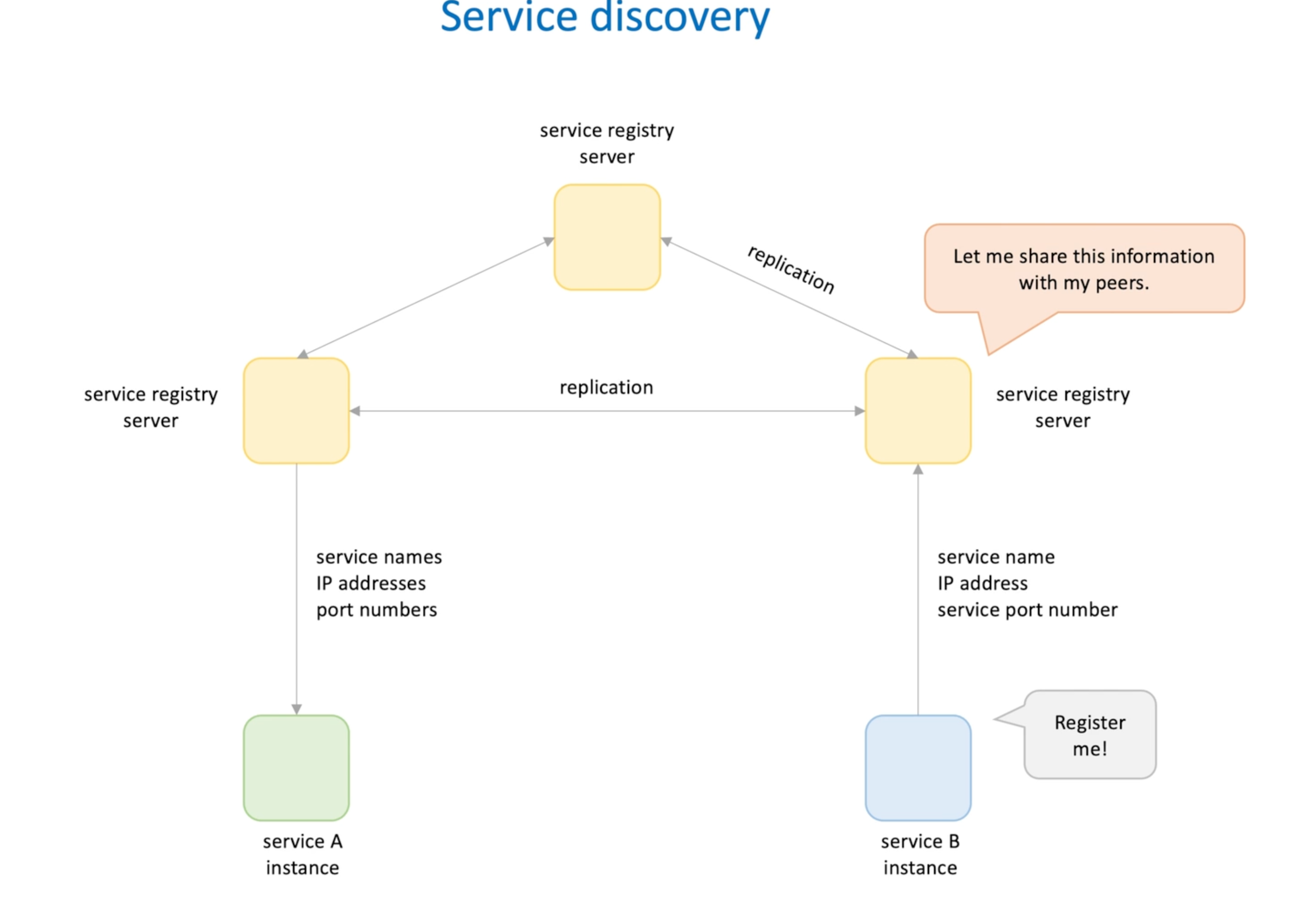
- Service A may cache registry data in case of service registry are not available and service A can still send request to B
-
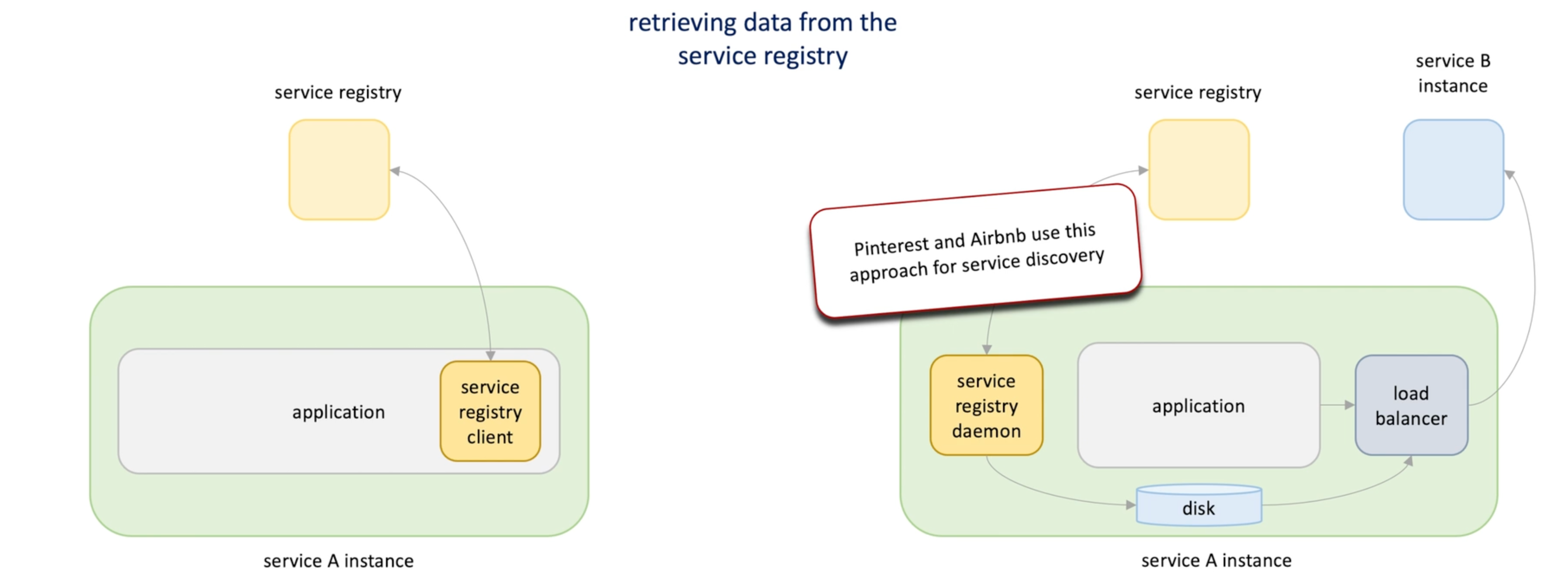
Implementation
- In application
- Pro: Implemented in the same language with application
- Cons Request a new client for every language
- Deamon thread
- Pro: Different programming language
- Pro: less error prone since daemon thread has its own memory and faults are isolated
- Cons: Harder to implement
- Pro: when more application in a single machine, we only need one registry (no need for each application, its information can be shared )
- In application
Peer Discovery
Peer discovery option
Membership and failure detection problems
Seed nodes
How gossip protocol works and its applications
-
How does service A and B find service registry ? And how does service registry know each other?
-
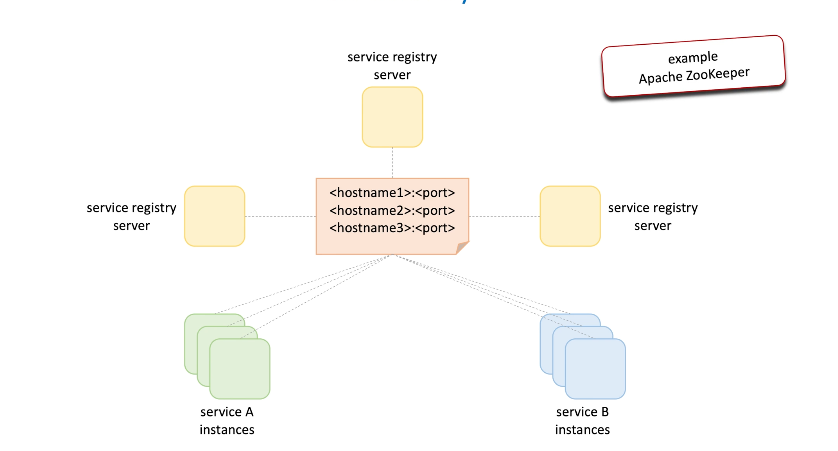
Option1: enumerate all the service registry info and share the info to other registry and service instances. -> Apache Zookeeper use this.
-
In the above option, Deploy this info list to a machine or upload to a shared database -> updating requires updates the list redeploy or re-upload
-
DNS -> TXT -> Netflix Eureka adopt this way.
-
Database -> gossip protocol -> as long as people are connected, info give to one person will be propagated to the network.
-
Use case for peer discovery
- Newly added machine can quickly identify other machines in the cluster
- Machines in the cluster quickly identify a failed machine ;
- Every machine knows the peers
- -> membership recognition and failure detection
-
Gossip algo
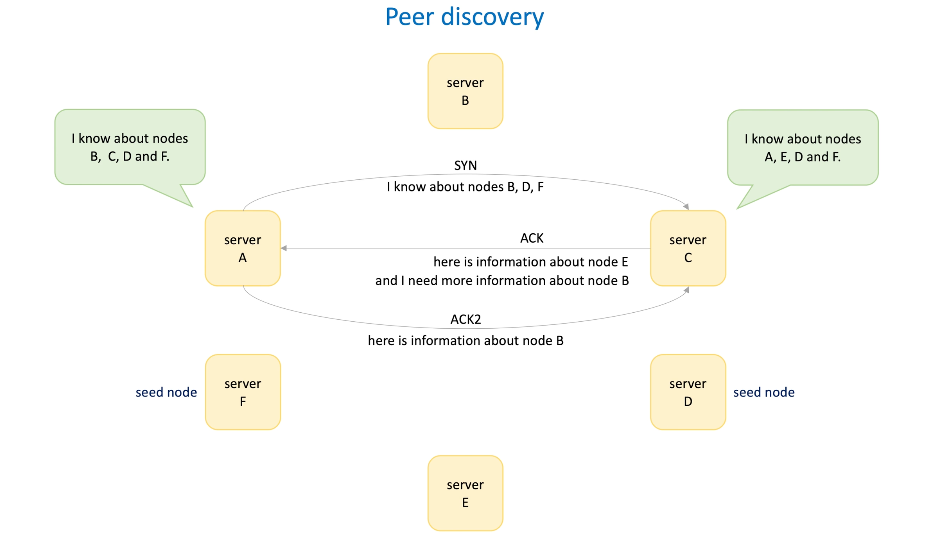
- Server A in the cluster
- Server B join the cluster, how do they know each other ?
- Server A is a seed who is known to all the others;
- Node B needs to somehow know the node A's info; -> a static file contains the list for hostnames of seed nodes; or DNS
- Node A and node B shared info to each other;
- Node C joined; the same pattern and node C and node A shared info to each other. -> node C will know B; -> B and C can start gossiping to each other;
-
Cassandra
-
How the cluster know other node is down? -> heartbeat counter -> an integer ; this heartbeat is send with messages -> nodes maintain a list of others heartbeat and time stamp(last update) -> check periodically, if no heartbeat for a while -> mark died -> will not gossip with this down node. -> but still take to the down node to see if it's back
-
Gossip protocal
- p2p
- Decentralized (no coordinator)
- Fault tolerant (some down don't affect the clsuter)
- Lightweight fast and efficient;
-
Gossip application
- Database (Riak, Cassandra, Dynamo)
- Service discovery system(Consul)
- Object storage (S3 spread info to the system)
- Distributed cache (Redis share info)
- Distributed rate limite
How to choose a network protocol
When and how to choose between TCP, UDP and HTTP network
-
we know how nodes find each other -> next we talk about how they talk to each other. -> network protocol
-
TCP:
-
Reliable and ordered
-
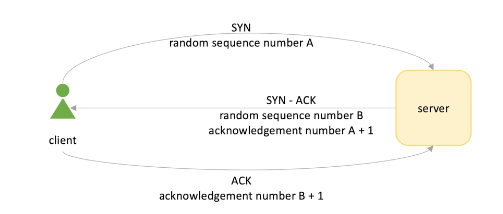
Connection oriented -> connection estabilished before transmit packages
-
3 steps handshake
-
Gossiping has similar pattern
-
Clients may establish multiple connections servers , TCP connections consumes resources(mainly memory) -> modern servers can handle hundreds of thousands simultaneous TCP connections. e.g. IoT ; but handling many request is not equal to handling many connections.
- Thread per connection
-
-
Fast and reliable -> speed matters and we need to avoid losing data.
-
-
HTTP: define how network message frame in client and reassemble in server
- HTTP/1.0: connection per request
- HTTP /1.1: persistent connections: multiple request in one connection ;
- TCP for security is not enough, in private network it's ok but in public network, arbitrary TCP traffic is not allowed.(direct TCP/UDP request) -> need HTTP
- A bit slower but reliable
- Good for public api
-
UDP: no connection, no handshake
- Fast not reliable -> data loss is tolerable
Network protocols in real-life systems
-
What network protocol should we use to publish messages to the messaging system and to retrieve messages?
Depends on the user, internal or external or both
- Public : HTTP -> AWS SQS, SNS, Kinesis ;
- Internal : TCP -> provide max throughput -> Kafka -> use a custom binary protocol over TCP
- Producers and consumers initiate socket connections to the broker machine and maintain these persistent connections ;
- We can access kaka clsuter from the internet
- Open TCP ports to the world;
- By some proxy tools
-
A microservice, called by client and other services -> protocol choose?
- HTTP for internal and public -> RESTful;
- If performance matters and it's private use -> TCP / UDP -> Thrift can do this.
-
Database
- If it'a public cloud database service -> HTTP -> DynamoDB
- More often -> database is not public accessible -> reliable and fast -> TCP -> Oracle , TCP/Cassandra
-
Database replication
- Reliable and performance matters -> TCP
- CouchDB -> HTTP (it's ok)
-
Gossip membership -> heartbeat / distributed cache problem / rate limiting (server talk to each other of the info)/ leader election -> what protocol
- Membership problem : TCP or UDP (gossip have many rounds)
- Distributed cache : TCP or UDP(some cache miss is fine)
- Rate limiting : both are fine(tcp slower but more accurate, udp fast but may under report request count...)
- Leader election: both are fine. Consider cluster size, if small they are both fine but fi it's big, TCP will cause more overhead due to connection establishments .
Videos over HTTP
Problem of media streaming
Adaption streaming
-
It depends : web browser / mobile ...
-
Mobile native application -> all three options are available -> libraries supported
-
Web browser -> all three options are available -> libraries supported
- webRPC : a collection of protocols and interfaces that enable communication of P2P . UDP by default, high quality
- WebSocket : TCP
- Adaptive streaming : HTTP
-
Older model :
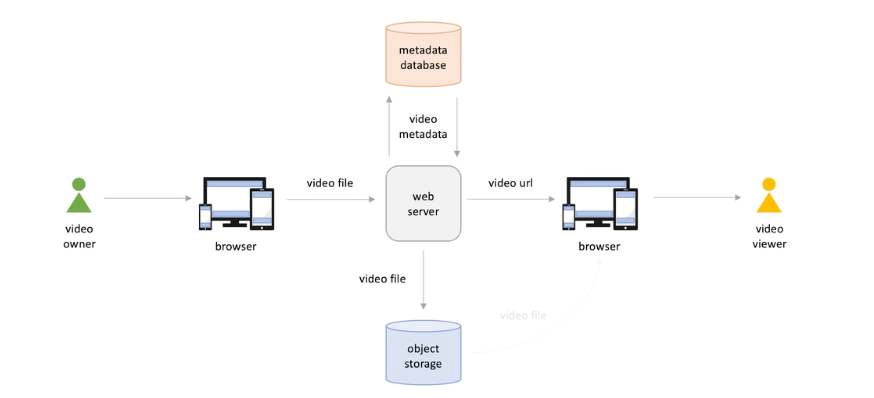
-
Better user experience: switch video quality / switch language -> this can't be done by this model
-
And network condition are not considered ; and if we want to support multi-language or video quality , we need to upload video files for each resolution and language combination -> can be mitigated by separate video files into chunks .
-
But we need re-download file each time user change the language or video resolution option.
-
Chunks -> each is a 2-10s segment.
-
Media player in browser (client) uses a bit rate adaption algorithm to select higher bit rate allowed; when network becomes bad, it select lower video quality segments ; when network is back good, higher video quality segments is downloaded.
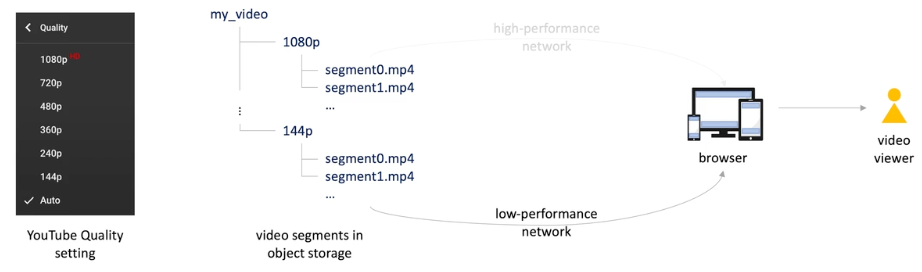
-
Same idea applies to the audio selection
-
Metadata file: index/manifest : For clients to know what video/audio qualities are available ->download first
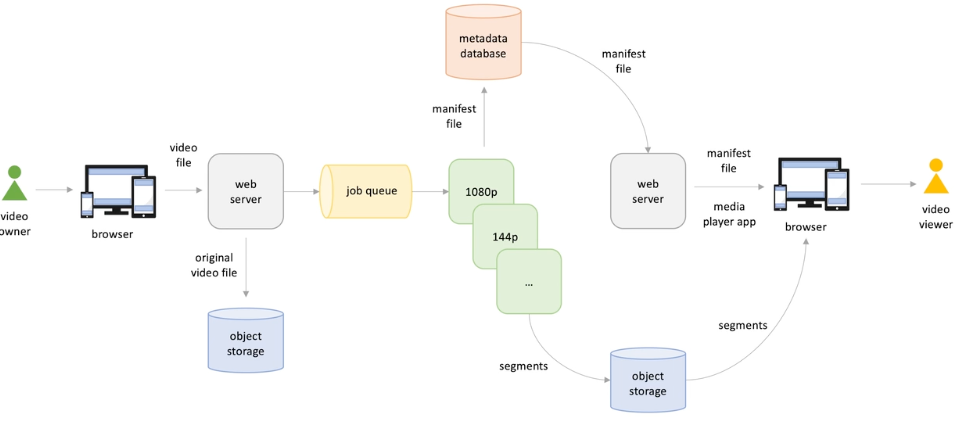
-
Live streaming can be same idea
- Uploader upload videos / live stream pushed -> files are persisted on storage
- At the same time many jobs triggered to generate segments for different quality / language
- These files are stored into storage , and index/manifest are stored in a separate database;
- When video viewer open browser and request a video, web server push a player app to browser ;
- Then get the manifest file downloaded; video in proper quality available are played (segments files are retrieved from storage)
CDN
How to use CDN
How CDN works
Point of presence(POP)
Benefits of CDN
-
Where and how store content? -> two to consider:
- Read latency for India, china, Europe user request(if the storage is in the US);
- Scalability: server capacity and network bandwidth for many request
-
Bring content closer to viewers , and replication and caching -> this solution is CDN.
-
CDN: distributed network of servers placed across the globe with the purpose of delivering web content to users as fast as possible.
-
How to use CDN:
-
Image upload to a application server;
-
Server register the image to CDN;
-
CDN returns the new URL to the service;
-
When user request to view the image, the new URL will be returned from the closest CDN server;
-
If there is no such recourse, the CDN will make a request to the original server; -> like a read thought cache mechanism -> this whole thing is called pull CDN.
-
Push CDN: content is pushed to CDN servers every time it is publish to the original server.
-
TTL needs to be configured ; (HTTP headers can help control it)
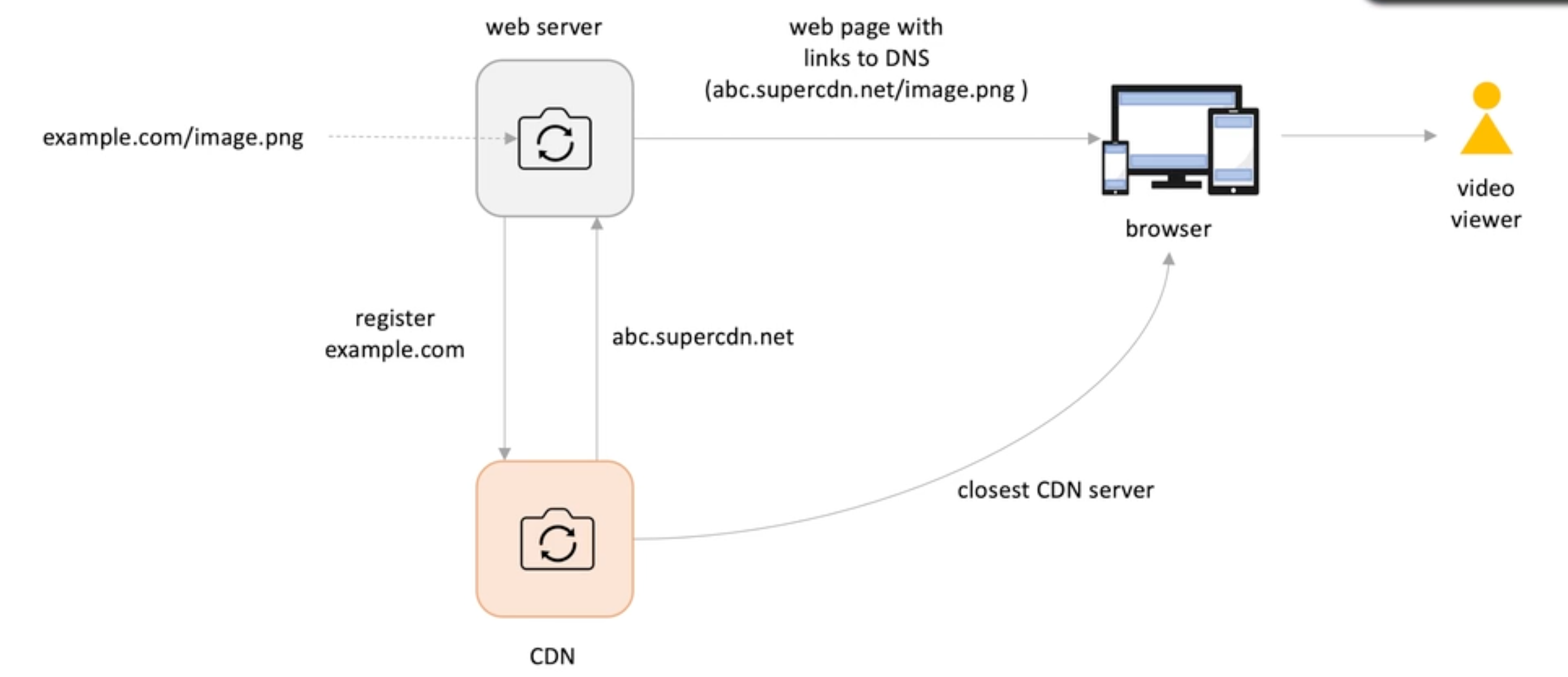
-
POP: point of presence, geographically located servers ; in each POP, two types of servers:
- Cache server: cache contents
- Request counting server: know all cache server in current POP
-
The request routing server address is registered to the ISP; ISP's DNS resolver will route to the closest POP-> how -> anycast -> then browser make a call to the content server;
-
When a POP is busy (unavailable)-> it may forward the request to others;
-
Video delivery -> update manifest to CDN urls
-
Benefits
- performance (low latency due to distance ) ;
- scalability (horizontally scalable POPs);
- reliability (duet data redundancy , failover to a different server or POP, load balancing) ;
- Anycast can allow load balancing to prevent DDoS.
-
Push and pull technologies
Short polling
Long polling
Websocket
Server-sent events
-
Short polling : client make calls to server and server response back whatever data it has;
- Will response none, one, or several messages
- Simple to understand and easy to implement
- Hard to define poll interval : on the one hand we want data pulled as fast as possible ; on the other hand, this will consume too much resources (mostly on the broker side, authentication, connection management , authorization, rate limiting , TSL termination, request validation ....)
-
Long polling: client make call to broker, if it has message it response, but if no messages, client wait broker, broker wait messages ... -> two possible things will happen: new message to the broker and message is send to the consumer; or no messages , broker send empty response to consume after a waiting time
- This value can be static file configured or
- Passed from broker
-
After a message is returned, consumer initiate a new request to broker;
-
How data is pushed from server:
- TCP bidirectional , but HTTP doesn't allow server use HTTP connection at his discretion;
- TCP send bidirectional byte stream data (not developer friendly)
-
Long polling is more suitable for messaging system
- Long polling reduces the number of empty responses;
-
Short polling if consumer wants immediate response -> e.g. consumer use single thread to poll multiple queues -> if long polling, this thread may wait for a queue if no messages -> others will be blocked even if they have messages -> best practice-> one thread per queue
-
Websocket
- Message based protocol
- Works over HTTP ports 8 and 443(secure port)
- Reuse TCP connection initially established for an HTTP request
- Major browser and web server supported
-
Everything starts from client with a addition header field : Upgrade: websocket , if server support , it will response with this field , once the handshake established on the initial TCP connection, they can send message via websocket
- Fast
- Bi-directional
- Natively supported by browser
- Alternative of TCP when TCP is not available for security reasons.
-
Server-push : some time we don't need bi-directional->e.g. server push notification to client
-
Workstream
- Client send a mail request
- Server response a JS code to establish a persistent HTTP connection (connection: keep-alive);
- Server check new mails, and response back to client each time new mail comes;
- If connection drops, client will try to re-connect
- Message data is string , message can send JSON/XML data format
-
Pros and cons
- Pro: simplicity (easy to implement in client and server); Server Sent Events are sent over HTTP(no need a custom protocol)
- Con: mono directional (server ->client ); limit to text data(UTF-8)(no binary data); limit number of connections a single browser can have.
Push and pull technologies in real life systems
What tech would you choose for various system design
-
Warm up
Techs Push/Pull Short/long Notes AWS SQS Pull Both normally use long polling to eliminate empty response Apache Kafka Pull Short and long likewise 1. Use a proxy to accept HTTP request , 2. and proxy talk to Kafka over TCP Make consumer fetch often(short polling like) ; or wait until more messages come (long polling like) AWS Kinesis pull(HTTP) Short(wise) receive a batch message, process them and make a call to the next patch; if no message, client sleep one second RabbitMQ Push websocket Apache ActiveMQ Push websocket -
Choose in real cases
-
App Solution Reasons Realtime chat Websocket
long polling with HTTP from client
Server push with HTTP from clientBidirectional communication, reliable; But can be achieved by long polling(support older version browser); server push with HTTP response (easy to implement) News feed Websocket
long polling
short polling
server pushStock price Websocket
server send eventHigh frequency message with small payload, long/short polling is not good here due to the message header is big compared to the message content itself Browser game Websocket Collaborative editor Websocket
long polling with HTTP from client
Server sent eventsThey can achieve but some are not suitable . For example, we can push notifications clients using websocket but if we don't have client send back message, we can use SSE.
-
Always consider pros and cons, try to simplify things and avoid over engineering.
Large-scale push architectures
C10K and C10M problems
Examples of large scale push architectures
The most noticeable problems of handling long-lived connections at large scale
-
From server perspective, handling thousands connections may be an issue -> C10K: how many concurrent connections a single server can handle. -> solved
-
C10M: handle 10M concurrent connections on a single machine -> solved
-
Handling millions of concurrent request not equals to handling millions of concurrent connections.
- Handling millions of concurrent request is about speed of processing;
- Handling millions of concurrent connections is about efficient scheduling connections. -> impossible now
-
Mail.Ru architecture
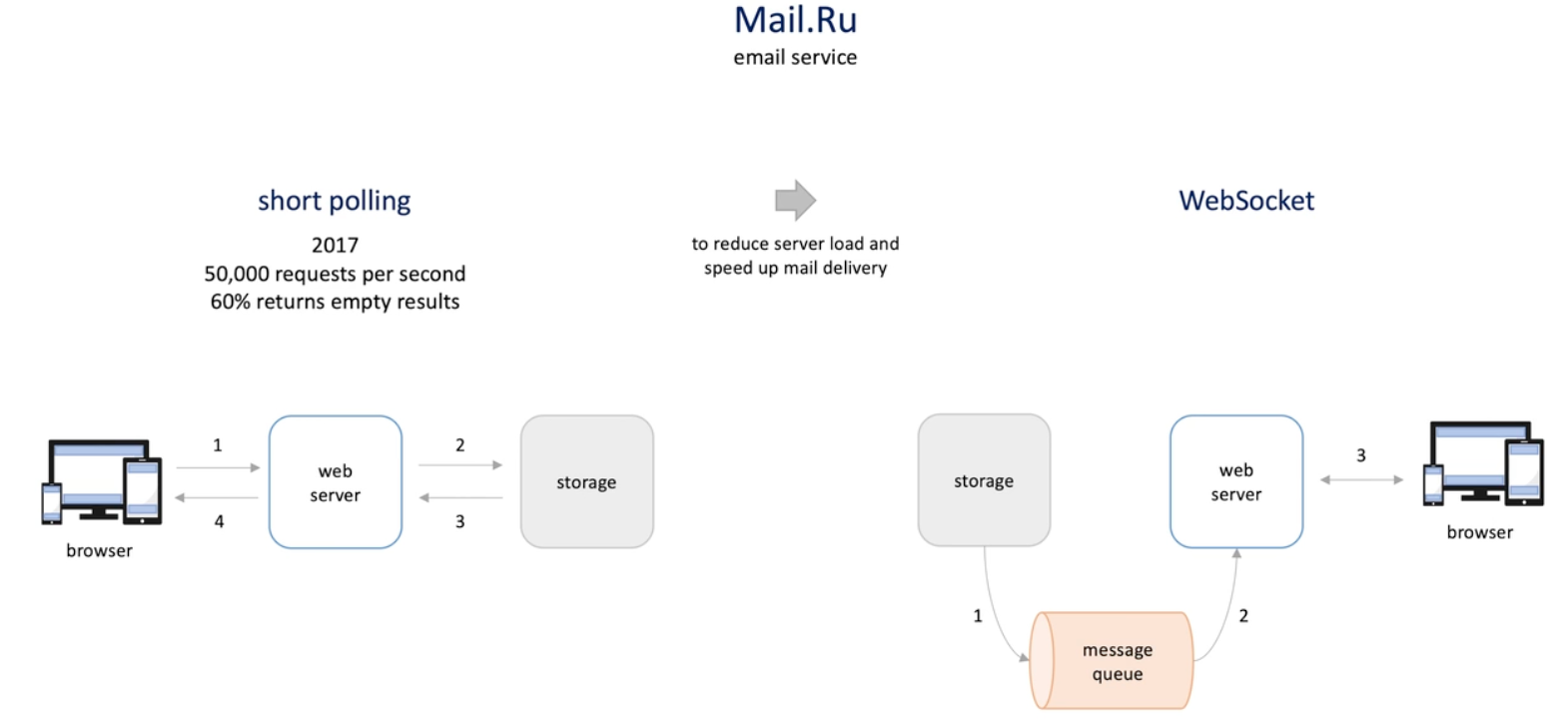
- First use short polling -> 60% return empty response
- Browser makes HTTp request every few seconds;
- Server make call to the storage often;
- The websocket
- Broswer establishe a connection to server;
- When there is new messages, they are pushed to a queue from storage;
- The server gets email , it send message to users browser ;
- First use short polling -> 60% return empty response
-
Netflix (streaming service)
- Every thing starts from the API gateway(zuul), performa authentication and authorization, logging and monitoring; request routing and load balancing, rating limiting and load shedding..., support push messaging(websocket and server push event )
- Use open Netflix app; a persistent connection is establish to an Zuul server;
- After successful authentication, serve register the users in push registry(Cassandra, DynamoDB, Redis), who store information about which server is connected which Zuul server; -> to push message to right client
- Message producers(backend services) send messages to message queue service(Kafka); message with ID for who to send the message
- Then Kafka then send message to processor, and processor looks for client user in the push registry;
- If found, mean user app still connected to the API gateway server Zuul, then message processor connect directly to the zuul server and pass message to it
- Server push message to user ;
- If not found, (user not connected anymore), the message is dropped.
-
Single zuul server can handle tents of thousands connections; a cluster of such servers can handle millions of connections.
-
Push Registry -> use highly available store -> low latency
- The write happens when app connected to zuul server(once), and read happens for each message (more reads)
-
Kafka high scalable
-
Message processor : many instances in parallel -> auto scaling ->Netflix runs in cloud -> cost saving
-
Handling long lived connections of millions connections is a challenge:
- Blocking I/O :Thread per connect is poorly scalable, -> non blocking I/O is better -> zuul is based on Netty(non blocking )
- Server restarts -> we can force clients to reconnect to a different server or migration connections without reconnecting clients -> avoid thundering herd problem(when many clients try to establish new connection at the time) -> slower shutdown, not all at once
- Server failure : many small serve is better then one small server -> clients will try to connect to others, if one big serve is down, many clients will try to connect others at the same time-> hard for system
- Older load balancer versions cut WebSocket connections : connection s are cut after some time periods inactivity ; newer version can support this by adding proxy natively. Or another option is to run a TCP load balancer at layer 4 instead of as an HTTP LB at layer7