Deliver data reliably
What else to know to build reliable, scalable and fast systems?
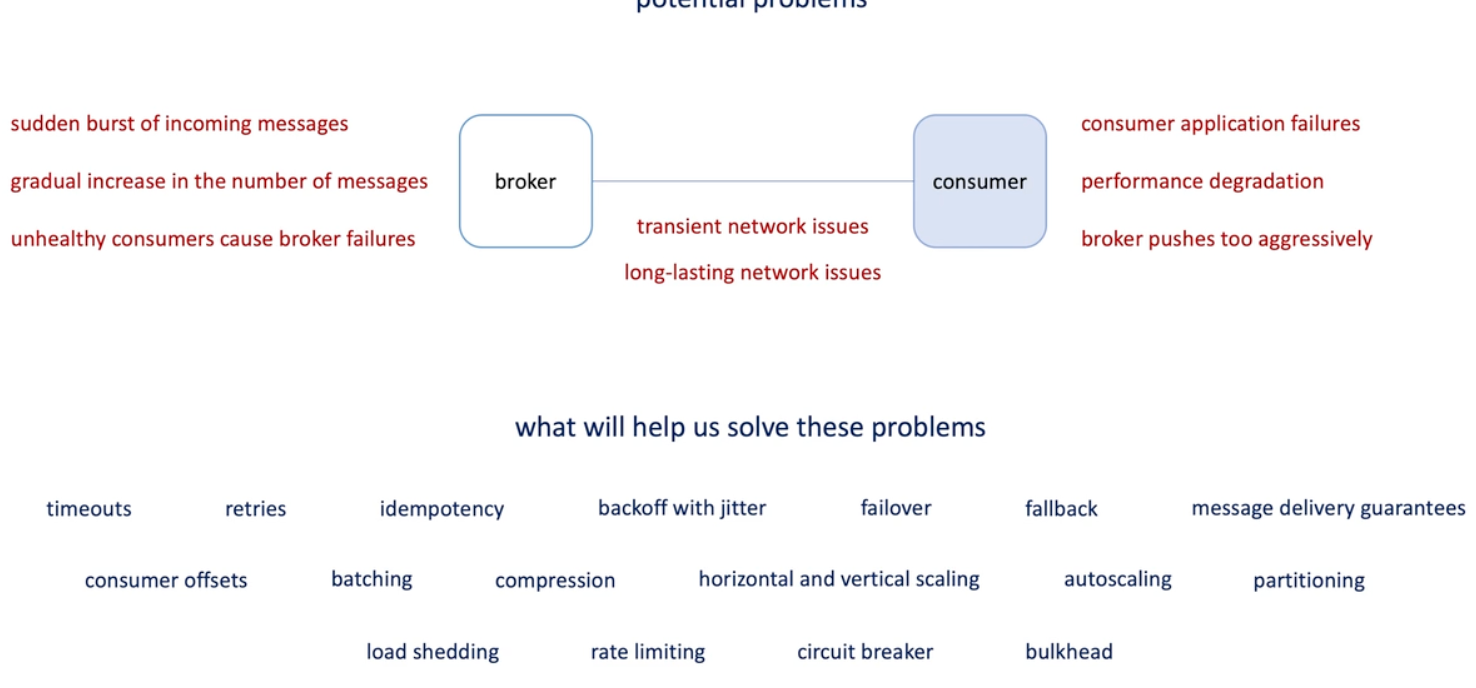
List of common problems of distributed system
List of system design concepts that can help solve these problems
Three-tier architecture
-
Problems in distributed systems
-
Transient network issues
-
Long lasting network use
-
Consumer application failures-> broker may keep the messages for a while until its disk is full;
- Timeout, reties, idempotency, backoff with jitter, failover fallback, message delivery guarantees, consumer offsets
-
If messages comes faster than then speed of consumer can process them due to -> traffic burst, or natural growth of load -> in such case, we will need to increate the throughout or reducing the latency:
- Batching, compression, scaling, partition
-
Load shedding, rate limiting...
-
Circular breaker and bulkhead when some consumers failures
-
Three tier architecture:
- Representation tier: displaying data
- Application tier: business logic (functionality)
- Data tier:data persistence
-
Request failed to pass through tier ? One tier becomes slow? ....
-
Timeouts
Fast failures and slow failures
Connection and request timeouts
- Everything eventually fails;
- Fast failure : we know failure fast
- Slow failure: we don't know failure immediately and we see it;'s still working -> occupy resources;
- So we use timeouts to turn slow failures into fast failure
- Timeout : how much time the client is willing to wait for a response from the server
- Connection timeout : how much time to wait for a connection to establish (10-100ms)
- Request timeout: time to wait for a request to complete
- Trick to choose timeout -> analyze metrics (percentile) and set a p99
What do we do with failed requests ?
Strategies for handling failed requests(cancel, retry, failover fallback)
-
Cancel : when a request failed, it cancel this request , and may send an exception out. (Try, fail, log) -> this is useful when the failure is not transient(resend is not useful-> auth fail)
-
Retry : when a request failed, it will resend the same request again. -> use when the failure is transient( network issue).
-
Failover : switch to a redundancy or standby system of the same type.
-
Database :
-
Load balancers
-
Leader and followes
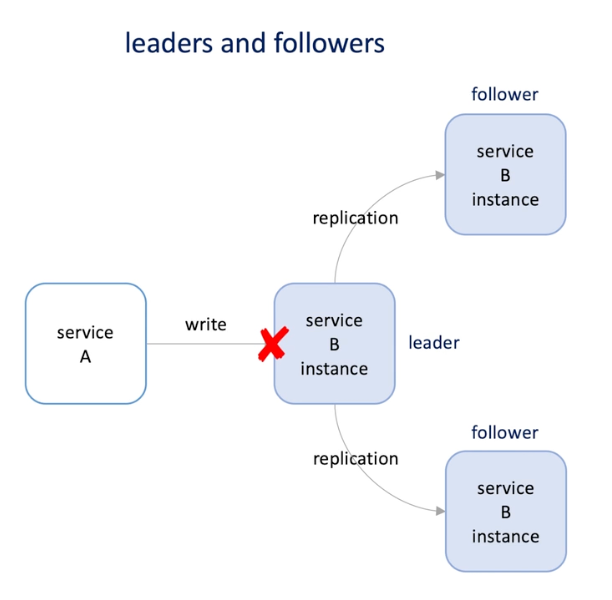
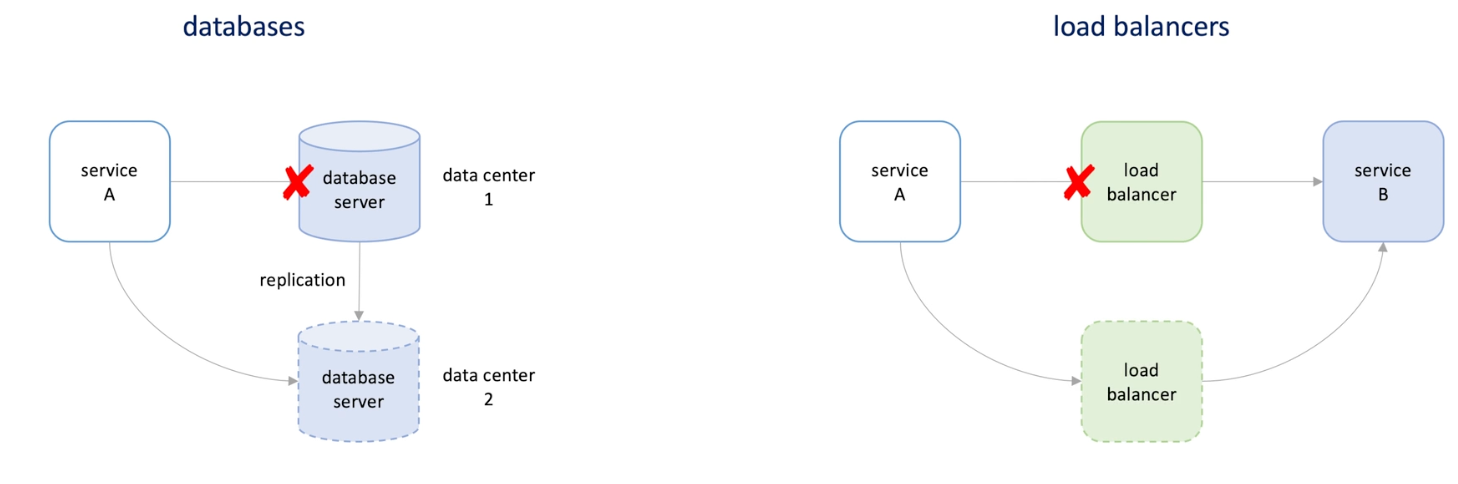
-
-
Failover in microservice
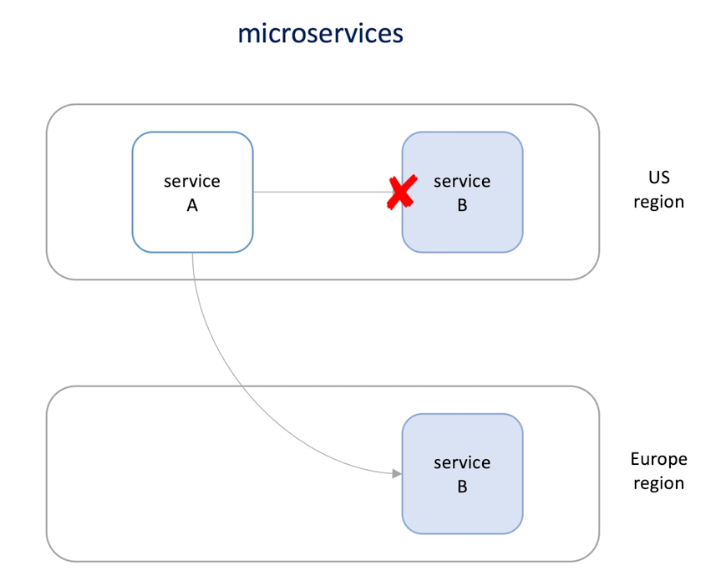
-
Fallback : switch to an alternative system (of a different type)
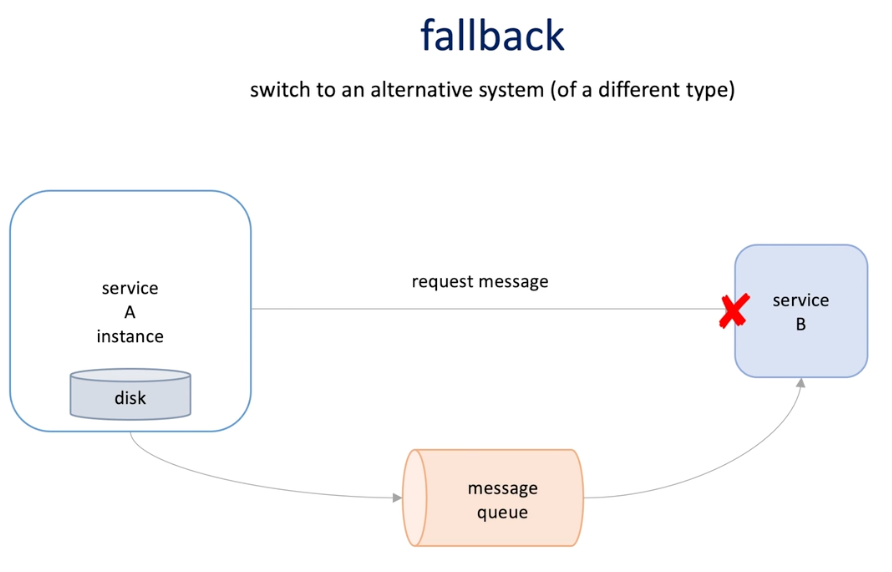
- Message queue is totally different type of service B
-
Fallback increase reliability but also the system complexity
- -> introduce new components
- Hard to test
- Fallback system rarely used may not be ready to handle the failed request
-
Those can be used combined : when a request failed, we retry 3 times and if still fails, we use failover or fallback path.
When to retry
Idempotency
Quiz: which AWS API failures are safe to retry
-
Idempotency : no matter how many times the operation is preformed, the result is always the same .
- X = 5 is idempotent
- x++ is not ;
-
Idenpetent API : making multiple identical requests to that api has the same effect as making a single request
- READ is typically idempotent
- Write is typically not (create a new record) (what about put update?)
-
Can we retry a non-idempotent API? -> yes, if you know
- Original request never hit the API (do nothing on server side)
- API supports idempotency kets(client tokens )
- Service A send request with tokens to service B;
- If service receives request and processed, stores token;
- When A sent the retry request, B find it's duplication, do nothing with the request;
- If the request if failed , means no record of token in B;
- When retry, the request will be accepted and processed
-
This is applied to some temporary storage -> has a TTL of idempotency key
-
How do we know an API is idempotent -> service provider tells us developer
-
HTTP Status Code Description Retry? Comments N/A Network is not established yes Request never send before 400 Bad request No Request bad, retry no help 403 Access denied No Credential not right 404 Not found exception no No requested resources 429 Too many request Yes with delay Too many request in a periods of time. so wait for a bit 500 Internal server error Yes if idempotent Internal unexpected error 503 Service unavailable yes Service is not available, request not hit server 504 Request timeout Yes of idempotent Request hit server but couldn't complete with the timeout periods
How to retry
-
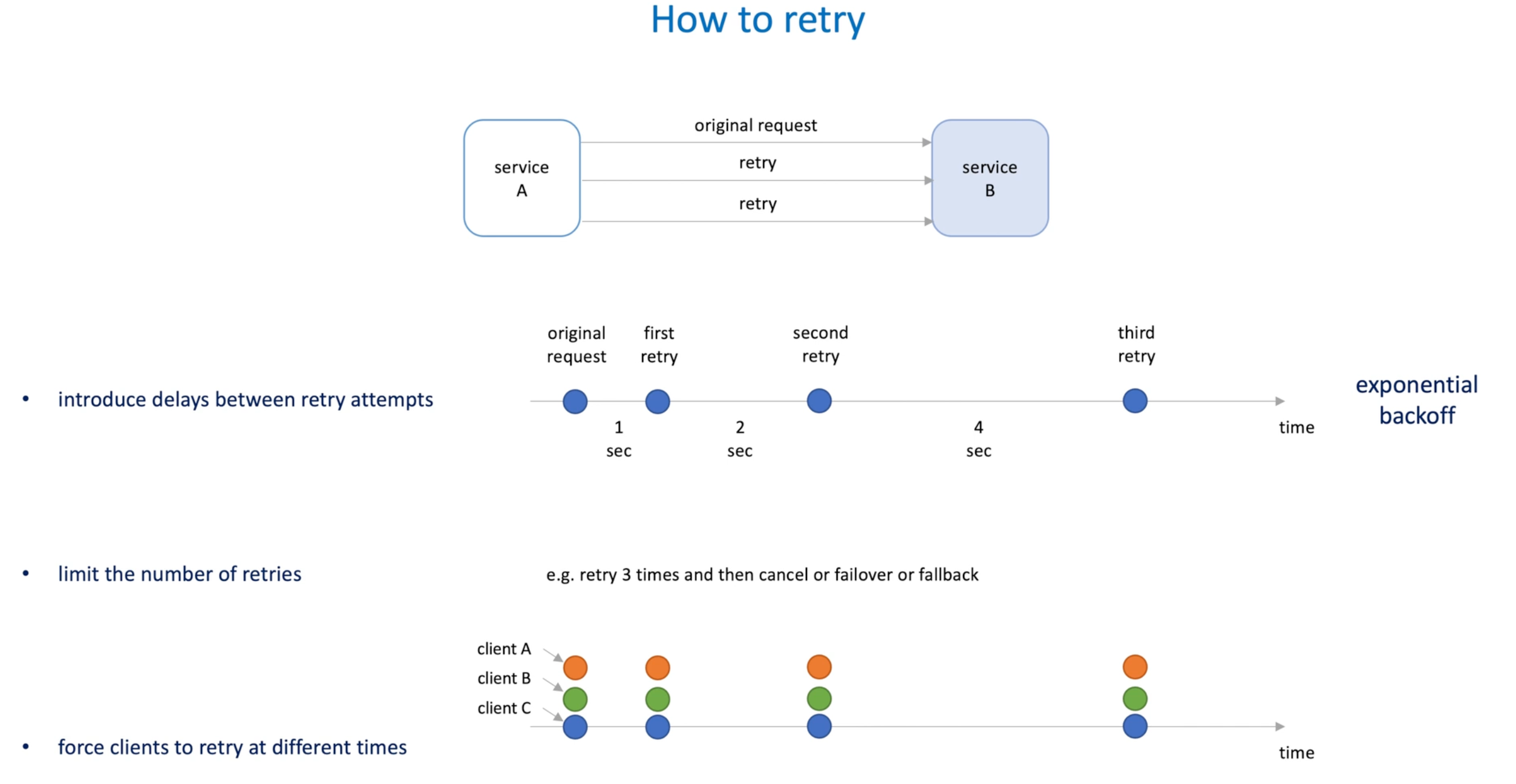
If service B is under pressure, retry will make it worse -> retry storm
-
Introduce delays between retry attempts ; And the delay(wait time) increase after each retry (exponential backoff)
-
Limit the number of retries -> failover falloff after several retries
-
Retry from different clients at the same time will cause pressure to the server -> Force clients tore retry at a different times -> Jitter(random intervals)
-
-
Jitter
- Easy to implement

-
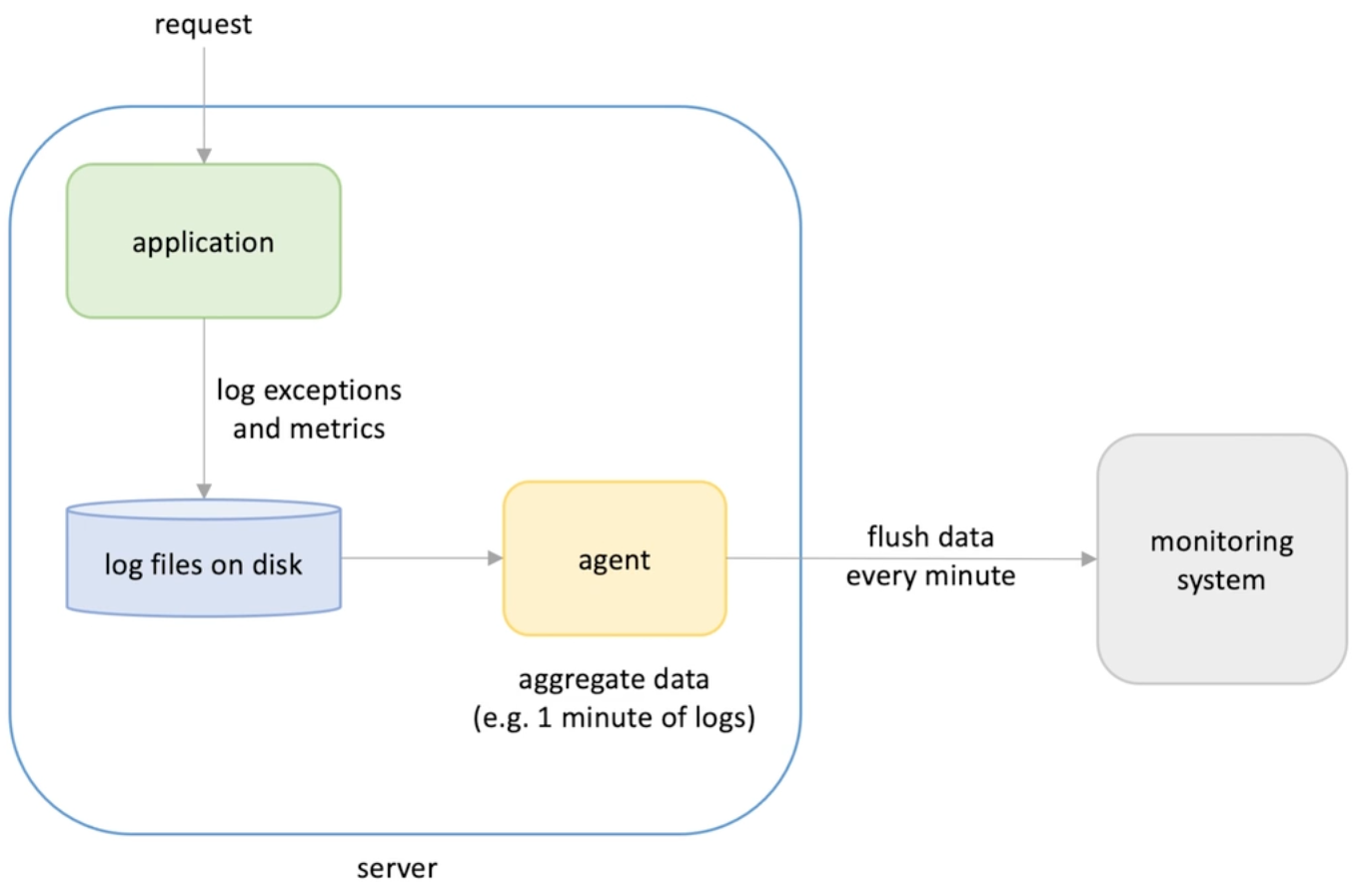
Data aggregation scenarios : application monitoring : if the metrics send monitoring data at the minute start , this will cause load pressure to the monitoring system -> jitter :
-
In general : aggregate in time series and flush to system , workload that run periodically
-
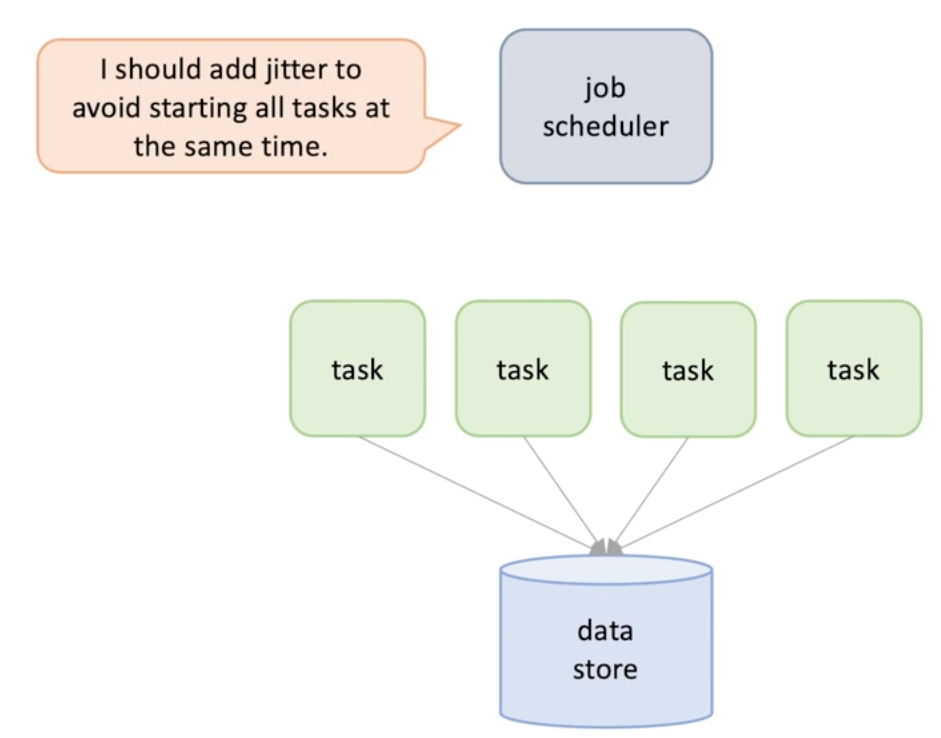
Use jitter to avoid start8ing all the tasks exactly at the same time
-
-
Jitter can also help resource competing after they were waiting for a event
Message delivery guarantees
At most once guarantee
At left once guarantee
Exactly once once guarantee
- Push : when broker send message to consumer, it waits for the ack to comeback , if the broker was unable to deliver the message or the ack didn't come back , the broker may retry immediately or fallback
- Fallback option -> dead letter queue to contains poison pills(message send failed )
- Pull : consume send pull request, if fails ,retry, after consumer receive the message it will send a deletion message and the broker delete the message(ack);
- Completing consumers : speed up processing
- Push: broker randomly select one consumer and send message, if failed, it will retry, and if still fails, it will select another consumer to send the message(failover)
- Pull: all consumers are pulling messages, if one consumer receiving the messages, others should be invisible to pull this message -> SWA SQS
- Visibility timeout -> the message cannot be processed; enough for one consumer to process one message
- Message delivery guarantee
- At most once: message will never be delivered over once; we try, We failed and we we give up... -> message might be lost
- At least once: best effort : retry the message until it's delivered. -> messages might be delivered multiple times.
- Exactly once: message will be delivered, or proceed exactly once.
- Why we have these guarantees? Isn't exactly once is what we want?
- Failuers will happen -> the ways of the failures were handled determinate the guarantee.
- Broker don't care about the message delivered, it sends the message and regard it's successfully delivered.->message may be lost -> at most once -> throughput good but message safety bad.
- Broker wait for the message ack to come back-> at least once-> consumer may get the message multiple times. -> ack will be send back to broker only after the message processed.
- If the ack send back before the message was processed, if processing failed, the message was deleted (due to receiving of ack), thus now way to process again.
- Exactly once: Kafka, SQS FIFO queue;
- Rely on either idempotency or distributed transaction to achieve exactly-once semantics.
- If rely on idempotency, both broker and consumer should be idempotent : broker to detect and eliminate duplicate messages when they are published; consumer to avoid processing message more than once.
- Hard to build such system in practice, most are at least once.
- Rely on either idempotency or distributed transaction to achieve exactly-once semantics.
Consumer offsets
Log-based messaging system
Checkpointing
- Two ways of processing messages
- Take message from head of the queue;
- Consumer process,
- Delete from head when its processed ;
- Second way is :
- Retrieve message from any position in the queue
- Consumer retrive message form position 0,
- Consumer process, but not deleted the message immediately after processing;
- It move the index to next one ;
- Broker is busy for the first option: ActiveMQ, RabbitMQ, SQS
- track status for every consumer
- Make message processed
- Wait for the ack
- Broker is free : Kafka -> Better performance due to this
- Receive the position of message requested and return the message(this position is maintained by the consumers)
- Option 2
- Messages are stored in both memory and disk(cheap and large)
- Messages saved in segments , a segment is deleted when all messages in it are processed
- Broker sign a increasing sequence number to message , identify message in segments
- Message system follow this approach are referred as log based messaging system.
- Consumer persist the offset (where and how up to consumer)
- This process persisting the offset is called checkpointing. -> this offset is write often and read less often -> this offset is used to rewind of find the right position to process message when there is a bug...
- Kenises -> DynamoDB, Kafka-> Zookeeper(but not good at high load writes so now offsets are stored in broker.)
- Checkpointing for guarantee -
- Checkpoint after message processed -> checkpointing may be fail-> at least once
- Checkpoint before the message processed -> if processing fail, we lose message -> at most one
- Option 1 is reliable and option2 is more reliable because in option2, all message are still there even something happens