Reinforce the understanding of frequently used system design concepts and to demonstrate how to apply them to solve problems.
How to Define System Requirements
System Requirements
-
What a functional requirement and non-functional requirements
-
Functional requirement: defines the behavior, what a system us is supposed to do; e.g. the system must allow applications to exchange messages
-
Nonfunctional requirements: defines the quality of a system, how a system is supposed to be. e.g. scalable, highly available, fast
-
-
Why they are important
- Interviewer tends to make the problems vague and wants to see how candidates approach them. And non functional requirements can help us guide to correct direction when there is open ended questions.
- Day to day work on technical design.
-
An example of the thinking process should be when design a scalable, highly available and fast message queue:
- Let's start with scalability requirement -> Do we need to scale for reads or writes? -> probably both since the message will be written and consumed
- To scale writes -> partition messages in multiple queues; -> partition strategy ? Hash?
- Where to store the messages? Memory or disk? -> if disk, append only log or embed database -> if database, B-tree or LSM-tree database? LSM tree based since they are faster for writes.
- Partition will help scalable reads as well since we will have consumes for each partition.
- Read: Should I choose push or pull for reading? If pull, system might want to do the long pull to decrease the # of read request.
- High availability -> replicate message -> lead base or leaderless -> mist likely leader based-> leader selection -> a coordination service or a database that ensure strong consistency.
- Reliable - > protection -> rat limiting or load shedding
- shuffle sharding ?
- Reverse proxy?
- Batching and compress message to make it fast
- Internal net -> use TCP rather HTTP maybe .
- Let's start with scalability requirement -> Do we need to scale for reads or writes? -> probably both since the message will be written and consumed
Functional requirements
- How to define functional requirements
- Define who is using this system and how
- System we easily know user: Gmail, YouTube...
- Hard to know -> rate limiting system, fraud prevention system, CDN..., challenging to know the input and output.
- How to start with unclear user/usage: Start with a user(people/devices/...) and work backwards
- Backwards: Once you define the user you know how they use the system(behavbious) .
- e.g. Youtube: creators and viewers(users)
- Creators upload, edit,... videos more;(how)
- Viewers watch, likes, comments videos more.(how)
- Some times clear requirements and we are required to do API definition(REST/RPC guidelines) :
- Upload a video to the channel ->
POST /channels/{channel_id}/videos - Return a list of videos for the channel, ordered by popularity ->
GET /channels/{channel_id}/videos?sort_by=view_desc - Search for videos and channels ->
GET /search?q={keywords} - Watch the specific video ->
GET /videos/id={video_id} - Delete the specific video ->
DELETE /videos/id={video_id}
- Upload a video to the channel ->
- Define who is using this system and how
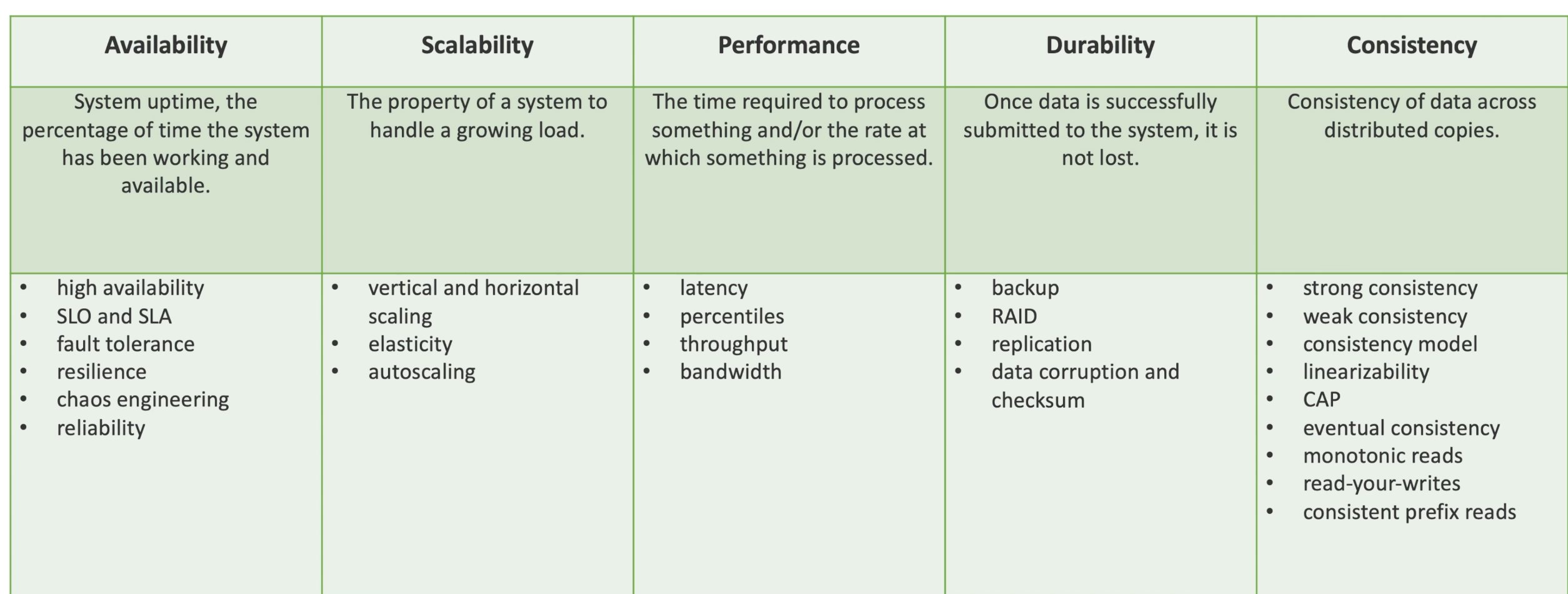
High Availability
-
Time-based and count-based availability(What)
- Time-based : Uptime , the percentage of time the system has been working and available.
- Count-based: Success ration of number of request.
100% availability is impossible in reality; It's not about the number of time or successful request number, it's the process and architecture(high available).
-
Design principles behind high availability
- Build redundancy to eliminate single points of failure(regions, availability zone, fallback, data replication, high availability pair...)
- Switch from one server to another with our losing data(DNS, load balancing, reverse proxy, API gateway, peer discovery, service discovery...)
- Protect the system from atypical client behavior(load shedding, rate limiting, shuffle sharing, cell-based architecture...)
- Protect system from failures and performance degradation of its dependencies(timeouts, circuit breaker, retries, bulkhead, idempotency, ...)
- Detect failures as they occur(monitoring at all levels,...)
-
Process behind high availability (How)
- Change management: All code and configuration changes are reviewed and approved
- QA process: regularly exercise tests to validate that newly introduced changes meet functional and non-functional requirements
- Deployment: deploy changes to a production environment frequently, quickly, safely; automatically rollback.
- Capacity planning: monitor system utilization and add resources to meet growing demand.
- Disaster recovery: recover system quickly in the event of disaster; regularly test failover to disaster recovery.
- Root cause analysis: establish the root cause of the failure and identify preventive measures.
- Operational readiness review: evaluate system's operational state and identify gaps in operation; define actions to remediate risks.
- Game day: simulate a failure or event and test the system and team response.
- Team culture: good culture promotes process discipline.
-
SLO & SLA
- Service level objective : availability goal.
- Service level agreement: the agreement of the availability goal.
Fault tolerance, resilience, reliability
-
Fault tolerance = high availability ?
- Fault tolerance: (from Wiki): fault tolerance is the property that enables a system to continue operating properly in the event of one or more faults within some of its components.
- Fault: produced by system or engineer.
- Fault tolerance system's goal is to zero downtime.
- High available system is it accept the downtime and to try to minimize the downtime (no 100% availability)
- Fault tolerance is a higher level availability.(more redundancy and cost as well).
- Fault tolerance: (from Wiki): fault tolerance is the property that enables a system to continue operating properly in the event of one or more faults within some of its components.
-
Error, fault, failure
- Error: developer write program introduced error, this will lead to bugs(faults)-> one or several faults results in a system failure , failure is the inability of a system to perform the required function.
- Resilience almost equals fault tolerance.
- Game day vs Chaos engineering
- Game day helps team to response quickly and properly; (team behavior)
- Chaos engineering is like randomly killing a server to test the system ability of deal with this situation automatically. (System behavior)
- Reliability = high availability + correctness + time
- Correctness: system returns the correct result
- Time: system replies back in time
- Reliability vs high availability vs fault tolerance vs resilience
- Reliability: system always perform properly and in time
- high availability : small downtime
- fault tolerance : close to zero downtime
- Resilience: quickly recovery from failures.
- Expected and unexpected failures
- Reliability and high availability: system can handle expected failures:
- Server crash
- Power outrage
- Network problem
- Fault tolerance: system know how to handle unexpected issue quickly:
- Load spike
- Dependency failures
- Reliability and high availability: system can handle expected failures:
Scalability
- Ability to handle growing load (# of requests, volume of incoming/outgoing data/# of concurrent connection...)
- Vertical scaling : more powerful machine; simple but with machine become powerful, it become expensive as well, what's more, the ability is limited.
- Horizontal scaling : more machines; unlimited potential, but system become complicated,
- Service discovery, request find all the machine
- Load balance evenly
- Request counting(requirement that same request to same machine to maintain state)
- Maintenance of multiple machines
- Relational Database: single db -> scale up to a limit -> sharding to scale writes and replication to scale reads...
- Trade off , don't assume horizontal scaling -> clarify requirement
- Horizontal and vertical scaling can be used conjunction -> keep # of machine small -> upgrade machines -> become expensive at some point -> scale horizontal
- Elasticity : the ability of a system to acquire resource when needed and release then when it no longer needs them.
- Compare with scalability -> elasticity is short-term, tactical needs while scalability is long term and strategitic needs.
- A service has higher volume of request at day time so it may use more machines -> elasticity ;
- The service/business become popular over time and overall request volume are multiple times, the system or machines needs to be scaled -> scalability.
- Scalability can be automatic -> autoscale ; vs manually
Performance
- Time required to process something(latency) or the rate to which something is processed(throughput) ;(net disk download rate 10M/s or download 100M files in 5 sec);
- Response time: network delay + server process time
- Latency : can be network delay or server process time or can be response time.
- Networks : protocols \OSI models
- Serverside latent: water also, men vs disk, load cache, thread poll and parallel processing...
- Client-side : blocking vs non-blocking IO, message format , data compression, CDN, external cache...
- Average latency
- Percentiles: P99, P75, P50.... # of requests processed using contain time
- What's the goal of reduce latency ?
- Commitment to customer (SLO/SLA)
- Throughput (rate)
- Decrease latency
- Scale system
- File transfer -> chunk file -> sender to many workers (MapReduce) batch processing;
- Message queue- -> more consumer -> or even more queues
- Increase write throughput : sharing(partitioning) -> write different part to different database partition;
- Increase read throughput : replication -> replicate data
- Bandwidth: max rate of data transfer across a given path (bps)
- Increate network transfer thought put may needs to increate bandwidth .
Durability
- Once data is successfully submitted to the system, it's not lost, even fault occurs.
- How to achieve? -? copy data redundancy
- Backup: copy data from a non-volatile storage(disk) periodically.
- Full : store full copy of data at each backup. It has short restoration time but the backup time make be long;
- Differential backup: only save the difference in data since last backup. Smaller size, shorter creation time but longer restoration time compared to full backup.
- Incremental backup: the backup contains the change since preceding backup. Smaller size and short create time but longer restoration time (complex restoration process)
- Data change and backup has gap, some data may not be back up; and data restoration takes time and new drive(data is not available!).
- RAID(redundant array of independent disks): combination of multiple physical disks into one logic unit.
- From app perspective, it looks like a single device. (Internal disk redundancy);
- Also increate performance because it allows multiple read and write at the same time. -> RAID 1
- RAID 0: no replication and like sharding, separate block into different unit-> increate performance .
- Replication
- Server and application and storage are all duplicated - > they sync the writes to each other.
- Increase availability
- Cassandra: replication can help durability but RAID can provide additional protection.
- Other ways provide durability :
- versioning: like back up but store specific objects not all
- Safeguard agains accidental deletion ....
- It's not only about copy data , we also need to ensure copies are not corrupted and stay healthy.
- Regularly check may needed: checksum: when storing data calculate checksum, and when retrieving, calculate checksum and compare. If failed, create copy from other clean copy and remove corrupted data.(->HDFS)
- What's the durability goal?
- Availability -> system up time -> can I access my data now?
- Durability -> data storing without losing -> will I fetch my data in the future.
Consistency
- C in ACID: database (relational) transactions don'y violates data consistency.
- E in BASE(no SQL database) / tunable consistency/ CAP: E stands for eventually consistency.
- Single database can handle traffic in the old days; read and writes and simple and consistent
- Nowadays, replication is needed for better scalability. (Also better availability and durability)
- System always return single (most recent) data to customer -> strong consistency
- May return some outdated in a certain time periods -> weak consistency
- Consistency model: Rules of consistency levels, which defines the order of updates in the system and when these updates are visible
- Linearizability : strongest consistent can be implemented in practice : after the update completes, all clients when they read data , het back the updated values. (Strict consistency is the most strong consistency only exists in theory)
- Typical usage: banking, e-commerce, booking system distributed locks
- It's slow
- C in CAP stands for linearizability; we only need to choose between consistency and availability in case of a network partition.
- Eventual consistency : if there is no additional updates made to the object, eventually all reads will return the latest written value of that object.
- Inconsistency window is typically small (sub-second)
- Can be much faster than lineraizability (no need to finish sync immediately )
- No need to sacrifice availability
- DNS is the most popular example
- Eventual consistent may cause confusion :
- You left a comment after refresh , you read from another replica that hasn't sync the comment, you see no comment.
- You reply a comment to a previous one for explaining. You refresh page and don't find the comment -> the reason is you comment has't approbate to all replicas yet.
- and after a while you find it but the sequence of the comments are not right! -> database is partitioned.
- First comment goes to the first shard and second comment goes to the second shard;
- each shard is replicated
- Second comment synced to the second shard first then first comment in the shard sync to its replica;
- System assume the second is older when read
- Consistency model
- First disappearing comment: can be implementing by monotonic reads
- Second issue can be implementing read-your(after)-writes ;
- Third out of order comment can be solve by consistent prefix reads.
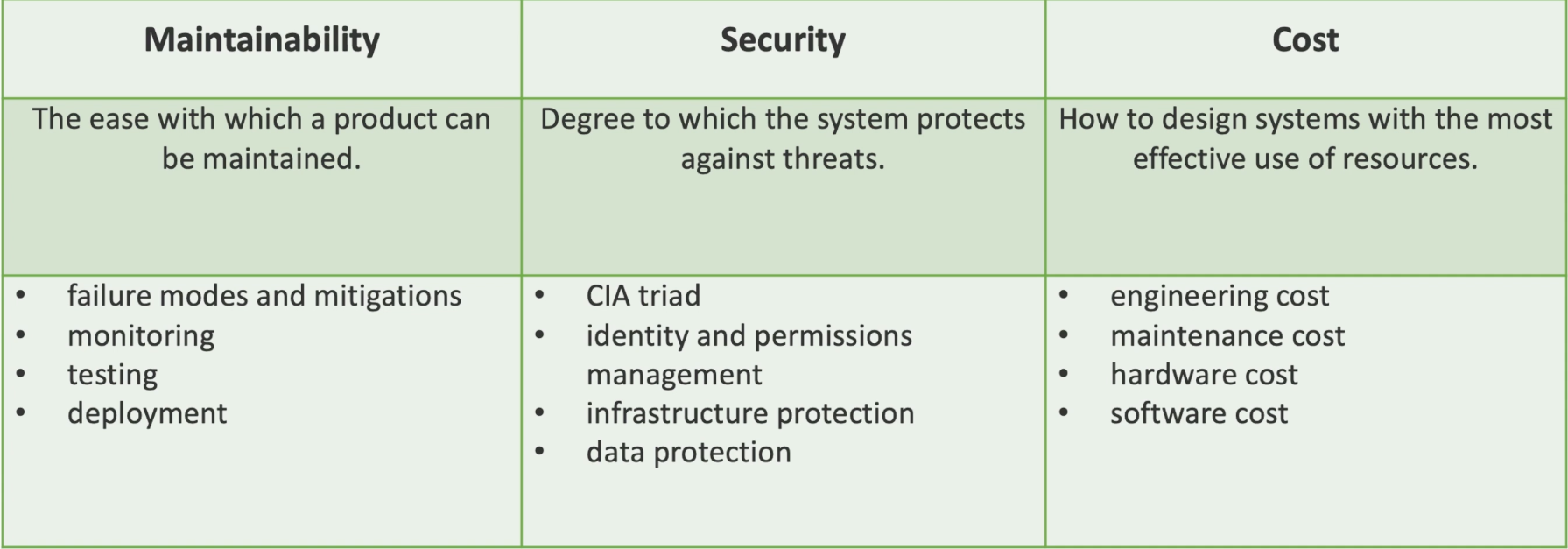
Maintainability, security, cost
Maintainability
- After product launch -> best practices
- Bufix
- Adding new features
- Improving performance
- Insreasing test coverage
- Documentation....
Interview questions:
- Failure modes and mitigations
- If some components fails, what happens to the rest of the system
- How the system handle network partitions?
- How we want the system handle network partitions?
- Monitoring
- How to monitor health
- How do I know which part is broken
- Testing
- Test each individual component
- How to do E2E test
- Deployment
- How to do CD safely
- How to roll back quickly and safely
Security
- CIA:
- confidentiality : data protected from unauthorized users;
- Integrity: data is not corrupted or lost and only authorized user can modify data
- Availability : authorized users have access to resources when needed
Interview questions:
- Indetiyt and permission management
- Who can access
- Who can access what in the system
- How to implement authentication and authorization in the system
- Infrustrture protects:
- DDos
- SQL
- Firewall or API gateway
- Data protection
- Protect data in rest
- In transit
Cost
- Reduce total cost
- engineering cost: design implementation, testing and deployment....
- Maintenance cost: automation of mounting testing and deploying
- Resource cost:
- hardware : machines , load balancers , network devices
- software : cloud service
- Storage
- Data transfer
- Request count
- How system design affect cost
- Availability : rudandant hardware -> hardware
- Durability: replica ->storage up
- Elasticity : reduce hardware cost up
- Long pulling request bathing: request count down
- Compression : byte transferred down
- Shot and cold storage : storage cost down (cold -> not used frequently)
Summary of System requirements
Process:
- Identify both functional and non-func requiements
- Write them down on the board
- Use non-func requirements when evaluate different options
- To identify function requirements, start with the customers and move backwards( interview should define some of them)
- Be ready to convert requirements to APIs
Don't over engineered. Think out load, keep generating and sharing dreads, enumerates concepts and discuss trade offs.