I used a new framework introduced by Hao Chen in his blogs for learning new things to organize this article.
-
What is consistent hashing
Quoted from Wikipedia: "Consistent hashing is a special kind of hashing such that when a hash table is re-sized and consistent hashing is used, only k/n keys need to be remapped on average, where k is the number of keys, and n is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped”.
-
What problem it solved?
-
The rehashing problem.
-
If you have multiple servers and you want to balance the loads.
-
The requests are routed to server based on their keys(IP, UID..)
-
Route mentioned above is using hash function, here we use module operation
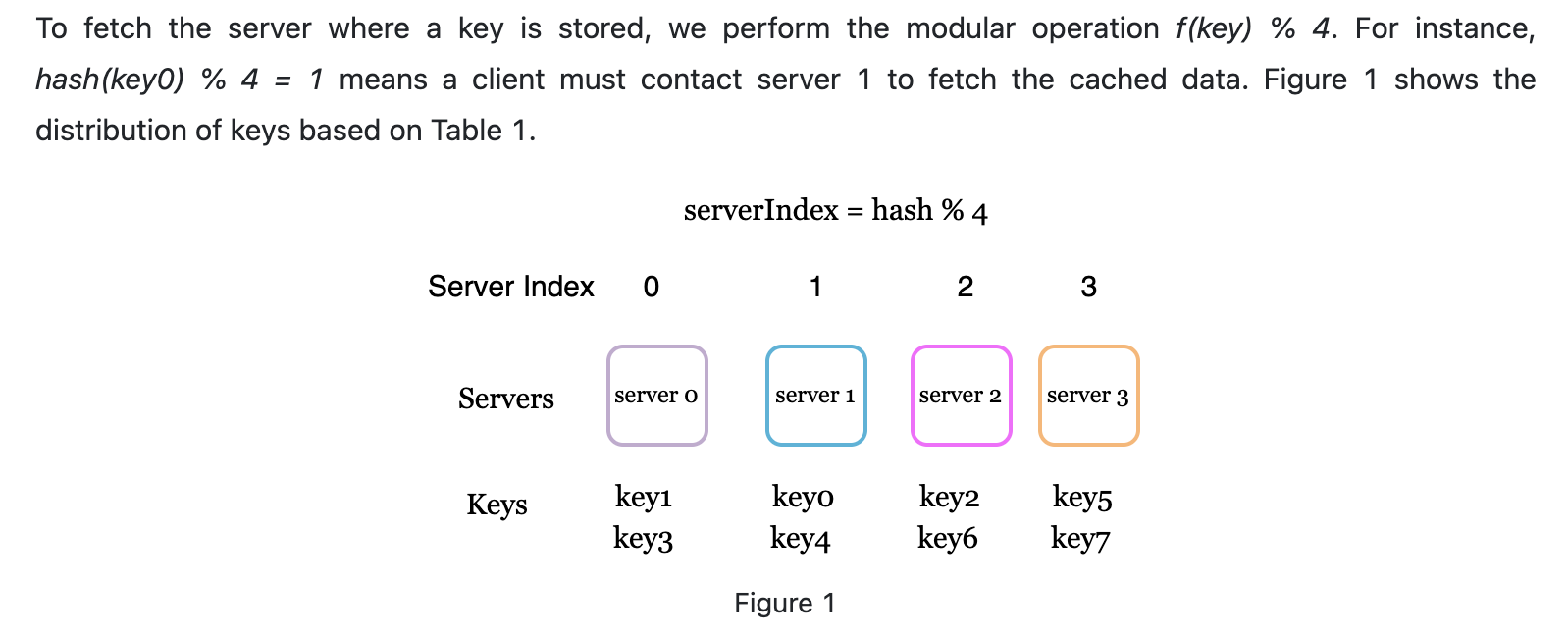
-
This works fine when the server count is fixed while in real world, server maybe down. or new servers added. For example, server1 is down
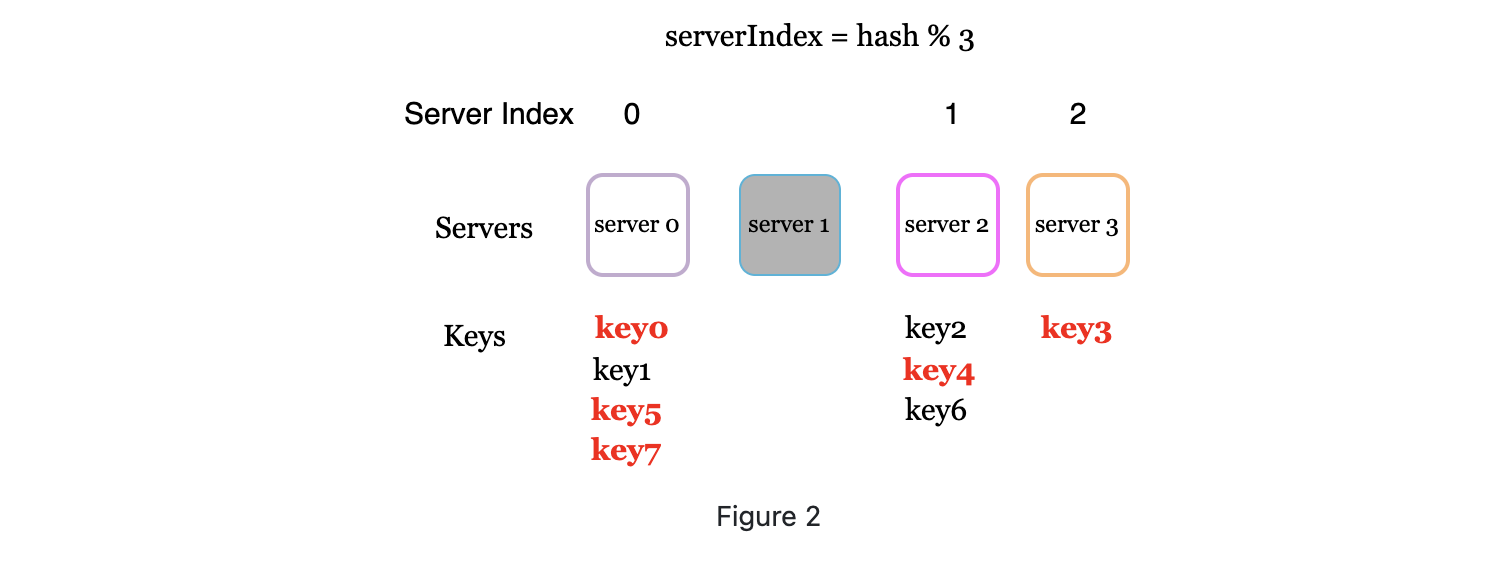
-
The due to rehashing, and hash function changed, most keys are mapped to wrong server to fetch data. If those are cache servers, then there will be a storm of cache miss.
-
Consistent hashing could mitigate this issue.
-
-
-
Key components
-
Hash space and hash ring
-
Hash space: We use SHA-1 as the hash function, and the output range of the function is : x0, x1, x2...xn. In cryptography, SHA-a's hash space goes from 0-2^160 - 1.
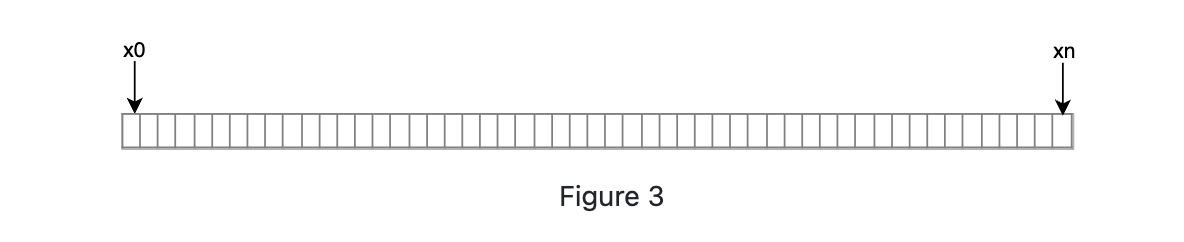
-
Hash ring: by collection bother ends, we get a hash ring
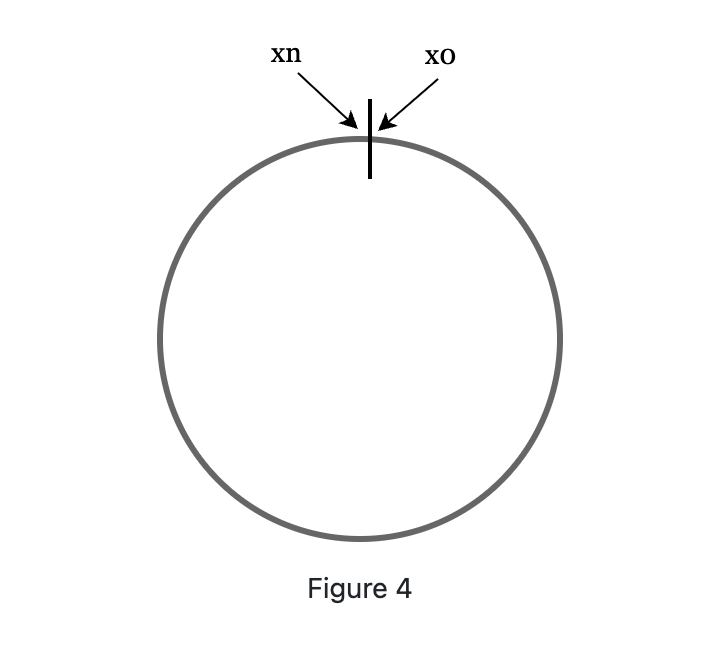
-
-
Hash Servers
-
Use the same hash function to map the server to the ring
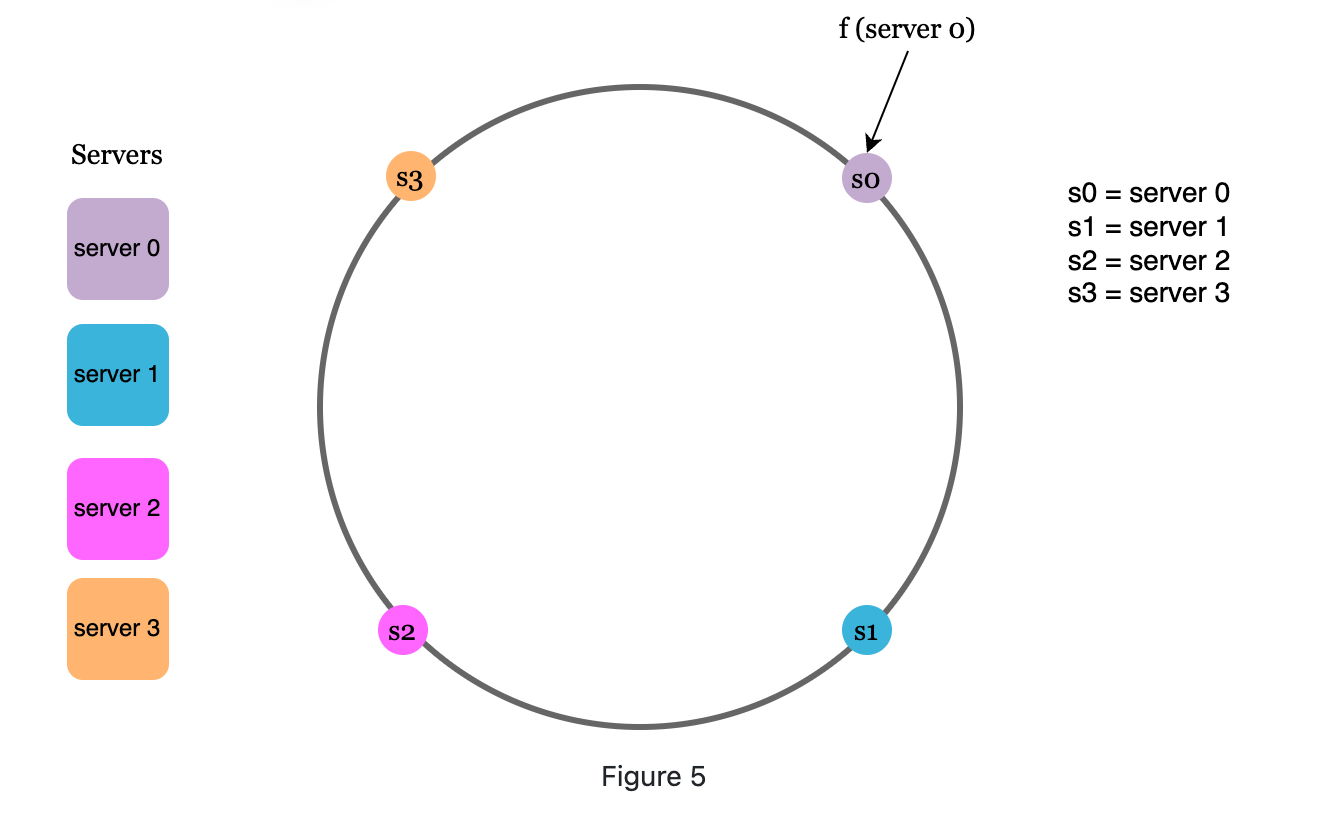
-
-
Hash keys
-
Items use the hash function hashed onto the ring.
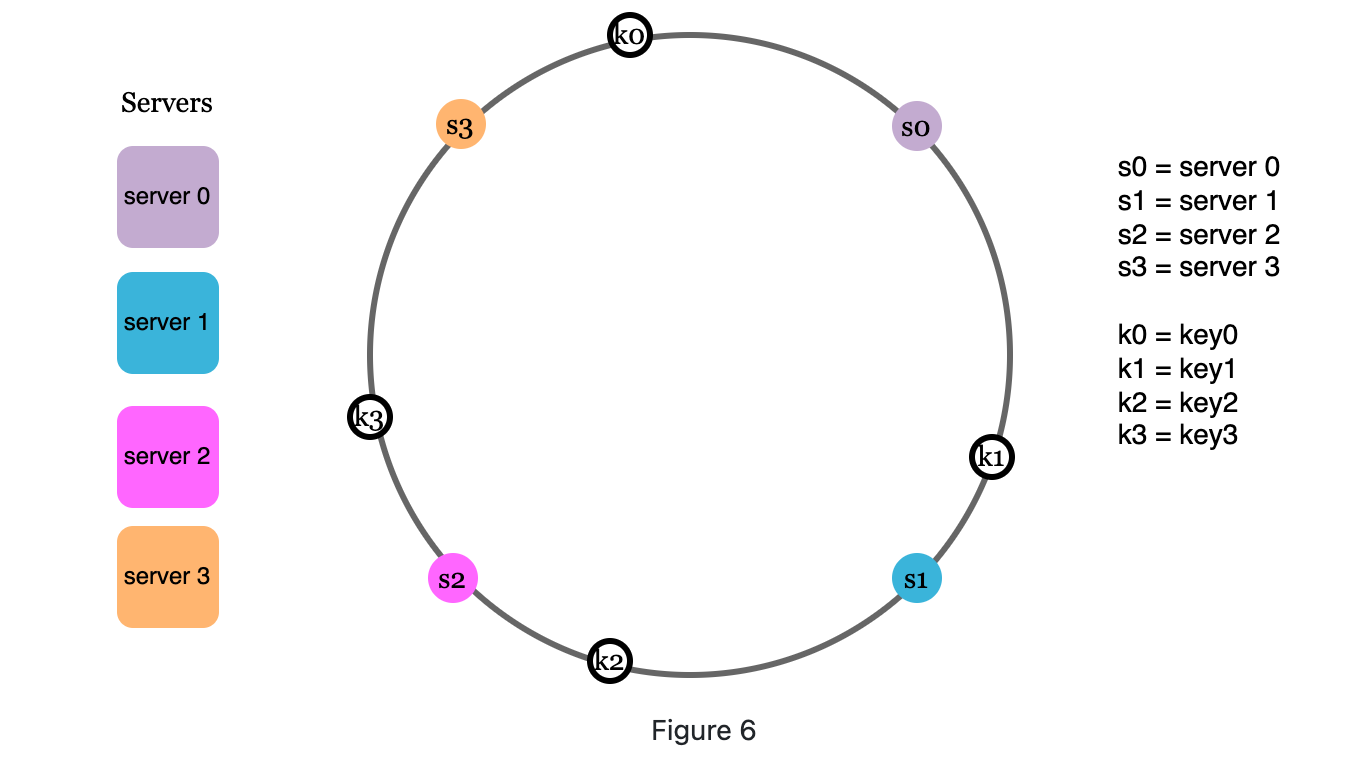
-
-
Server lookup
-
When a key is mapped on the ring, go clockwise to until a server is found, the server is where the key stored.
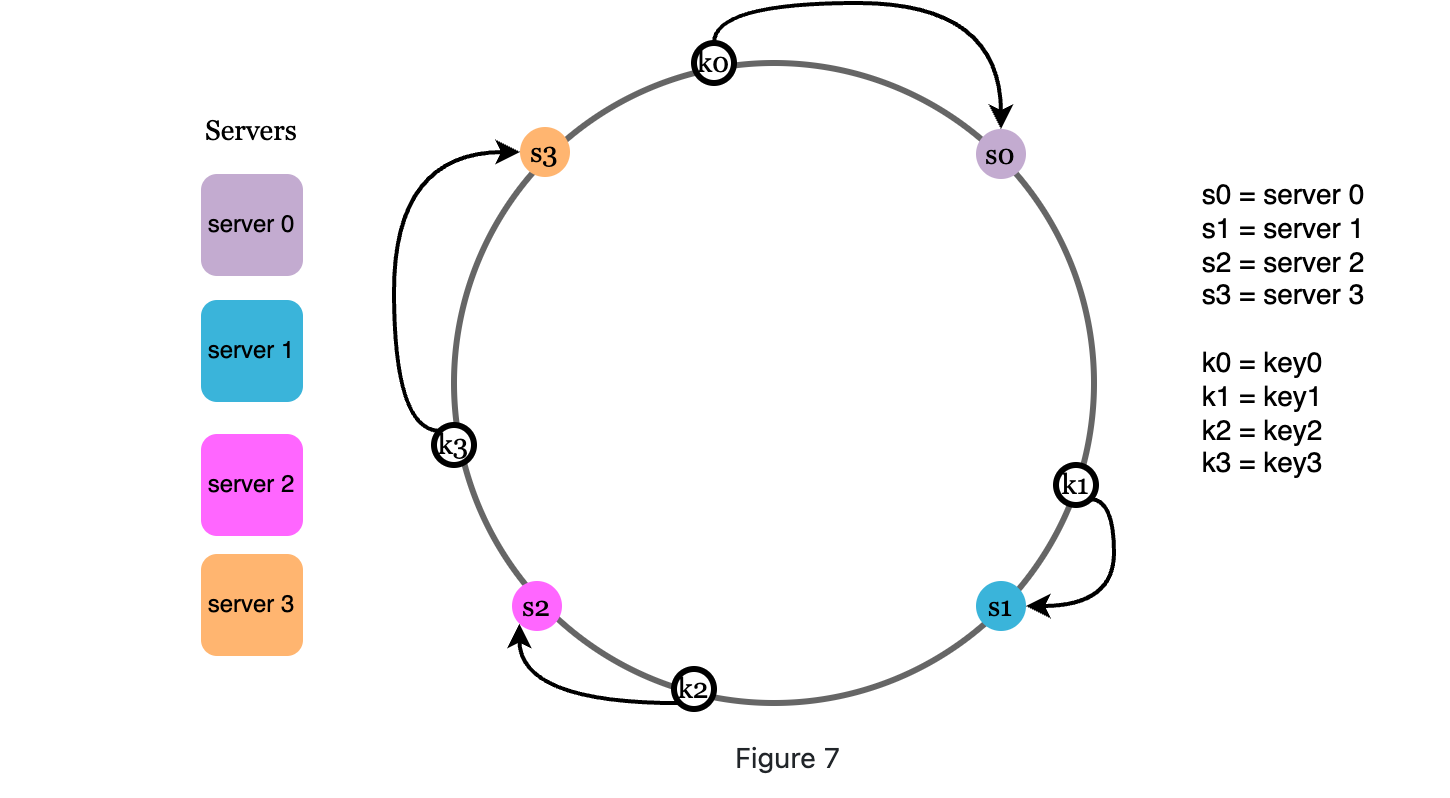
-
Adding a server
-
When adding a new server, it goes anti clockwise and search, until next server, all keys it meets will be redistributed to this new server.
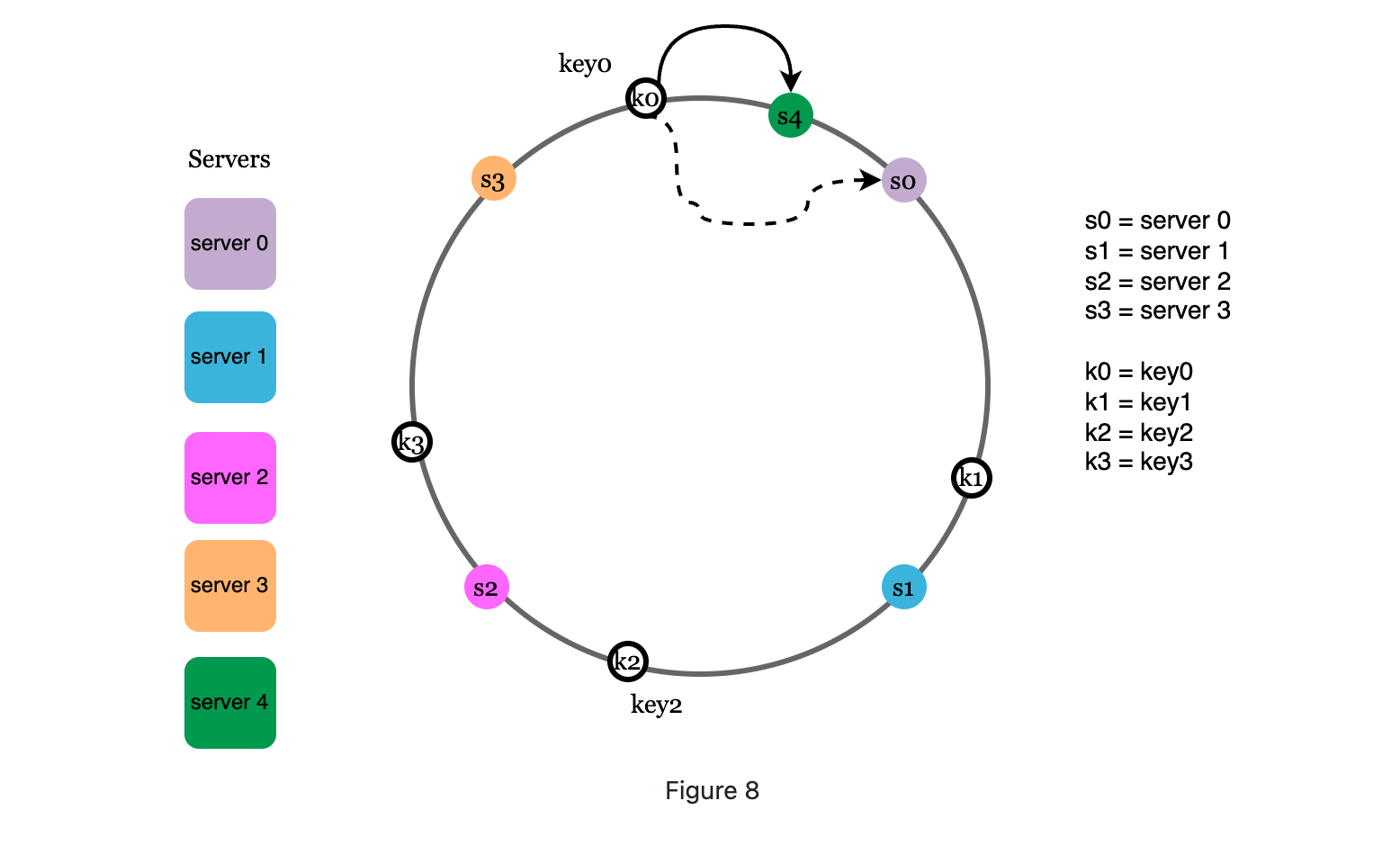
-
-
remove a server
-
When removing a server, the keys stores on it(between it and its previous server or go anti-clockwise from the removed server until next server) will go clockwise to the next first server they meet.
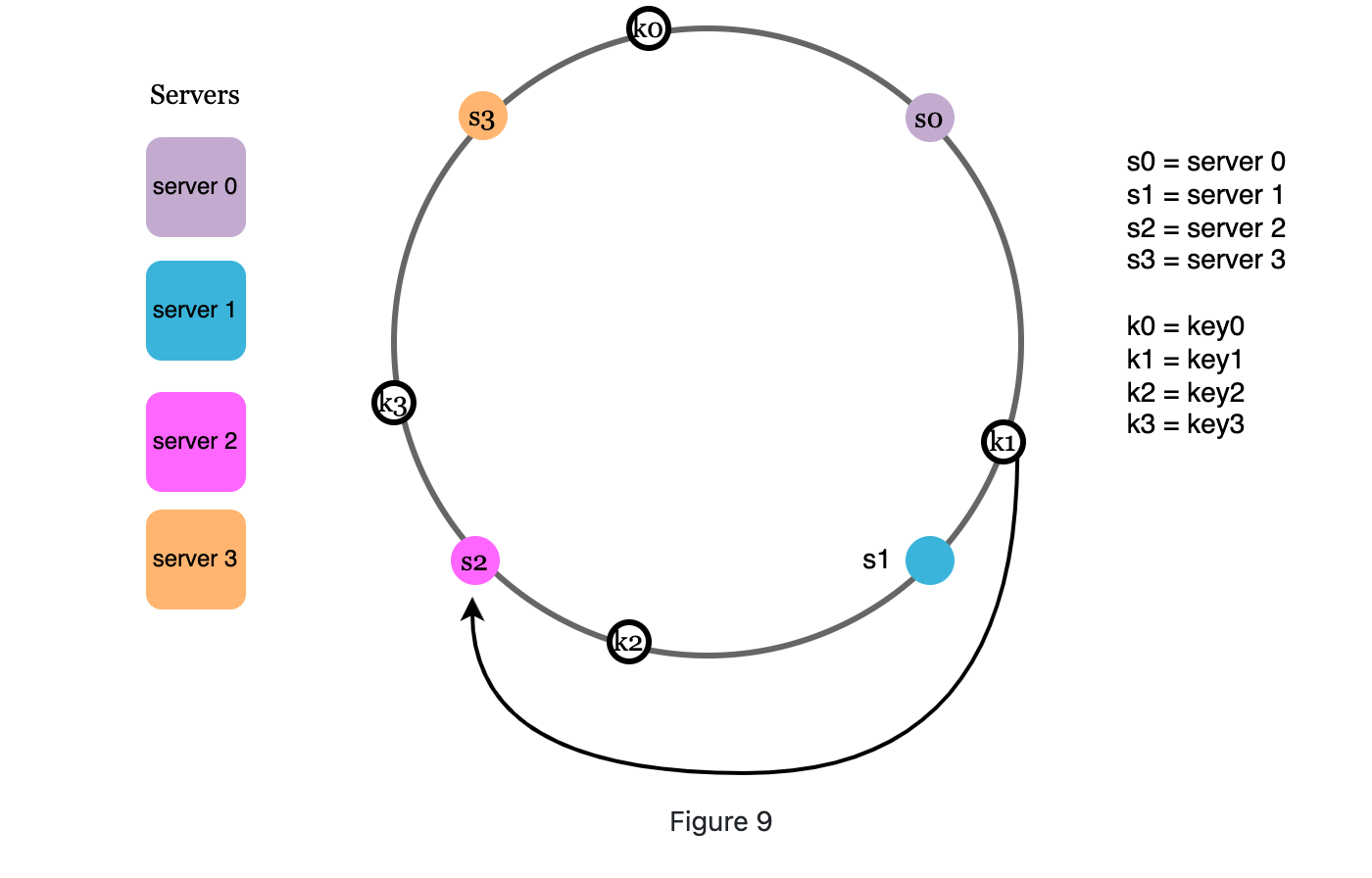
-
-
-
Virtual Node
-
What is it?
-
Each server is represented by multiple virtual nodes on the ring. (A real server is mapped to several virtual nodes)
-
From my perspective, the more a server(node) is mapped to vNode, the more space of a ring it will be responsible and with many different nodes, they are more uniformly distributed.(more balanced)
This is because the standard deviation gets smaller with more virtual nodes, leading to balanced data distribution. Standard deviation measures how data are spread out. The outcome of an experiment carried out by online research shows that with one or two hundred virtual nodes, the standard deviation is between 5% (200 virtual nodes) and 10% (100 virtual nodes) of the mean.
However, more spaces are needed to store data about virtual nodes. This is a tradeoff, and we can tune the number of virtual nodes to fit our system requirements.
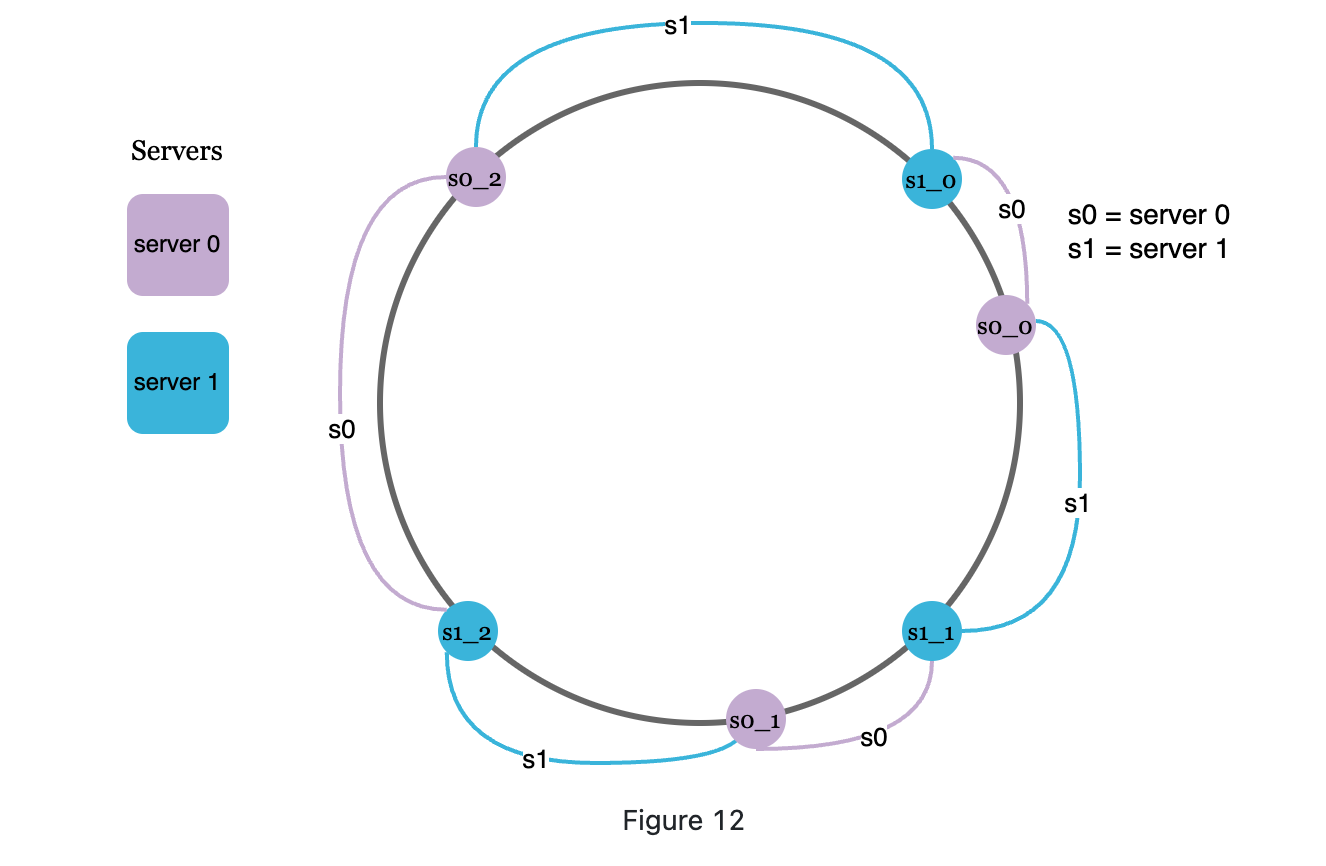
-
-
Why introducing
-
Servers are not uniformly distributed on the ring in the real world. When s1 down, the space between s0-s2 is way bigger than s2-s3:
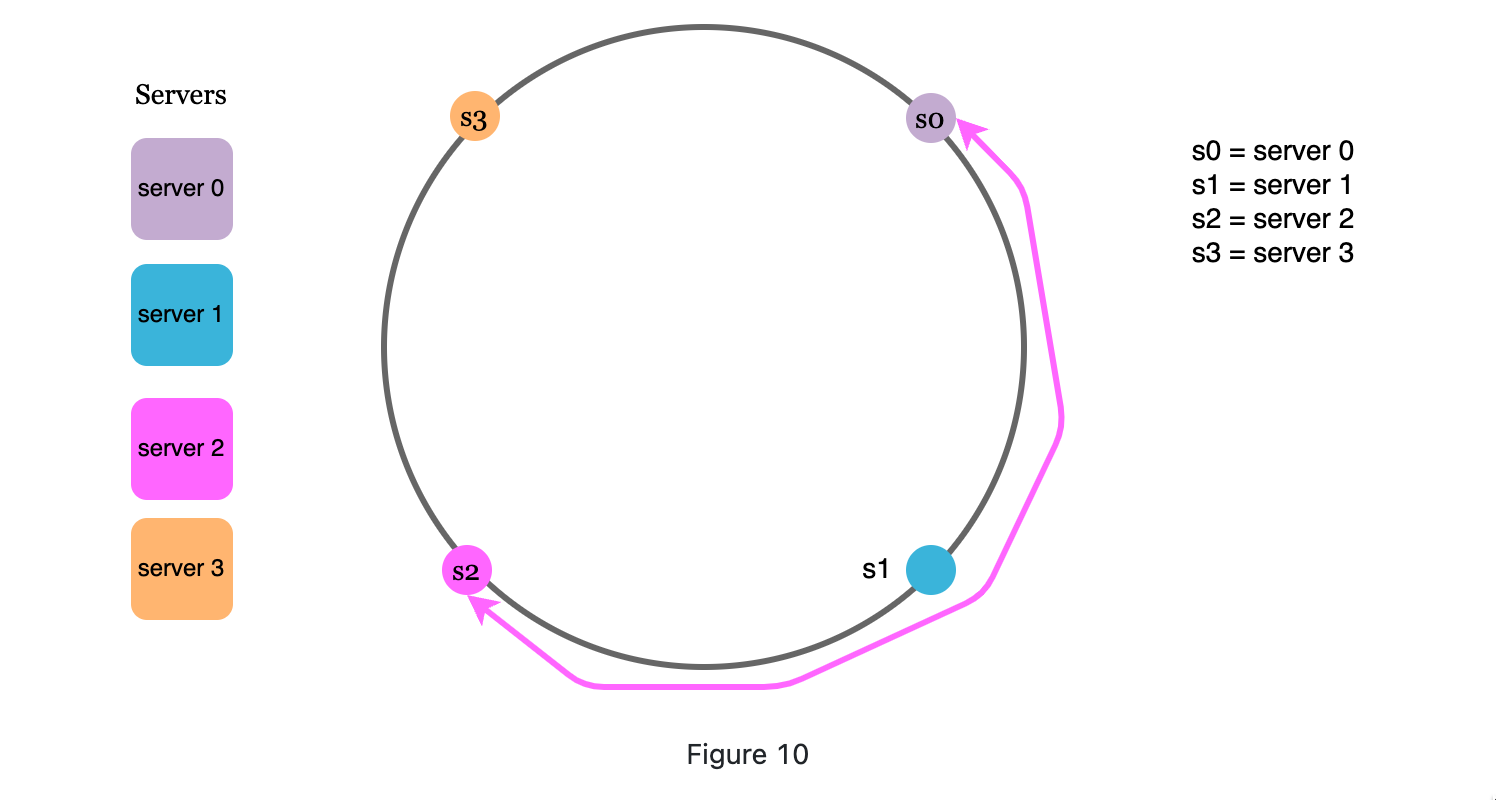
-
Keys may not be uniformly distributed on the ring in the real world.
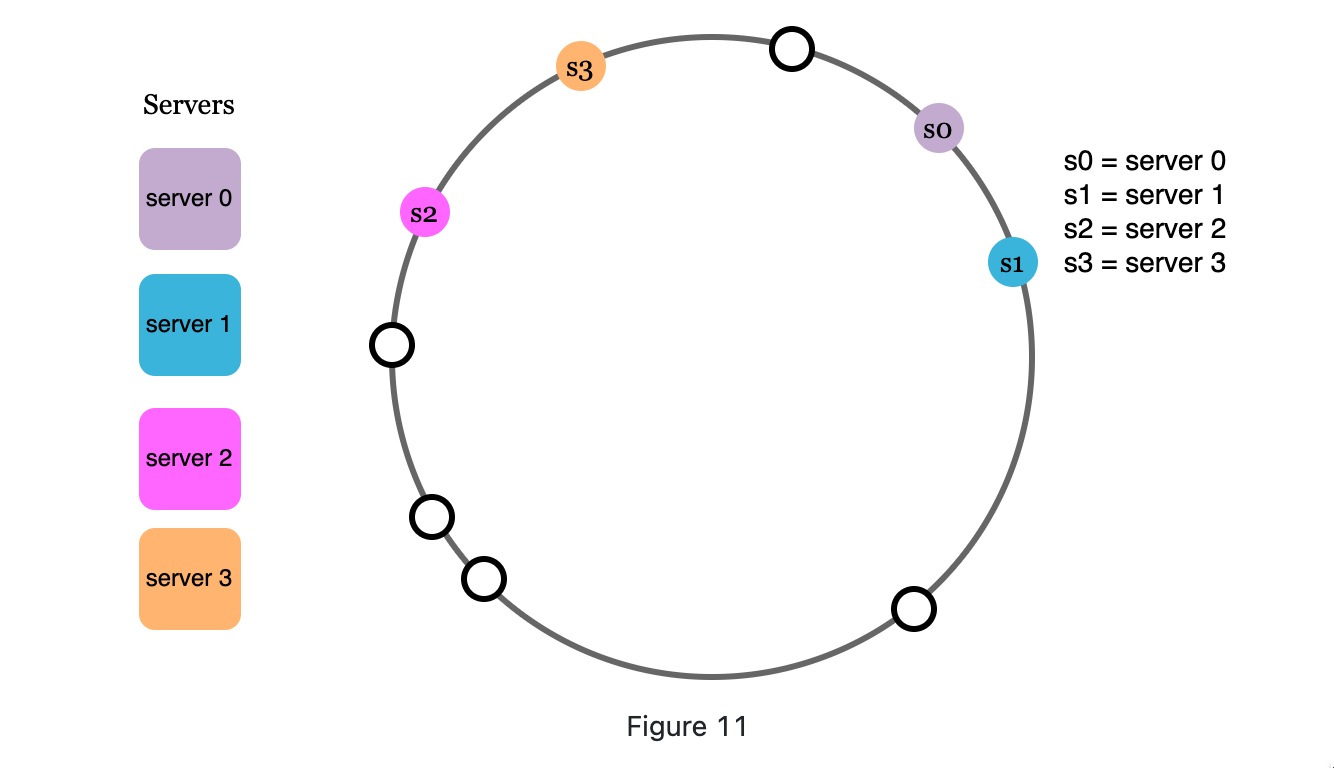
-
-
-
-
What tech it based on and implementation
A implementation using Java by Chat-GPT
import java.util.*; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; public class ConsistentHash<T> { private final HashFunction hashFunction; private final int numberOfReplicas; private final SortedMap<Long, T> circle = new TreeMap<Long, T>(); public ConsistentHash(HashFunction hashFunction, int numberOfReplicas, Collection<T> nodes) { this.hashFunction = hashFunction; this.numberOfReplicas = numberOfReplicas; for (T node : nodes) { add(node); } } public void add(T node) { for (int i = 0; i < numberOfReplicas; i++) { circle.put(hashFunction.hash(node.toString() + i), node); } } public void remove(T node) { for (int i = 0; i < numberOfReplicas; i++) { circle.remove(hashFunction.hash(node.toString() + i)); } } public T get(Object key) { if (circle.isEmpty()) { return null; } long hash = hashFunction.hash(key.toString()); if (!circle.containsKey(hash)) { SortedMap<Long, T> tailMap = circle.tailMap(hash); hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey(); } return circle.get(hash); } public interface HashFunction { long hash(String key); } public static class MD5HashFunction implements HashFunction { private MessageDigest md; public MD5HashFunction() throws NoSuchAlgorithmException { md = MessageDigest.getInstance("MD5"); } public long hash(String key) { md.reset(); byte[] bytes = md.digest(key.getBytes()); long result = ((long) (bytes[3] & 0xFF) << 24) | ((long) (bytes[2] & 0xFF) << 16) | ((long) (bytes[1] & 0xFF) << 8) | (bytes[0] & 0xFF); return result & 0xffffffffL; } } }
In this implementation, we define the ConsistentHash class to represent a consistent hash. The constructor method receives the HashFunction object, the number of virtual nodes and the list of nodes. In the add method, we add multiple virtual nodes to each node and add these virtual nodes to the hash ring. In the remove method, we remove all virtual nodes of the node from the hash ring. In the get method, we find the node corresponding to the key by calculating the hash value of the key. the HashFunction interface is used to define the hash function, which is implemented by the MD5HashFunction class and uses the MD5 hash algorithm to calculate the hash value.
In Java implementation of consistent hashing, TreeMap is used to store the nodes on the hash ring. we need to sort the nodes according to their position on the hash ring, so TreeMap is a suitable data structure.
Another advantage of using TreeMap is that you can easily find the position of a node on the hash ring by using the tailMap method and the firstKey method. In the get method, we first calculate the hash value of the key and determine whether the hash value already exists on the hash ring by using the circle.containsKey method. If it does not exist, we use the tailMap method to find all keys larger than the hash value and use the firstKey method to get the first key (i.e., the position of the node on the hash ring). If the tailMap is empty, the circle.firstKey method is used to get the first node on the hash ring.
-
Pros and cons
- Pro:
- compared with original hash function(module), it only impact n/k nodes rather than the whole ring when adding or removing servers(nodes).(Scalability)
- Nodes can relatively uniformly distributed on the ring.
- Cons
- When the amount of node is small the distribution may be not uniformly;
- Different hash function will affect the distribution, needs to wisely choose one.
- Too less nodes may cause a heavy work on nodes, then we should add more nodes; too many node may cause an insufficient space to cache all the node keys so you may want to use some cache algorithm for effective caching.
- Pro:
-
Use case
Consistent hashing is commonly used in scenarios such as load balancing, data partitioning and caching in distributed systems, and the following are some specific usage scenarios.
-
Distributed load balancing: Consistent hashing can achieve load balancing by hashing requests to different nodes in the hash ring. This can help the system avoid overloading a node and improve the performance and reliability of the system.
-
Data partition: Consistent hashing can slice the data to different nodes, thus achieving a balanced distribution of data. This can help the system to improve the speed and reliability of data access.
-
Caching: Consistent hashing can hash the cached data to different nodes to achieve a balanced distribution of data. This can help the system to improve the hit rate and access speed of the cache.
-
CDN (Content Delivery Network): Consistent hashing allows requests to be hashed to different CDN nodes, thus achieving a balanced distribution of content. This helps CDNs to improve the access speed and reliability of content.
-
-
industry implementation
- Apache Shiro: Apache Shiro is a powerful Java security framework that includes an implementation of the Consistent Hash Algorithm.
- Redis Cluster: Redis is a popular NoSQL database, and Redis Cluster is a distributed cluster implementation of Redis that includes an implementation of the Consistent Hash Algorithm.
- Consul: Consul is a service discovery and configuration tool that includes an implementation of the Consistent Hash Algorithm for distributing requests to different Consul nodes.
- Netflix Eureka: Netflix Eureka is a service registration and discovery tool that includes an implementation of a consistent hashing algorithm for distributing requests to different Eureka nodes.
- Tomcat Load Balancer: Tomcat Load Balancer is an Apache Tomcat-based load balancer that includes an implementation of a consistent hashing algorithm for distributing requests to different Tomcat nodes.