- The ebook discuss things of the index , more specific , the b-tree index for developers
Anatomy of an Index
- An index is a distance structure in the database that is build using the
CREATE INDEXstatement ; it requires its own disk space, hold a copy of the indexed table data and is pure redundancy -> it doesn't change the original table data and creates a new data structure that refers to the table. - Searching in a database index is like searing a telephone -> the entries are ordered -> so it's fast.
- We cannot update the index each time the table there is a write (update/ insert) -> too slow for the query
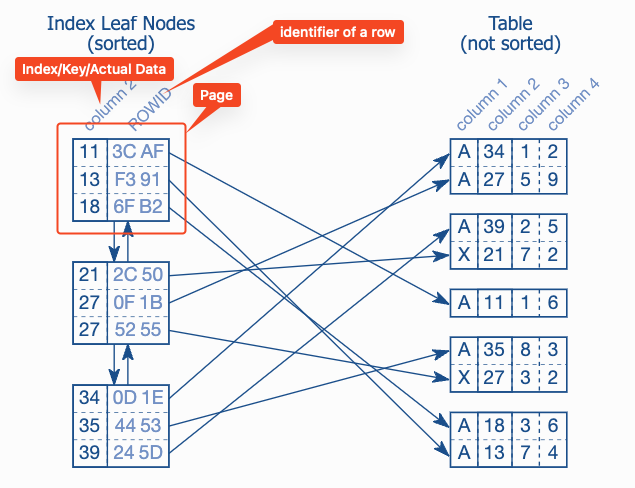
The Leaf Nodes - A doubly linked list
- The purpose of the index is to provide an ordered representation of the indexed data
- But we cannot store it physically ordered because insert will cause moving to all the data to make new space
- The solution is to establish a logical order that independent of physical order in memory.
- The logical order is established via a doubly linked list. Each node has links to its neighbors. -> adding nodes will cause small data change -> they only change the pointers.
- The node in database is called leaf-nodes -> each node is stored in a database block or page. (Database smallest storage unit) -> normally a few KB
- Database stores as much as index entries in each page.
- Order is maintained not only among index leaf nodes but the index entries within each node.
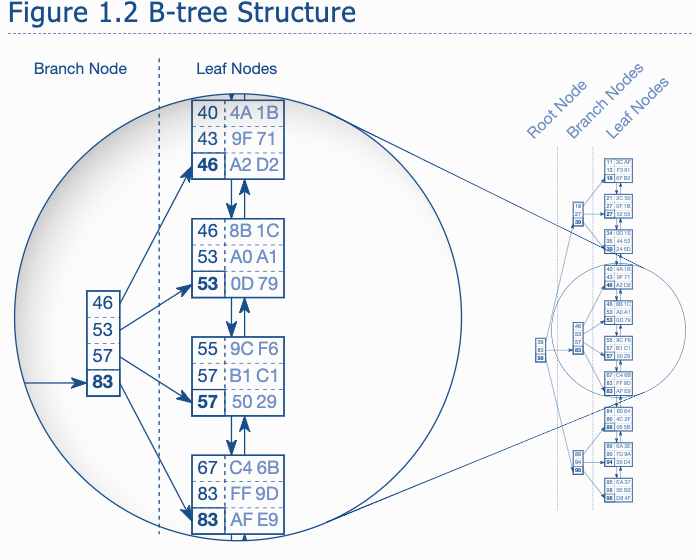
The B-Tree - A balanced Tree
-
The database use a balanced tree - B-tree to search the leaf nodes.
-
-
The branch node and root.
- Searching starts from root and
- Branch nodes are the node that's not leaf nodes. Their node entry are some node of their sons. In the above graph, it's the max node entry of each leaf.
- A Branch layer is built until all the leaf are covered.
-
The next layer of branch are build similarly , until there is only one node -> the root.
-
Its not a binary tree, it's balanced
-
The database maintains the indexes automatically (the tree)
-
The traversal is efficient ,
- it reach every data in the same set -> tree are balanced so the depth are the same.
- The tree depth grows very slow compared to the leaf node -> logarithmic
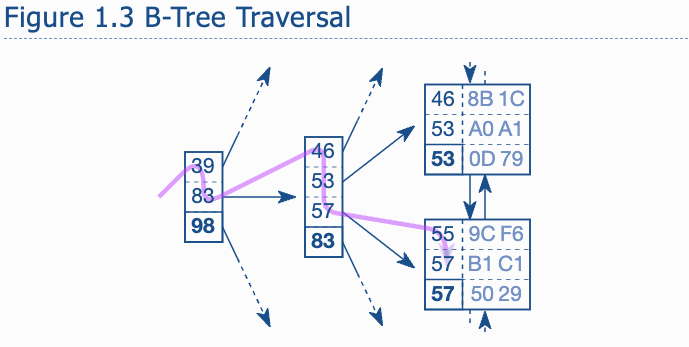
Slow Indexes lookup, Part1 - Two Ingredients make the index slow
- The index can be slow in some condition
- The first one for a slow index look up is the leaf node chain.
- In the traversal figure 1.3 the tree traversal not only in the tree , but also the leaf node chain. There are two entry with key 57, so traversal needs to go through the page to see if there are further matching entries.
- The second is the accessing of table
- Usually the table data is scattered across many table blocks -> many table access.
- An index look up requires three steps:
- Tree traversal (the only step has a upper bound of the number of accessed bocks -> the tree depth);
- Following leaf node chain;
- Fetching the table data.
The Where Clause
- The where clause defines the search condition of an SQL statement, and it thus falls into the core functional domain of an index: finding data quickly.
- This chapter explains how different operators affect index usage and how to make sure that an index is usable for as many quires as possible.
The Equals Operator - Exact key lookup
Primary Keys - Verifying index usage
-
We analysis an use case , use this table
sql CREATE TABLE employees ( employee_id NUMBER NOT NULL, first_name VARCHAR2(1000) NOT NULL, last_name VARCHAR2(1000) NOT NULL, date_of_birth DATE NOT NULL, phone_number VARCHAR2(1000) NOT NULL, CONSTRAINT employees_pk PRIMARY KEY (employee_id) )The database automatically creates an index for the primary key. That means there is an index on the EMPLOYEE_ID column, even though there is no
create indexstatement. -
The following query uses the primary key to retrieve an employee's name:
sql SELECT first_name, last_name FROM employees WHERE employee_id = 123The
whereclause cannot match multiple rows because the primary ket constraint ensures uniqueness of theEMPLOYEE_IDvalues. The database doesn't need to follow the index leaf nodes -> it's enough to traverses the index tree.Use execution plan for analysis :
ba +----+-----------+-------+---------+---------+------+-------+ | id | table | type | key | key_len | rows | Extra | +----+-----------+-------+---------+---------+------+-------+ | 1 | employees | const | PRIMARY | 5 | 1 | | +----+-----------+-------+---------+---------+------+-------+ -
After accessing the index, the database must do one more disk access but it will not be a bottleneck since there is only one disk access due to the uniqueness constraint.
Concatenated Keys - Multi-column indexes
-
Concatenated key, also called multi-column, composite or combined index.
-
The column order of a concatenated index has great impact on its usability so it must be chosen carefully.
-
Say we have a company merger , so the
employee_idacross company are no longer unique so we introduce a new columnSUBSIDIARY_IDto re-establish uniqueness. -
The index for new primary key defines as follows :
sql CREATE UNIQUE INDEX employees_pk ON employees (employee_id, subsidiary_id) -
A query to a particular employee must take subsidiary_id column into account:
sql SELECT first_name, last_name FROM employees WHERE employee_id = 123 AND subsidiary_id = 30 -
But what if the query forget to use employee_id -> it becomes a full table scan
-
The entries for subsidiary are not sorted next to each other , and they are not in the tree so they can not leverage the tree :
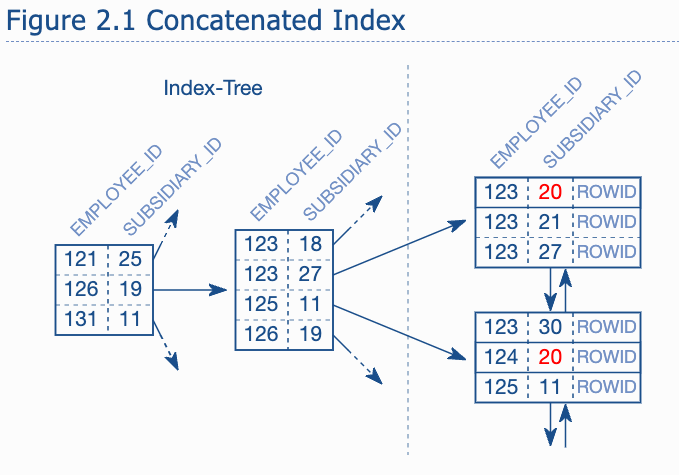
-
We can add another index on
SUBSIDIRAY_IDto improve the speed but searchEMPLOYEE_IDalone doesn't make sense. -
We can take advantage that the first index column is always usable for searching. The trick is to reverse the index column order so that
SUBSIDIARY_IDis in the first positionsql CREATE UNIQUE INDEX EMPLOYEES_PK ON EMPLOYEES (SUBSIDIARY_ID, EMPLOYEE_ID) -
SUBSIDIARY_IDbecomes the first column in the index -> the primary sort criterion -> they will be used to build the B-tree -
The most important consideration when defining a concatenated index is how to choose the column order so it can be used as often as possible.
-
Now it's using
SUBSIDIARY_ID, while it's not unique so the database must follow the leaf nodes in order to find all maturing entriesbash +----+-----------+------+---------+---------+------+-------+ | id | table | type | key | key_len | rows | Extra | +----+-----------+------+---------+---------+------+-------+ | 1 | employees | ref | PRIMARY | 5 | 123 | | +----+-----------+------+---------+---------+------+-------+ -
Two indexes deliver better select performance but one index saves storage, and has less maintenance overhead -> the fewer indexes a table has. The better the insert, delete and update performance.
-
To define optimal index, you not only need to know how index works but also how the data are queried (the condition in the where clause) -> developer knows best.
Slow Indexes, Part II - The first ingredient, revisited
This chapter explains the way database pick up an index and the side effects when changing existing indexes.
-
Indexes become usable no matter there are other condition if they are met to be used;
-
But query optimizer will pick the best one
-
sql SELECT first_name, last_name, subsidiary_id, phone_number FROM employees WHERE last_name = 'WINAND' AND subsidiary_id = 30the execution plan is:
```bash
|Id |Operation | Name | Rows | Cost |
| 0 |SELECT STATEMENT | | 1 | 30 | |1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 30 | |2 | INDEX RANGE SCAN | EMPLOYEES_PK | 40 | 2 |
Predicate Information (identified by operation id):
1 - filter("LAST_NAME"='WINAND') 2 - access("SUBSIDIARY_ID"=30)
```
-
When we deliberately don't use index, the execution plan:
```bash
| Id | Operation | Name | Rows | Cost |
| 0 | SELECT STATEMENT | | 1 | 477 | |* 1 | TABLE ACCESS FULL| EMPLOYEES | 1 | 477 |
Predicate Information (identified by operation id):
1 - filter("LAST_NAME"='WINAND' AND "SUBSIDIARY_ID"=30) ```
Only 1 row! Which is faster then using index -> unusual !
-
So we debug step by step:
- The using index case, ID 2 it fetch the rows use the subsidiary id , find the match, and continue scan all the entries -> 40 rows
- Then read them individually ! -> that's the reason
- Since the full table scan in the case 2 read the data in one shot, while case 1 has 40 read!
-
Choosing the best execution plan depends on the tables data distributions as well so the optimizer users statistics about the content of the database .
-
If there is no statistics (the data were deleted), the database use default values.
-
If we provide previous query statistics like :
```bash
|Id |Operation | Name | Rows | Cost |
| 0 |SELECT STATEMENT | | 1 | 680 | |1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 680 | |2 | INDEX RANGE SCAN | EMPLOYEES_PK | 1000 | 4 |
Predicate Information (identified by operation id):
1 - filter("LAST_NAME"='WINAND') 2 - access("SUBSIDIARY_ID"=30) ```
Which the cost 680 is higher than the full table scan, the query optimizer will choose the latter.
-
We add a new index on the last name column
sql CREATE INDEX emp_name ON employees (last_name) -
The exception plan become :
```bash
| Id | Operation | Name | Rows | Cost |
| 0 | SELECT STATEMENT | | 1 | 3 | | 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 3 | | 2 | INDEX RANGE SCAN | EMP_NAME | 1 | 1 |
Predicate Information (identified by operation id):
1 - filter("SUBSIDIARY_ID"=30) 2 - access("LAST_NAME"='WINAND') ```
This is faster then the full table scan -> only one row fetched
-
Conclusion is: database don't always use the best way automatically.
Functions - Using functions in the where clause
You may need to search will same case (upper /lower).
This chapter explains how you use it without harming the performance. (MySQL is case sensitive.)
Case-insensitive Search - UPPER and LOWER
-
You can use UPPER or LOWER to ignore the case.
sql SELECT first_name, last_name, phone_number FROM employees WHERE UPPER(last_name) = UPPER('winand') -
The execution plan is not that simple :
```bash
| Id | Operation | Name | Rows | Cost |
| 0 | SELECT STATEMENT | | 10 | 477 | |* 1 | TABLE ACCESS FULL| EMPLOYEES | 10 | 477 |
Predicate Information (identified by operation id):
1 - filter(UPPER("LAST_NAME")='WINAND') ```
A full table scan! Although there is an index on LAST_NAME but the search is on UPPER(LAST_NAME) not LAST_NAME. They are different to database.
-
To cover such thing, we need a new index created based on the function- > FBI function based index.
-
Instead of copying the column data directly to the index, the index applies the function first and puts the result into the index. -> the index stores all capitalized(derived data).
-
The execution plan now becomes:
```bash
|Id |Operation | Name | Rows | Cost |
| 0 |SELECT STATEMENT | | 100 | 41 | | 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 100 | 41 | |*2 | INDEX RANGE SCAN | EMP_UP_NAME | 40 | 1 |
Predicate Information (identified by operation id):
2 - access(UPPER("LAST_NAME")='WINAND') ```
-
The line 5 looks strange , 100 rows are going to fetch ?? -> this is the statistic issue -> updating statistic -> then check the execution plan :
```bash
|Id |Operation | Name | Rows | Cost |
| 0 |SELECT STATEMENT | | 1 | 3 | | 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 3 | |*2 | INDEX RANGE SCAN | EMP_UP_NAME | 1 | 1 |
Predicate Information (identified by operation id):
2 - access(UPPER("LAST_NAME")='WINAND') ```
-
-
MySQL and SQL server doesn't support such FBI. But there is workaround : (create a redundancy column in the table and create index on the column)
```sql
Since MySQL 5.7 you can index a generated columns as follows:
ALTER TABLE employees ADD COLUMN last_name_up VARCHAR(255) AS (UPPER(last_name)); CREATE INDEX emp_up_name ON employees (last_name_up); ```
User-Defined Functions - Limitations of function-based indexes
CREATE FUNCTION get_age(date_of_birth DATE) RETURN NUMBER AS BEGIN RETURN TRUNC(MONTHS_BETWEEN(SYSDATE, date_of_birth)/12); END
SELECT first_name, last_name, get_age(date_of_birth) FROM employees WHERE get_age(date_of_birth) = 42
- For such query above we cannot use a FBI index like previous section because the get_age is not deterministic . -> the stored index will not be periodically updated.
- Date, random, or functions depend on environment variables.
Over-Indexing - Avoid redundancy
- Don't try to index everything -> causes maintenance overhead.
- Always try to index original data -> most useful.
- Unify the access path so that one index can be used by several queries
- Some ORM tools use UPPER and LOWER without developers' knowledge. -> Hibernate injects and implicit LOWER for case-insensitive searches. -> good to know
Parameterized Queries / Bind Variables - For Security and performance
-
Security: Bind variables are the best way to prevent SQL injections
-
Performance: Database with execution plan cache use the sql in the cache if the sql is exactly the same -> parametrized sql is regarded as unchanged query -> sql database don't have to rebuild the execution plan
-
The exception is : for example, the affected data volume depends on the actual values :
sql SELECT first_name, last_name FROM employees WHERE subsidiary_id = 20```bash 99 rows selected.
|Id | Operation | Name | Rows | Cost |
| 0 | SELECT STATEMENT | | 99 | 70 | | 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 99 | 70 | |*2 | INDEX RANGE SCAN | EMPLOYEES_PK | 99 | 2 |
Predicate Information (identified by operation id):
2 - access("SUBSIDIARY_ID"=20) ```
This is good
But below is not :
sql SELECT first_name, last_name FROM employees WHERE subsidiary_id = 30```bash 1000 rows selected.
| Id | Operation | Name | Rows | Cost |
| 0 | SELECT STATEMENT | | 1000 | 478 | |* 1 | TABLE ACCESS FULL| EMPLOYEES | 1000 | 478 |
Predicate Information (identified by operation id):
1 - filter("SUBSIDIARY_ID"=30) ```
-
The histogram on
SUBSIDIARY_IDfulfills its purpose. The optimizer uses it to determine the frequency of the subsidiary ID mentioned in the SQL query. Consequently it gets two different row count estimates for both queries. -
The cost of TABLE ACCESS BY INDEX ROWID is sensitive to the row count estimate -> so selecting multiple times will elevate the estimate. -> using index might has higher cost than the full table scan -> so the optimizer will select a different plan.
-
Using a bind parameters -> regards as same query with equal distribution -> so database will always select the same plan
-
But not using the bind parameters always opt for the best execution plan.
-
This is a dilemma. But as developers : That is, you should always use bind parameters except for values that shall influence the execution plan.
-
A java example :
```java // Without bind parameters:
int subsidiary_id; Statement command = connection.createStatement( "select first_name, last_name" + " from employees" + " where subsidiary_id = " + subsidiary_id ); // Using a bind parameter:
int subsidiary_id; PreparedStatement command = connection.prepareStatement( "select first_name, last_name" + " from employees" + " where subsidiary_id = ?" ); command.setInt(1, subsidiary_id); // See also: PreparedStatement class documentation. ```
-
?Question mark is the only placeholder char for sql standard. -> positional parameters , the same number as the argument. (Many database offers using@nameor:name) -
Note: the bind parameter cannot change the structure of an sql : -> You cannot use bind parameters for table or column names.
Searching for Ranges - Beyond equality
Range queries can leverage index, but you need to care about the order of columns in multi-column indexes.
Greater, Less and BETWEEN - The column order revisited
-
The biggest performance risk of an index range scan is the leaf node traversal
-
Golden rule of indexingL keep the scanned index range as small as possible.
sql SELECT first_name, last_name, date_of_birth FROM employees WHERE date_of_birth >= TO_DATE(?, 'YYYY-MM-DD') AND date_of_birth <= TO_DATE(?, 'YYYY-MM-DD') AND subsidiary_id = ? -
Ideal situation is that we have an index covers both columns. -> but in which order?
-
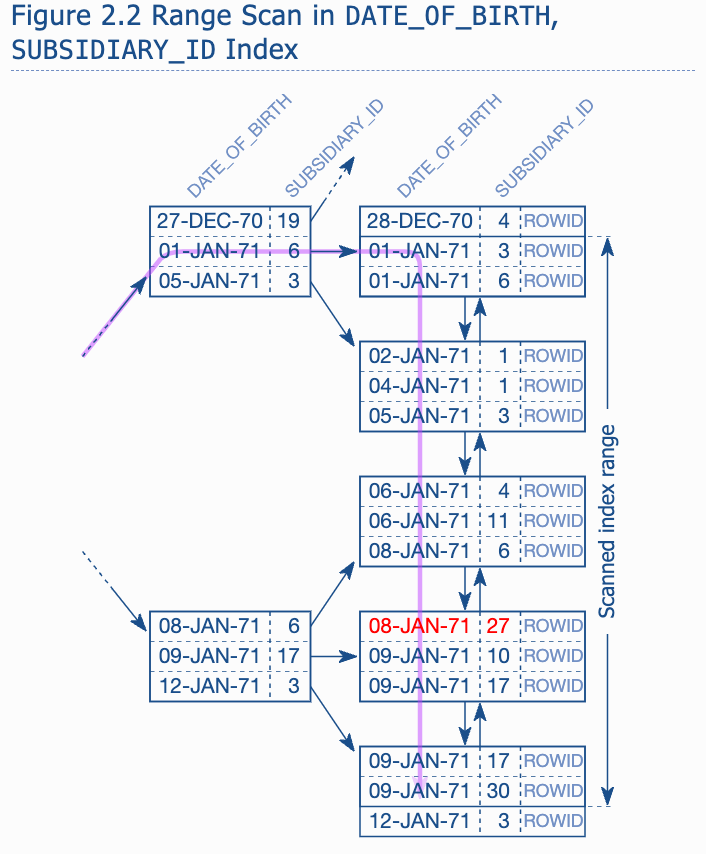
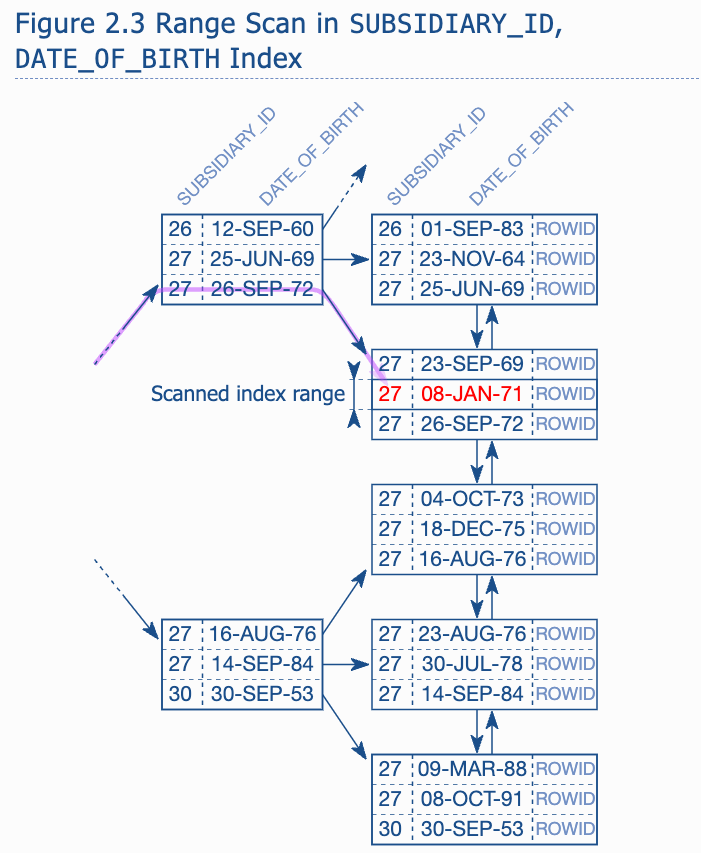
-
The difference is that the equal operator limited the first index column to single value. Within the range for this value (SUBSIDIARY_ID 27), the index is sorted according to the second column(the date of birth), so there is no need to visit the first leaf node because the branch node already indicates that there is no employee for subsidiary 27 born after June 25th 1969 in the first leaf node. -> compare to the first index, the search will be limit to the date range and the SUBSIDIRAY_ID become useless (it doesn't limit the range)
-
```base -------------------------------------------------------------- |Id | Operation | Name | Rows | Cost | -------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 4 | |1 | FILTER | | | | | 2 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 4 | |3 | INDEX RANGE SCAN | EMP_TEST | 2 | 2 | --------------------------------------------------------------
Predicate Information (identified by operation id):
1 - filter(:END_DT >= :START_DT) 3 - access(DATE_OF_BIRTH >= :START_DT AND DATE_OF_BIRTH <= :END_DT) filter(SUBSIDIARY_ID = :SUBS_ID) ```
-
We can see that in the EMP_TEST, the DATE_OF_BIRTH is used for INDEX RANGE SCAN while the SUBSIDIARY_ID is used for only filter.
-
If we change the order of index columns :
```bash
| Id | Operation | Name | Rows | Cost |
| 0 | SELECT STATEMENT | | 1 | 3 | | 1 | FILTER | | | | | 2 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 3 | | 3 | INDEX RANGE SCAN | EMP_TEST2 | 1 | 2 |
Predicate Information (identified by operation id):
1 - filter(:END_DT >= :START_DT) 3 - access(SUBSIDIARY_ID = :SUBS_ID AND DATE_OF_BIRTH >= :START_DT AND DATE_OF_BIRTH <= :END_T) ```
-
The
betweenoperator is like using a>= and <=to specify a range.
Indexing SQL LIKE filters - LIKE is not for full-text search
-
sql SELECT first_name, last_name, date_of_birth FROM employees WHERE UPPER(last_name) LIKE 'WIN%D'bash +----+-----------+-------+----------+---------+------+-------------+ | id | table | type | key | key_len | rows | Extra | +----+-----------+-------+----------+---------+------+-------------+ | 1 | employees | range | emp_name | 767 | 2 | Using where | +----+-----------+-------+----------+---------+------+-------------+ -
LIKE filters can only use the characters before the first wild card during tree traversal.
-
The more selective the prefix before the first wildcard is, the smaller the scanned index range becomes.

Index Combine - Why not using one index for every columns
- One index for multiple columns is better than each column has an index in most cases.
Partial Indexes - Indexing Selected Rows
-
PostgreSQL has partial index; while only add indexes for some rows
-
e.g. we have a query that wants to get all the unprocessed message of a recipient
sql SELECT message FROM messages WHERE processed = 'N' AND receiver = ? -
We can create an index like :
sql CREATE INDEX messages_todo ON messages (receiver, processed)But many unwanted rows are indexed -> waste disk space.-> so we can create index like below:
sql CREATE INDEX messages_todo ON messages (receiver) WHERE processed = 'N'Limitation is: you can only use deterministic functions as is the case everywhere in an index definition. (Due to the potential complexity)
NULL in the Oracle Database - An Important curiosity
Skipped
Obfuscated Conditions - Common anti-patterns
Dates - Pay special attention to DATE types
- Truncate the data and time to get date(using function); or comparing date string (using function) -> index might not be used
- Always use explicit range condition when comparing dates.
Numeric Strings - Don't mix types
-
Number stores in text column and not automatically render an index unless you turn it into string
-
Databse don't do this because doing this may lead to unambiguous result.
42 042 0042 ....
-
-
Using numeric strings may cause performance issues due to conversion ; also error due to invalid converted numbers.
-
This works : (use index)
sql SELECT ... FROM ... WHERE numeric_number = '42'
Combining Columns - use redundant where clauses
-
sql SELECT ... FROM ... WHERE ADDTIME(date_column, time_column) > DATE_ADD(now(), INTERVAL -1 DAY)This might not use index due to the search is based on the derived strings.
-
You can avoid this without using function:
sql SELECT ... FROM ... WHERE datetime_column > DATE_ADD(now(), INTERVAL -1 DAY)But this changed the table (source)
-
Or you can use function based index (and there is no such thing in MySQL)
-
It is still possible to write the query so that the database can use a concatenated index on
DATE_COLUMN,TIME_COLUMNwith an access predicate—at least partially. For that, we add an extra condition on theDATE_COLUMN.sql WHERE ADDTIME(date_column, time_column) > DATE_ADD(now(), INTERVAL -1 DAY) AND date_column >= DATE(DATE_ADD(now(), INTERVAL -1 DAY))The new condition is absolutely redundant but it is a straight filter on
DATE_COLUMNthat can be used as access predicate. Even though this technique is not perfect, it is usually a good enough approximation.
Smart Logic - The smartest way to make SQL slow
Skip(MySQL doesn't have a execution plan cache)
Math - Database don't solve equations
-
The database will not use index for such :
sql SELECT a, b FROM table_name WHERE 3*a + 5 = b -
But ew can leverage function based index if we need it.
Appendix
How to use execution plan in MySQL?
- Just put
explainbefore the query SQL. - The most important information is in the TYPE column, it specified how the data is accessed.
Operations
- Index and Table access Types :
eq_ref, const: performs a B-tree traversal to find one row, and fetch additional columns from the table if needed. -> the database use this if a primary key or unique constrain ensures that the search criteria will match no more than one entry.ref, range: Performs a B-tree traversal, walks through the leaf nodes to find all matching index entries and fetches additional columns from the primary table store if neededindex: Reads the entire index - all rows -in the index order.ALL: reads the entire table - all rows and columns - as stored on the disk.- Using Index (in the EXTRA column ): when the extra column shows "Using Index", it means that the table is not accessed because the index has all the required data. (However, if clustered index is used, (e.g. the PRIMARY index when using InnoDB), "Using Index doesn't appear in the Extra column, although it is technically an Index-Only Scan")
- Sorting and Grouping
- Using filesort(in the "Extra" column): indicate an explicit sort operation - no matter where the sort takes place (memory or disk) -> it uses large amounts of memory to materialized the intermediate result.
- Top_N Queries
- Implicit: no "using filesort" in the "Extra" column: A MySQL execution plan does not show a top-N query explicitly. If you are using the
limitsyntax and don’t see “using filesort” in the extra column, it is executed in a pipelined manner
- Implicit: no "using filesort" in the "Extra" column: A MySQL execution plan does not show a top-N query explicitly. If you are using the
Distinguishing Access and Filter-predicates
Three different ways to evaluate where clauses :
-
Access predicate ("key_len", "ref" columns): the access predicated express the start and stop condition of the leaf node traversal
-
Index filter predicate("Using index condition", since MySQL 5.6): Index filter predicates are applied during the leaf node traversal only. They do not contribute to the start and stop conditions and do not narrow the scanned range.
-
Table level filter predicate (“Using where” in the “Extra” column): Predicates on columns which are not part of the index are evaluated on the table level. For that to happen, the database must load the row from the table first.
-
MySQL execution plans do not show which predicate types are used for each condition—they just list the predicate types in use.In the following example, the entire
whereclause is used as access predicate:```sql CREATE TABLE demo ( id1 NUMERIC , id2 NUMERIC , id3 NUMERIC , val NUMERIC) INSERT INTO demo VALUES (1,1,1,1) INSERT INTO demo VALUES (2,2,2,2) CREATE INDEX demo_idx ON demo (id1, id2, id3) EXPLAIN SELECT * FROM demo WHERE id1=1 AND id2=1
```
bash +------+----------+---------+-------------+------+-------+ | type | key | key_len | ref | rows | Extra | +------+----------+---------+-------------+------+-------+ | ref | demo_idx | 12 | const,const | 1 | | +------+----------+---------+-------------+------+-------+There is no “Using where” or “Using index condition” shown in the “Extra” column. The index is, however, used (
type=ref, key=demo_idx) so you can assume that the entirewhereclause qualifies as access predicate. -
Please also note that the
refcolumn indicates that two columns are used from the index (both are query constants in this example). Another way to confirm which part of the index is used is thekey_lenvalue: It shows that the query uses the first 12 bytes of the index definition. To map this to column names, you “just” need to know how much storage space each column needs (see “Data Type Storage Requirements” in the MySQL documentation). In absence of aNOT NULLconstraint, MySQL needs an extra byte for each column. After all, eachNUMERICcolumn needs 6 bytes in the example. Therefore, the key length of 12 confirms that the first two index columns are used as access predicates.When filtering with the
ID3column (instead of theID2)MySQL 5.6 and later use an index filter predicate (“Using index condition”):sql EXPLAIN SELECT * FROM demo WHERE id1=1 AND id3=1```bash +------+----------+---------+-------+------+-----------------------+ | type | key | key_len | ref | rows | Extra | +------+----------+---------+-------+------+-----------------------+ | ref | demo_idx | 6 | const | 1 | Using index condition | +------+----------+---------+-------+------+-----------------------+
```
In this case, the
ken_len=6and only oneconstin therefcolumn means only one index column is used as access predicate.Previous versions of MySQL used a table level filter predicate for this query—identified by “Using where” in the “Extra” column:
bash +------+----------+---------+-------+------+-------------+ | type | key | key_len | ref | rows | Extra | +------+----------+---------+-------+------+-------------+ | ref | demo_idx | 6 | const | 1 | Using where | +------+----------+---------+-------+------+-------------+